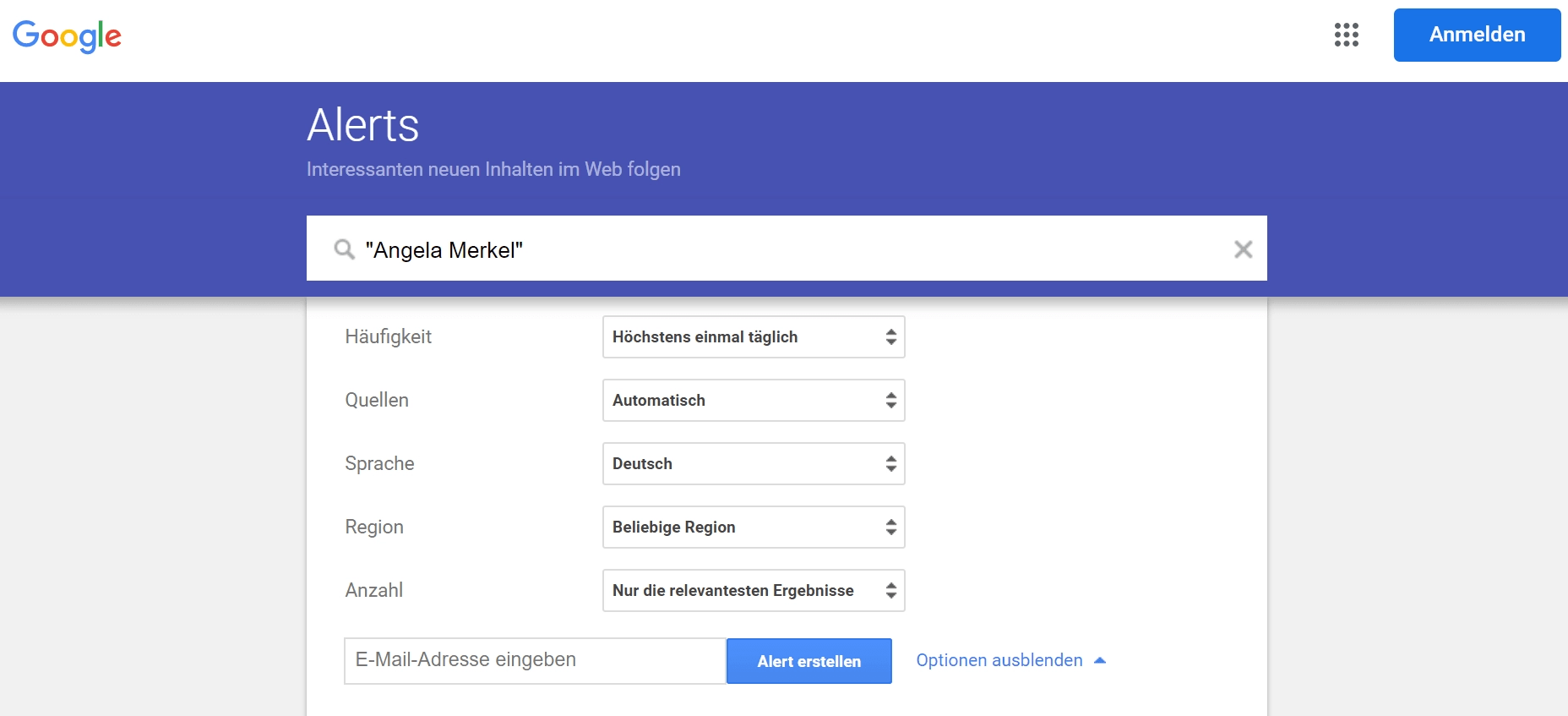
wie du wahrscheinlich weißt, bin ich seit 13+ Jahren als Content-Creator und fachlicher Inputgeber in den Bereichen digitale Transformation, Innovation und Technologie aktiv.
Auf verschiedensten Plattformen, in verschiedenen Formaten, zusammen mit verschiedenen Partnern. (Wenn du einen kurzen Re-Fresher dazu brauchst, google mich am besten kurz und schau dir Artikel, Videos und Podcasts an 😉
Seit dem letzten Jahr bin ich allerdings weit weniger aktiv auf meinem Blog und sonstigen Kanälen, auf denen man mich für gewöhnlich findet.
Dieser Artikel erklärt kurz, warum, wie es planmäßig weitergeht und wo man mich jetzt findet.
Legen wir los!
Warum ich aktuell weniger (bis gar nicht) aktiv auf diesem Blog, meinem Newsletter, etc. bin
In den letzten Monaten habe ich eine neue Rolle übernommen, die mich sehr in Anspruch nimmt. Ich bin jetzt der Leitdozent und Taktgeber beim Digitalen Institut und leite dort unsere Kurse und Seminare.
Außerdem bin ich für die Content-Strategie, Suchmaschinenoptimierung, Produktentwicklung, Vision und Mission und einiges mehr verantwortlich. Ich mache das zwar nicht allein, aber es bündelt schon viele Ressourcen insgesamt auf sich.
Die Kirsche auf der Torte ist unser neuestes Projekt, die Unterstützung von Online-Unternehmern beim Einsatz von generativen Tools. Mehr dazu in unseren ChatGPT-Seminaren.
Diese Rolle erfordert – wie du dir sicher vorstellen kannst – viel Zeit und Energie von mir.
Deshalb habe ich weniger Zeit, um Artikel für diesen und andere Blogs zu schreiben, Infografiken und Tools zu bauen etc.
Meine neue Rolle als Hauptdozent beim Digitalen Institut
Ich bin sehr stolz darauf, Teil des Digitalen Instituts sein zu dürfen und meine Erfahrung und mein Wissen nach meinen Vorstellungen weiterzugeben zu können.
Ich leite wie gesagt nicht nur unsere Kurse und Seminare, sondern gebe zusätzlich vollumfänglich mein bestes, jeden unserer Teilnehmer bestmöglich auf seine bestmögliche Karriere vorzubereiten.
Aktuell produziere und tobe ich mich vor allem mit Online-Content aus, auf den ich seit Jahren bereits Lust habe.
Das heißt, du findest mich jetzt vor allem in Medienformaten, bei denen ich bisher nur zu Gast sein durfte:
Wo man mich jetzt vor allem findet: Die Kanäle des Digitalen Instituts
Obwohl ich weniger aktiv auf diesem Blog bin, bin ich immer noch aktiv in den sozialen Medien und auf anderen Plattformen. Genaugenommen sogar aktiver als je zuvor!
Hier die Übersicht zu meinen Outputs, wenn du stets Up to Date bleiben möchtest:
Der YouTube-Channel des Digitalen Instituts (Hier beantworte ich vor allem immer wieder gestellte Fragen und erkläre technologische Sachverhalte und Zusammenhänge)
Der Blog des Digitalen Instituts (Hier schreiben vor allem ich, aber auch der Rest des Teams vor allem Inhalte zu den in unseren Videos behandelten Themen)
Die einfachste Möglichkeit, all das stets einfach und sofort direkt in dein Postfach zu bekommen, ist durch ein YouTube-Abo.
Hier stelle ich das Digitale Institut und meine Rolle darin auch in Videoform direkt vor: (Dann musst du nicht alles lesen und so viele Links anklicken 😉
Fazit: Das Digitale Institut und Ich
Danke an alle, die mich hier auf meinem Blog und meinem Newsletter so lange begleitet haben. Ich hoffe, dass ich in der Vergangenheit einige wertvolle Einblicke und Anregungen geben konnte. Ich gebe weiterhin mein Bestes, um jetzt auf anderen Plattformen und unter anderer Flagge kontinuierlich die besten Inhalte, zu denen ich fähig bin, zu liefern!
Ich freue mich darauf, dich und euch ggf. in meinen Kursen und Seminaren beim Digitalen Institut willkommen zu heißen.
Es ist der Sommer des Jahres 1769, in welchem der bald als „King Cotton“ betitelte Baumwoll-Pionier Richard Arkwright sein Patent für eine neuartige Spinnmaschine erhält.
Das Besondere an dieser Spinnmaschine: Sie kommt vollständig ohne menschliches Eingreifen aus. Diese Erfindung, diese Innovation, wie in diesem Artikel entpuppt sich als eine der folgenschwersten der Menschheitsgeschichte. Denn danach erfindet er nicht nur die moderne Fabrik, sondern verändert mit dieser Innovation absolut alles. Vom Fahrzeug zu Kleidung und Maschinenteilen bis hin zu Bauwerken.
Die Idee dieser Spinnmaschine läutet die industrielle Revolution ein. Es ist eine der wegweisensten Innovationen seit der neolithischen Revolution, dem Übergang vom Jäger und Sammler zum sesshaften Bauern. (Mehr zu Auswirkungen und Kontext dieser Erfindung findest du in diesem Artikel)
Dass diese Erfindung eine Innovation ist, welche Ihresgleichen sucht, ist keine große Frage. Doch sie wirft so konkret wie kaum eine andere, weitere zentrale Fragen auf:
Was bedeutet Innovation überhaupt?
Was genau ist Innovation?
Woran erkenne ich eine?
Und wie erschaffe ich selbst Innovation(en)?
Schauen wir es uns systematisch an:
Was bedeutet Innovation?
Innovation bedeutet in kurz, mit den momentanen Mitteln die bestmögliche Lösung für ein Problem zu schaffen.
Es gibt dabei verschiedene Strategien, die besten zwei sind
1. Löse dein eigenes Problem, dann hilf anderen damit (wie der Jimmy Wales, der Gründer von Wikipedia so schön gesagt hat: Mit dieser Methode ist dein garantierter Zielmarkt 1)
2. Löse ein Problem für eine einzige Person und mache diese damit glücklich. So richtig glücklich. Zum „Superfan“. Dann wiederhole dies für 10 Personen. Für 100. Und dann für 1.000. Das ist die unglaublich wirksame und zeitlose Strategie hinter den „1.000 True Fans“ von Kevin Kelly.
Innovation bedeutet einfach anfangen und Ergebnisse liefern, welche in der echten Welt etwas bewirken.
If it’s new and useful, what problem is it solving?
Why has the audience rejected similar innovations in the past?
One day, this market will change. What will cause that change to happen?
Was ist eine Innovation?
Innovation bedeutet besser machen. Probleme lösen. Menschen glücklich machen mit Lösungen, die es so noch nicht zuvor gab:
Einfacher
Komfortabler
Günstiger
Hübscher
Umweltfreundlicher
Leichter
Etc.
Nehmen wir als Autoland das Beispiel Auto:
Auto + umweltfreundlicher = Elektroauto
Auto + komfortabler = Autonomes Fahrzeug
Auto + hübscher = Tesla
etc.
Dieser Artikel ist eine Innovation, wenn er das Problem (besser als bisherige Alternativen) löst, zu verstehen was Innovationen sind.
Innovationen sind die Puzzlestücke des Fortschritts.
Was ist Innovation also?
Lass es uns tun, statt es zu besprechen:
1. Überlege dir 20 Probleme, welche dich seit langem stören.
2. Bewerte diese Probleme auf einer Skala 1 (nervt nur leicht) bis 10 (Lösung wäre lebensverändernd)
3. Überlege dir für das Problem mit dem höchsten Wert 20 Lösungen
4. Mache dir eine Skizze für die deinem Bauchgefühl nach beste Lösung.
Wenn du diese Skizze nun umsetzt, hast du erfolgreich Innovation begangen. (Egal ob in Form einer Maschine, App, Webseite, Code, Sätzen oder whatever)
Ganz praktisch kann Innovation zum Beispiel so ablaufen:
Du möchtest gern einen Song bauen, der Chart-fähig ist.
Du kannst nur leider weder Liedtexte schreiben, noch Instrumente spielen, noch Musikvideos produzieren etc.
Wie löst du dieses Problem? Eine Antwort kannst du dir hier anschauen und anhören:
Das ist Innovation.
Innovation = Menschen auf bisher noch nicht bekannten / genutzten Wegen helfen.
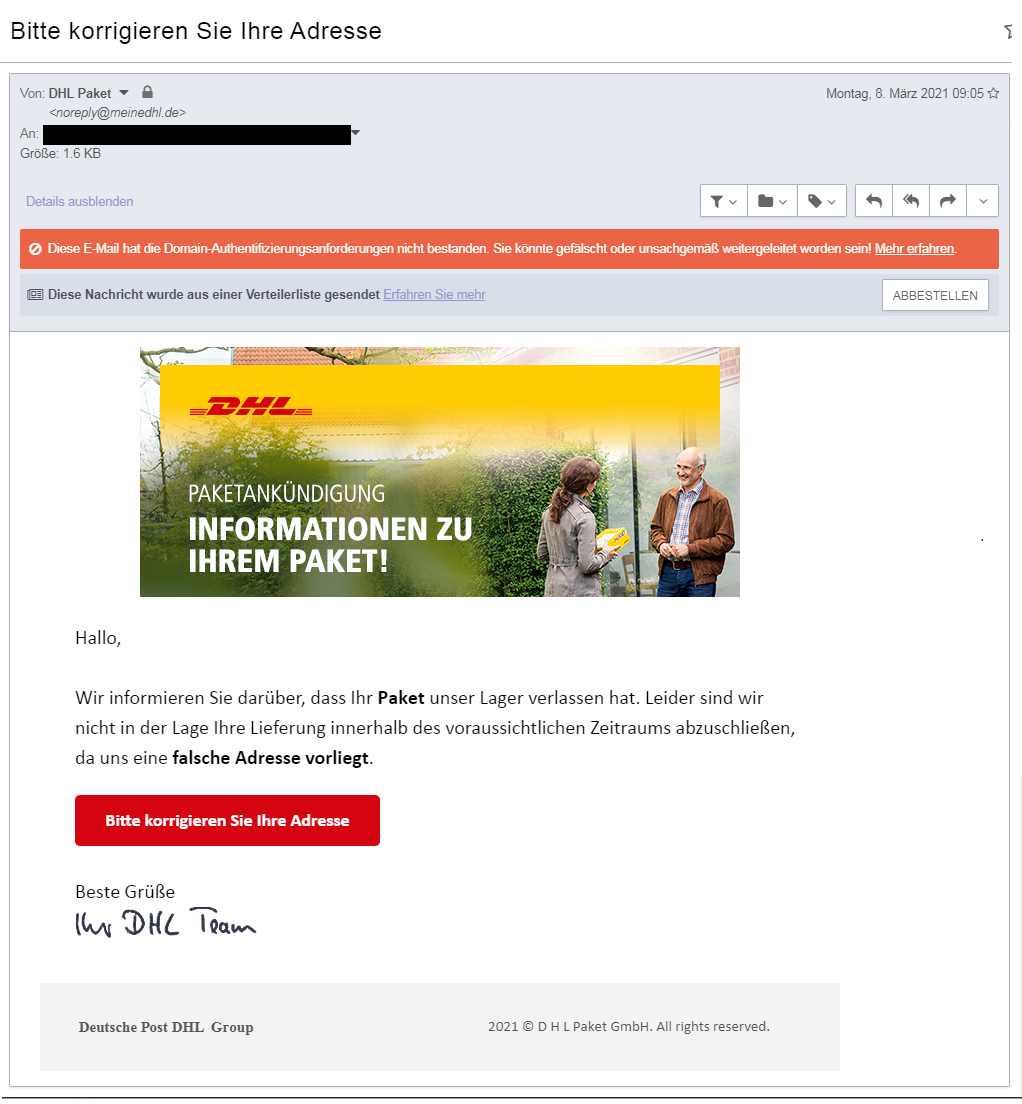
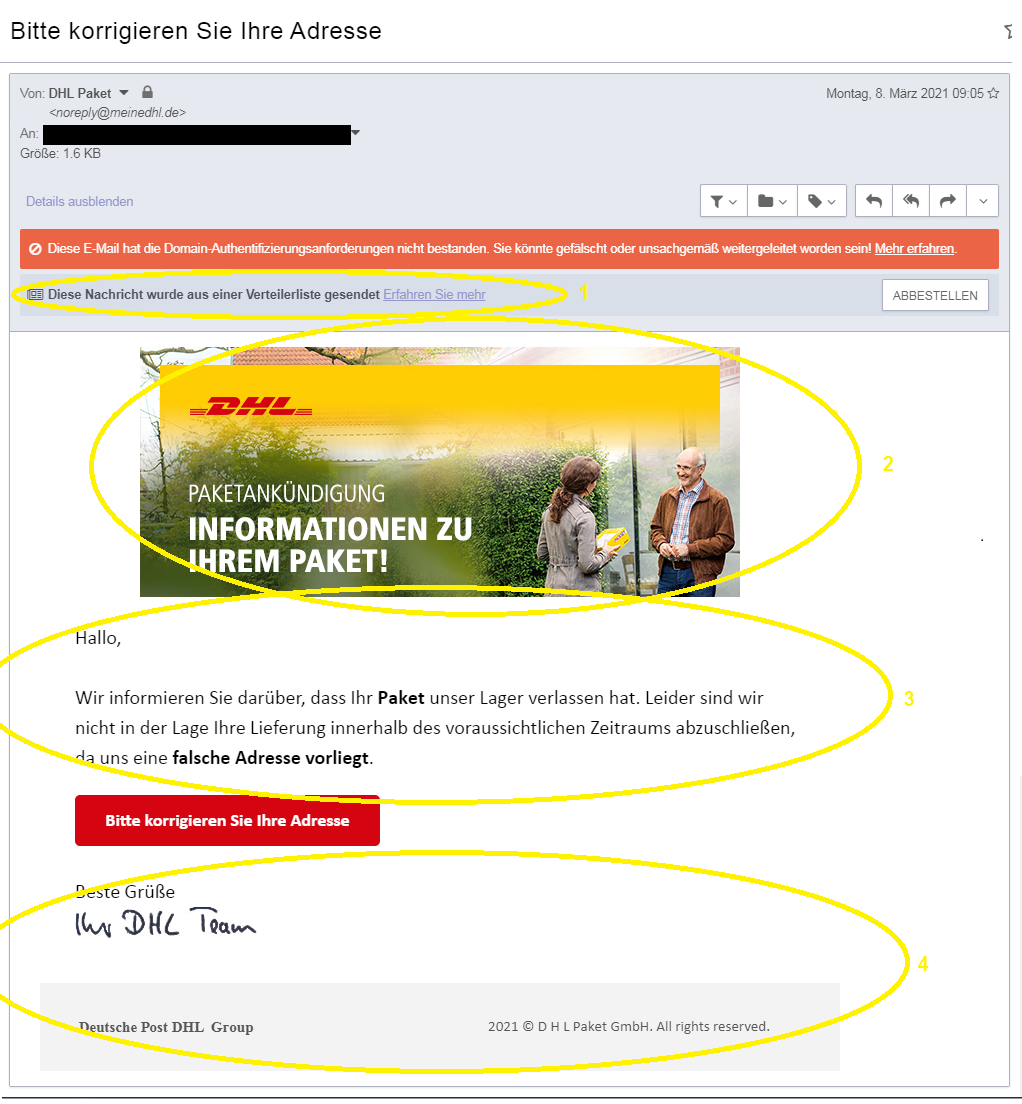
In diesem Artikel zeige ich dir Schritt für Schritt, EXAKT wie du sicher im Internet unterwegs bist.
Ich zeige dir dabei einen Grad an Sicherheit, den selbst einige Experten nicht aufweisen und der dich selbst vor komplexeren Angriffen schützt:
Wenn du also sicher gegen betrügerische Links, gehackte Accounts, gestohlene Daten und ausgelesene Mail-Verläufe sein möchtest, bist du hier genau richtig.
Legen wir los:
Schritt 1:
Hyperlinks lesen
Kostenlose Anleitungen zum sofortigen Einsatz der hier genannten Tools und Taktiken sowie Updates kannst du dir hier kostenlos herunterladen:
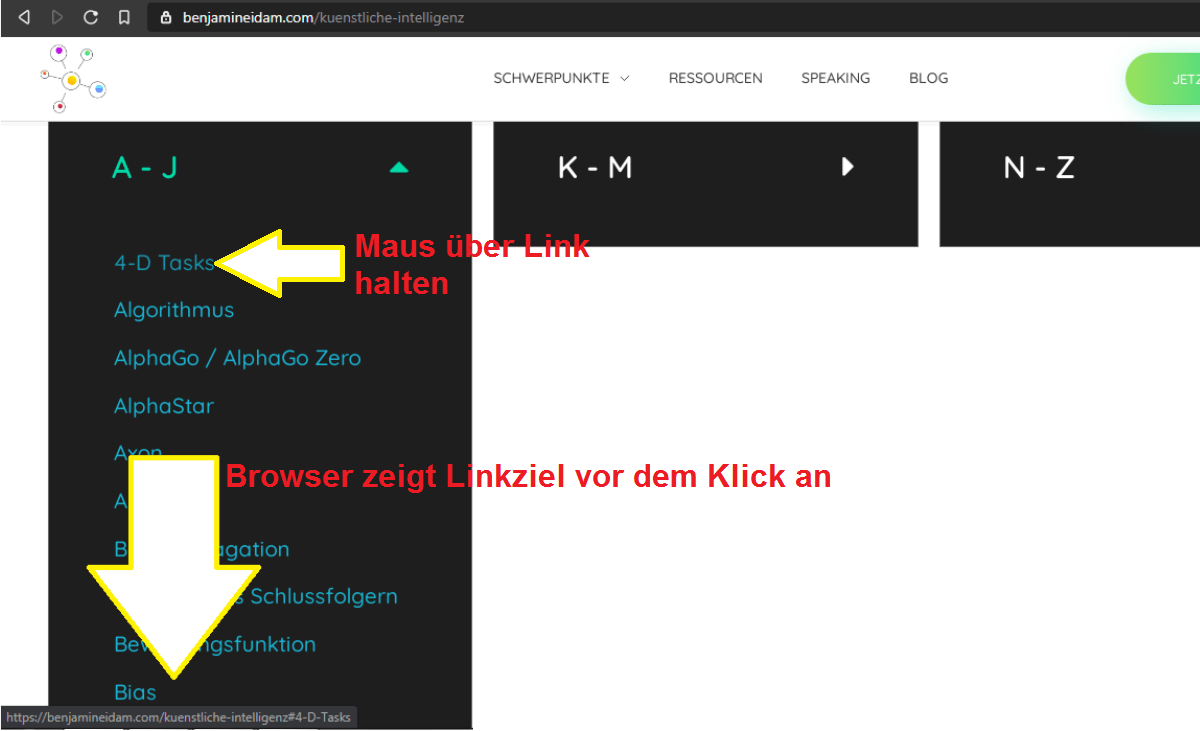
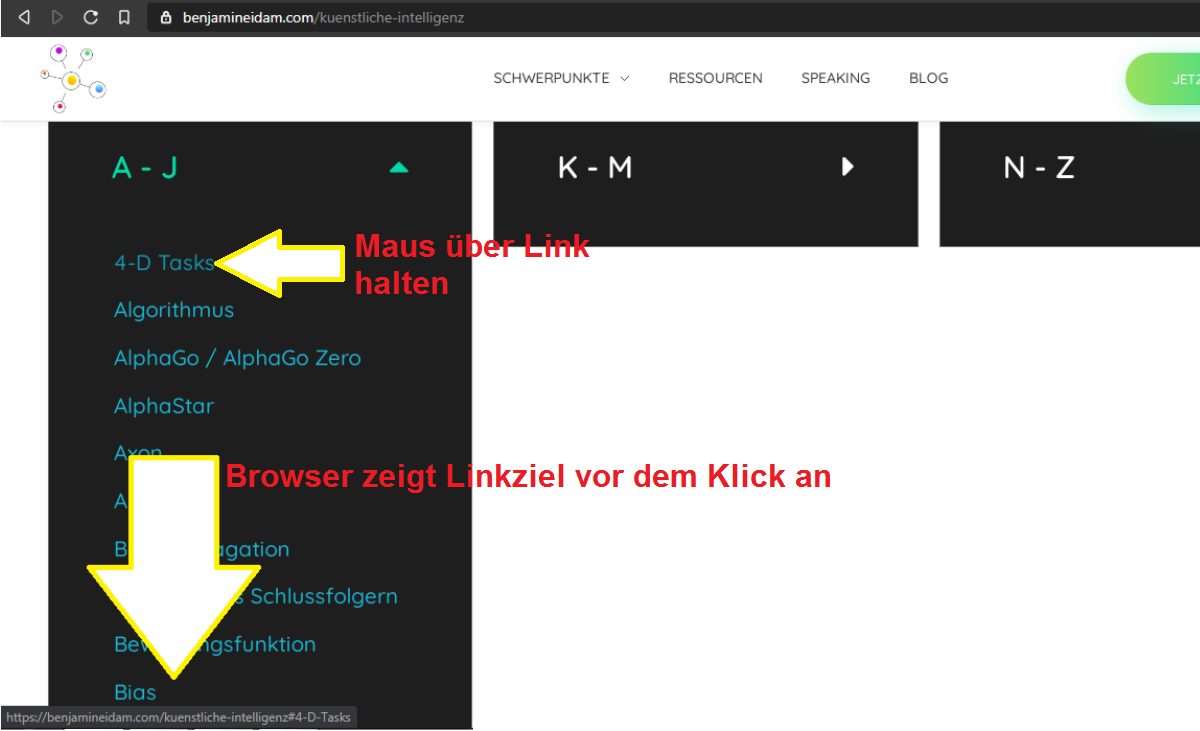
Hyperlinks, Verlinkungen, Backlinks oder schlicht und einfach Links sind eines der zentralen technischen Konzepte des Internets.
Sie sind dabei nichts anderes als eine Brücke zwischen Webseite A und Webseite B.
Doch ähnlich wie bei der Fahrt in einen dunklen Tunnel musst du vor dem “Betreten” eines Hyperlinks sicher sein, wohin dich dieser genau bringt.
Der Beginn dieser Sicherheitsmaßnahme ist also
Teil 1: Verstehen einer Hyperlink-Struktur
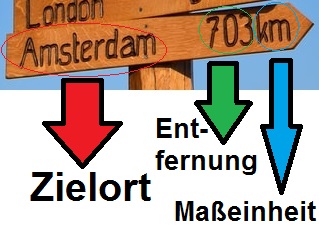
Schauen wir uns also an, wie ein Schild in der echten Welt von A nach B navigiert:
Bevor du auf eine Straße einbiegst, schaust du dir an, wohin diese dich führt. Schließlich möchtest du nicht nach Kairo, wenn dein Ziel Berlin ist.
Bildquelle und weitere Informationen: https://sketchplanations.com/the-swiss-cheese-model
Irgendwann hast du gelernt,
Den Zielort
Die Entfernung
Die Maßeinheit
einzuschätzen, intuitiv zu erfassen und adäquat zu handeln. Gleiches gilt es jetzt mit Hyperlinks zu machen.
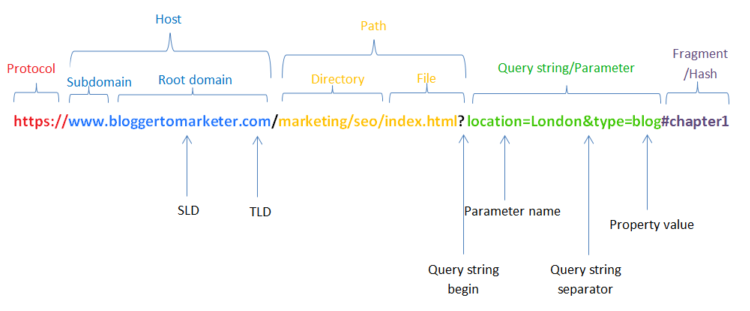
Im Internet nimmt der Hyperlink unter anderem die Rolle des Straßenschildes ein:
Bildquelle und weitere Informationen: https://bloggertomarketer.com/url-structure-for-seo/
Was und zu Schritt 2 führt, dem
Teil 2: Auslesen der Hyperlink-Struktur
In einem Hyperlink interessiert dich in ~80% – 99% der Zeit:
Die Root Domain, z.B. google.com
Der Pfad, z.B. /search/waffenschmuggelbetrug
Ergänzend ggf.:
Das verwendete Protokoll, also http oder httpS
Der jeweilige Parameter des Links (Daraus kannst du zum Beispiel Trackingversuche ableiten)
Der Rest ist Schritt 3:
Teil 3: Routine im Link lesen
Du weißt jetzt worauf du achten musst. Von hier an ist es nichts als Gewohnheit. Bei jedem Link den du klickst, bevor du ihn klickst. Bei jedem Link in einer Online-Zeitung, einem Blog etc. Binnen weniger Tage wird es zu deiner zweiten Natur und von dort aus bist du sicher gegen eine Reihe von Angriffen und Fehltritten.
Fangen wir direkt mit einigen einfachen Beispielen an. Schwierigere Beispiele hast du jeden Tag im Internet auf jeder sich bietenden Webseite:
diesisteinespaßseite.org/falle/fuer-anfaenger/faellst-du-darauf-rein (Name der Webseite, Abschnitt Falle, Unterkategorie “für Anfänger”, Kapitel “Fällst du auf diese einfache Falle rein?)
https://www.zeit.de/politik/deutschland/2021-07/rechtes-phantom-fdp-tom-rohrboeck-berater-netzwerk (Webseite, Abschnitt Politik, Thema Deutschland, im Juli 2021, mit dem Thema Tom Rohrböck und sein Berater-Netzwerk)
Wenn du in einer Bibliothek ein Buch finden kannst, kannst du auch Hyperlinks auslesen. Viel Erfolg!
Schritt 2:
Passwortsafes nutzen / KeePass
Passwortsafes sind, wie der Name vermuten lässt, “sichere Räume” für deine Passwörter.
Gibt es dementsprechend auch unsichere Räume / Aufbewahrungsorte für Passwörter? Ja! Etwa 99% aller Alternativen zu Passwortsafes.
Also Ideen wie Passwörter auf Zettel oder in Bücher zu schreiben. Passwörter so einfach zu machen, dass man sie sich einfach merken und so im Kopf behalten kann.
Also zum Beispiel “Kuchen” als Passwort zu nutzen. (Blödeste Idee von allen) Oder Passwörter in einem Dokument auf dem Desktop zu speichern. Wenn das unverschlüsselt und entsprechend benannt geschieht, hat man sich die goldene Zielscheibe als besonders attraktives Hacking-Ziel verdient.
Bildquelle und weitere Informationen: https://joinup.ec.europa.eu/sites/default/files/inline-files/DLV%20WP6%20-01-%20KeePass%20Code%20Review%20Results%20Report_published.pdf
Es gibt noch eine Reihe weiterer guter Passwortsafes auf dem Markt, jedoch keinen so multidimensional sicheren wie KeePass. Allein schon, weil KeePass der einzige relevante OpenSource-Passwortmanager auf dem Markt ist.
KeePass ist definitiv nicht der hübscheste oder intuitivste Passwortsafe des Internets. Aber dafür weiß man bei ihm garantiert, woran man ist und er ist sehr knack-resistent.
Machen wir also weiter mit KeePass:
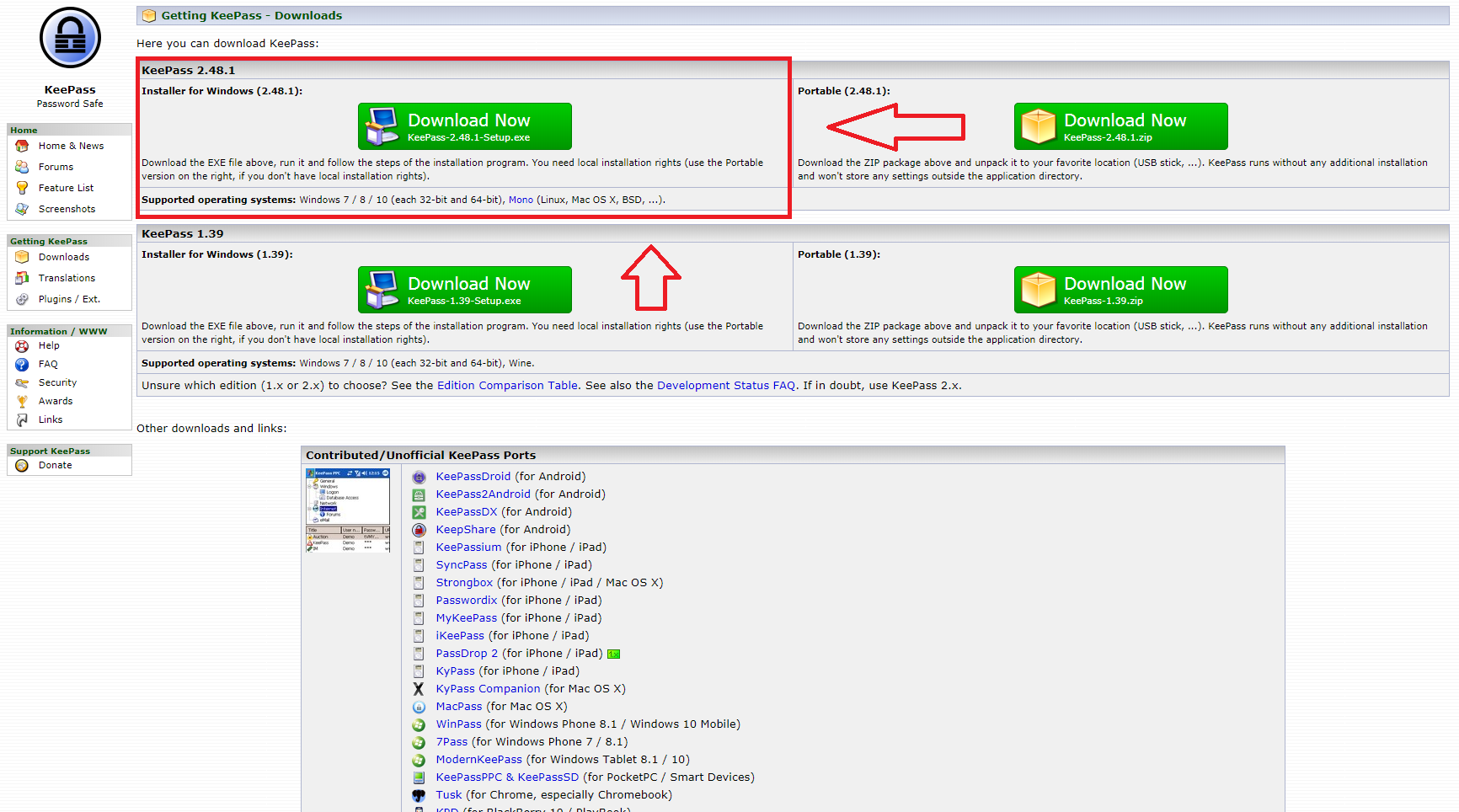
Teil 2: Passwortsafe herunterladen und installieren
Dieser Schritt ist recht selbsterklärend:
Du öffnest https://keepass.info/download.html mit einem neuen Tab in deinem Browser. (Was nach einem Klick allein passiert, ich habe mich für dich schon darum gekümmert)
Du folgst der “oben Links-Regel” du lädst die Version, die jetzt gerade oben links steht herunter, indem du auf den dicken grünen Button klickst.
Du installierst KeePass so wie und wo auf deinem Computer du es gernhaben möchtest. Optional aber hilfreich: Setze dir eine Verknüpfung auf dem Desktop / Taskleiste / Startleiste / woauchimmer. So kannst du jederzeit mit einem Klick auf KeePass zugreifen. Erleichtert den digitalen Alltag ungemein.
Wenn du einen neuen Passwortsafe anlegst ist es wichtig, dass du ein sicheres Passwort für diesen Passwortsafe nutzt. Es ist das einzige, das du dir merken musst, den Rest übernimmt von hier an KeePass.
Und damit weiter im Text:
Teil 3: Passwortsafe einrichten
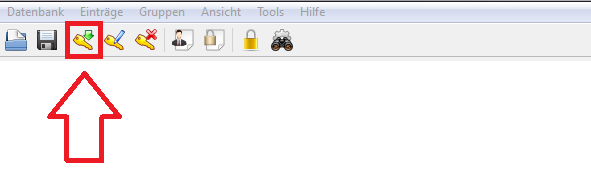
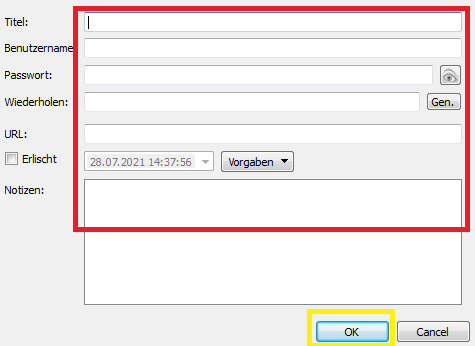
Nachdem dein Computer zum zu Hause von KeePass geworden ist, gilt es dieses nun einzurichten. Heißt: Du fügst neue “Karten” hinzu und bestückst diese mit den jeweiligen Zugangsdaten. Also:
1. Auf den Schlüssel mit dem grünen Pfeil klicken.
2. Felder ausfüllen und am Ende auf “Ok” klicken.
Hinweise: Der Titel ist a) die Beschreibung, die du später in der Vorschau angezeigt bekommst, es ergibt hier also Sinn, kurz und präzise zu formulieren. Also z. B. bei Facebook einfach als Titel “Facebook” zu schreiben, statt “Social Media Netzwerk mit blauem F als Logo”. Und b) Kannst du dir deine Einträge alphabetisch ordnen lassen, um eine bessere Übersicht zu erhalten. Hier hat jeder andere Vorlieben, aber wenn du zum Beispiel Zugriffsdaten deines iPhones in KeePass speicherst, ergibt es Sinn, diese unter “iPhone” oder “Apple” zu speichern, statt unter “Smartphone”.
3. Prozess mit jedem wichtigen Onlineservice wiederholen.
Solltest du kein sicheres Passwort für einen Service haben, klickst du einfach auf den kleinen “Gen.”- Button. Dieser erstellt dir automatisch so viele so sichere Passwörter wie du möchtest.
Teil 4: Passwortsafe zum neuen Standard in der Computerbenutzung machen
Herzlichen Glückwunsch! Deine Online-Aktivitäten sind von nun an um Welten sicherer! Fehlt nur noch ein letzter Schritt:
Nachdem du jetzt alle wichtigen Daten an einem Platz hast, ergibt es Sinn, stets als erste Handlung nach dem Hochfahren des Rechners KeePass zu öffnen. Das wirst du ohnehin schnell brauchen, da du ohne nirgends mehr reinkommst. Doch so garantierst du dir das der Passwortsafe zur Routine wird.
Noch einfacher geht es, wenn du dir das Symbol von KeePass zentral und gut sichtbar auf dem Desktop und / oder der Taskleiste / einem anderen jederzeit gut für dich sichtbaren Ort auf deinem Rechner platziert.
Wenn du es noch detaillierter brauchst, die Universität Münster hat eine noch feingliedrigere Anleitung zum Einsatz von KeePass geschrieben. Du findest diese hier.
Und damit weiter in unserem Rundgang durch den Tresor-Laden und auf zu Datensafes:
Schritt 3:
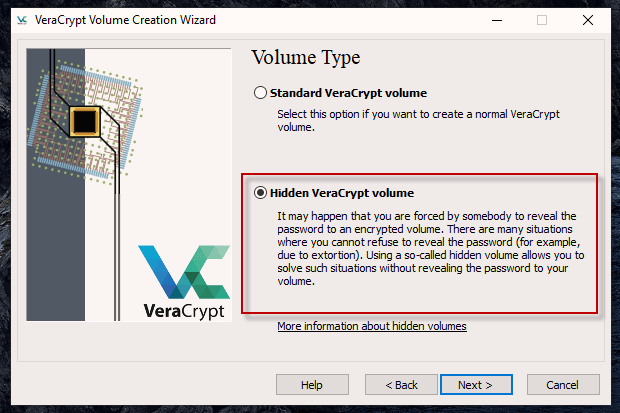
Datensafes nutzen / VeraCrypt
Sichere und sicher verwahrte Passwörter haben wir. Fehlen noch die Daten, welche durch sichere Passwörter “abgeschlossen” werden.
Oder anders formuliert: Wenn Passwörter deine Türschlösser sind, sind Datensafes die Wände, welche deine (Daten)Schätze sicher bewahren.
Dabei gehen wir sehr ähnlich wie in Schritt 2 vor, nur mit einem anderen Programm:
Teil 1: Für einen Datensafe entscheiden
Auch hier gilt: Nach Möglichkeit möchtest du ein Programm, welches
Open Source basiert und
mehrere, hochqualitative und im Bestfall voneinander unabhängige Audits hat, welche so kurz zurückliegen wie möglich. (Ein Audit ist ein oftmals unangekündigter / unabgesprochener Qualitätscheck der jeweiligen Lösung)
Die Kurzform: Es gibt keinen besseren Allround-Startpunkt zur Datensicherung als VeraCrypt.
Bildquelle und weitere Informationen: https://www.bsi.bund.de/DE/Service-Navi/Publikationen/Studien/VeraCrypt/veracrypt.html
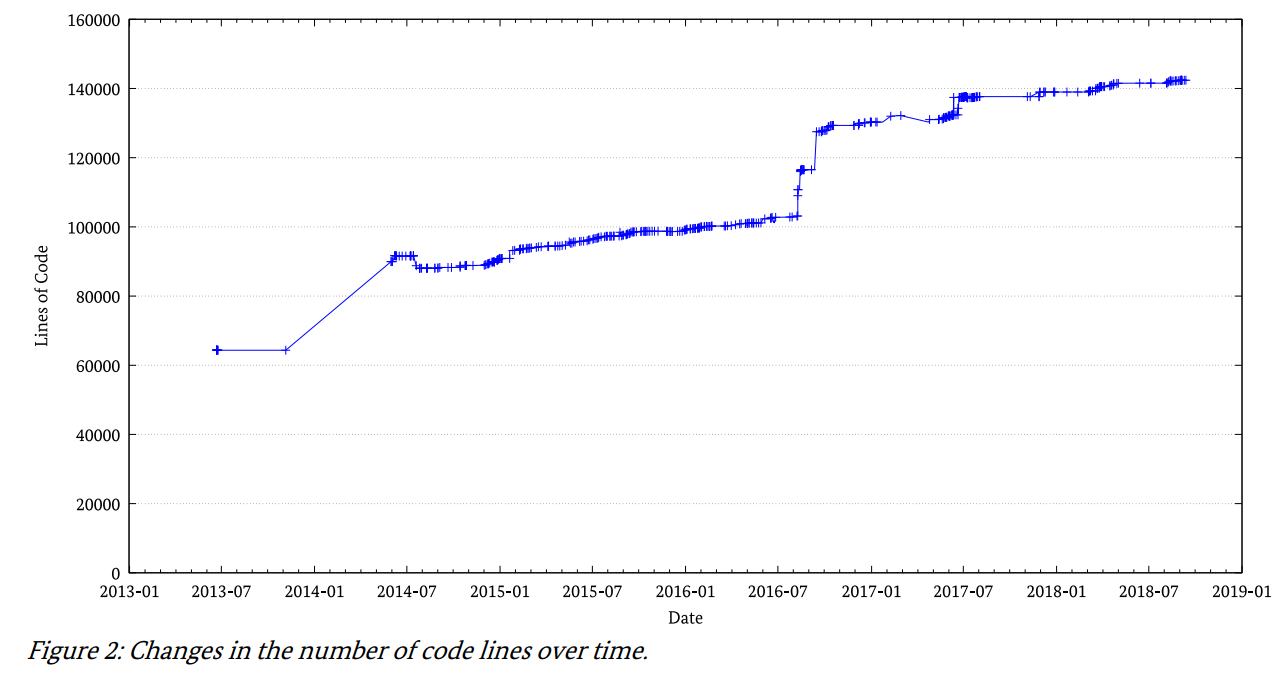
Ein großer Vorteil von Open-Source-Software ist der, dass jederzeit von jedem kundigen Updates am Code vorgenommen werden können. Was sich, wie hier zu sehen, messbar auswirkt. (Dass diese Änderungen auch tatsächlich sinnvoll sind, findest du in der Bildquelle ausführlich begründet: https://www.bsi.bund.de/DE/Service-Navi/Publikationen/Studien/VeraCrypt/veracrypt.html)
Machen wir damit also weiter:
Teil 2: Datensafe herunterladen
Dieser Abschnitt ist noch leichter als der bei den Passwortsafes. Einfach
Die aktuelle Version für dein System herunterladen
Installieren
Hier kannst du nichts falsch machen, deshalb direkt weiter zum nächsten Part, der Einrichtung von VeraCrypt:
Teil 3: Datensafe einrichten
Zur Einrichtung findest du eine hervorragende, bebilderte Schritt-für-Schritt-Anleitung hier.
Folge dieser am besten und komme jederzeit wieder zu dieser zurück, wenn du Hilfe brauchst. (Und/oder frag mich einfach)
Teil 4: Einsatz des Datensafes zum Alltag machen
Auch hier gilt wieder: Speichere dir das Programm bzw. die / eine Verknüpfung zu diesem Programm so einfach wie möglich nutzbar und so schnell wie möglich klickbar ab.
Also NICHT in verschachtelten Unterordnern, NICHT im Installationsordner lassen und NICHT in Reihe 14 Spalte 11 auf einem vollkommen zu gekleisterten Desktop.
Stattdessen:
Als erstes Symbol oben links in der Ecke auf dem Desktop geht.
Als eines von maximal 5 Schnellstart-Symbolen der Taskleiste funktioniert.
Als eines von maximal 3 an die Startleiste angeheftetes Symbol geht es.
Das obige Bild zeigt es hervorragend: Nur vier Symbole auf dem Desktop und eines davon VeraCrypt klappt. Nur sieben Symbole angeheftet an die Taskleiste und eines davon Veracrypt klappt auch, wobei hier bereits etwas eingespart werden kann. Je leichter und offensichtlicher, desto besser.
Kurz: Jede Lösung die für dich sofort offensichtlich und kinderleicht zu bedienen ist, klappt.
Schritt 4:
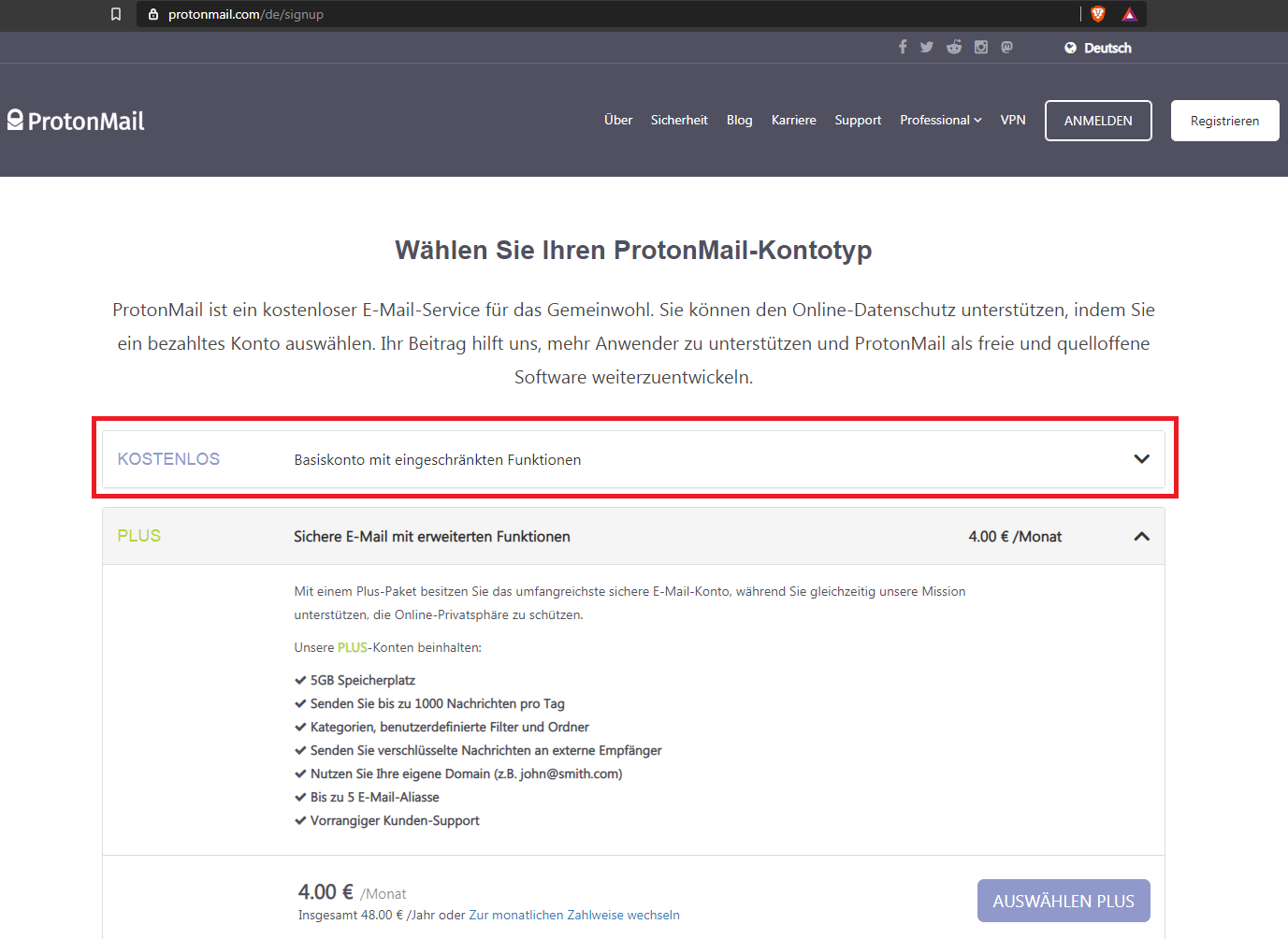
Sichere(n) Mailanbieter nutzen / Protonmail
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
Und damit sind wir beim letzten Schritt dieser „mehr Sicherheit im Internet in 4 einfachen Schritten“-Anleitung. Gehen wir wie immer systematisch vor:
Teil 1: Für einen Mailanbieter entscheiden
Wenn du den Artikel bis hier hin chronologisch gelesen hast, kennst du diesen Teil. Bevor du dich auf Jahre und Jahrzehnte mit einem Stück Software verbandelst, solltest du sichergehen, dass es das richtige Stück Software für dich ist.
Die Kurzform: Bei Protonmail arbeiten einige der schlauesten Köpfe dieser Erde, Wissenschaftler des CERN an einem Programm, welches unter schweizer und EU-Datenrecht steht, in einem Atomschutzbunker gehostet ist und so sicher ist, wie möglich. Einfach nur und auch weil Wissenschaftler gute Herausforderungen lieben.
Mehr dazu in diesem spannenden TED-Talk:
Jetzt wo wir auf einer Wellenlänge sind, geht es ans Umsetzen:
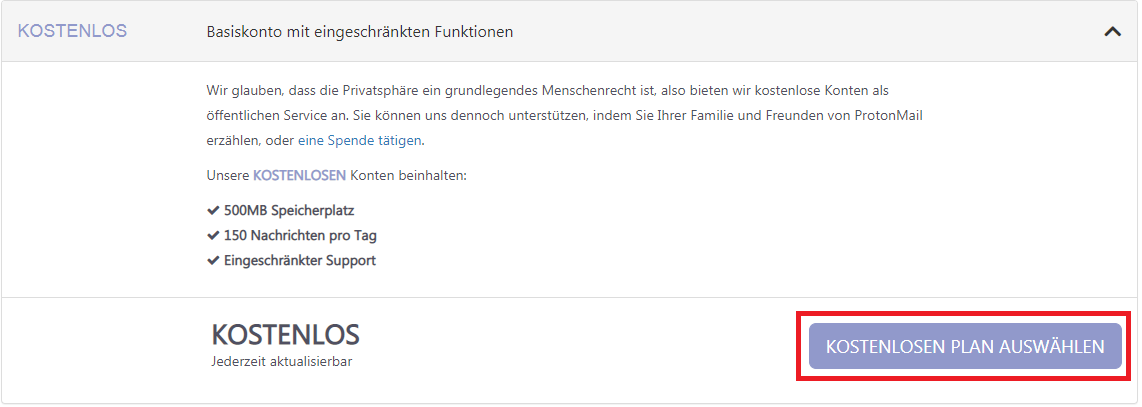
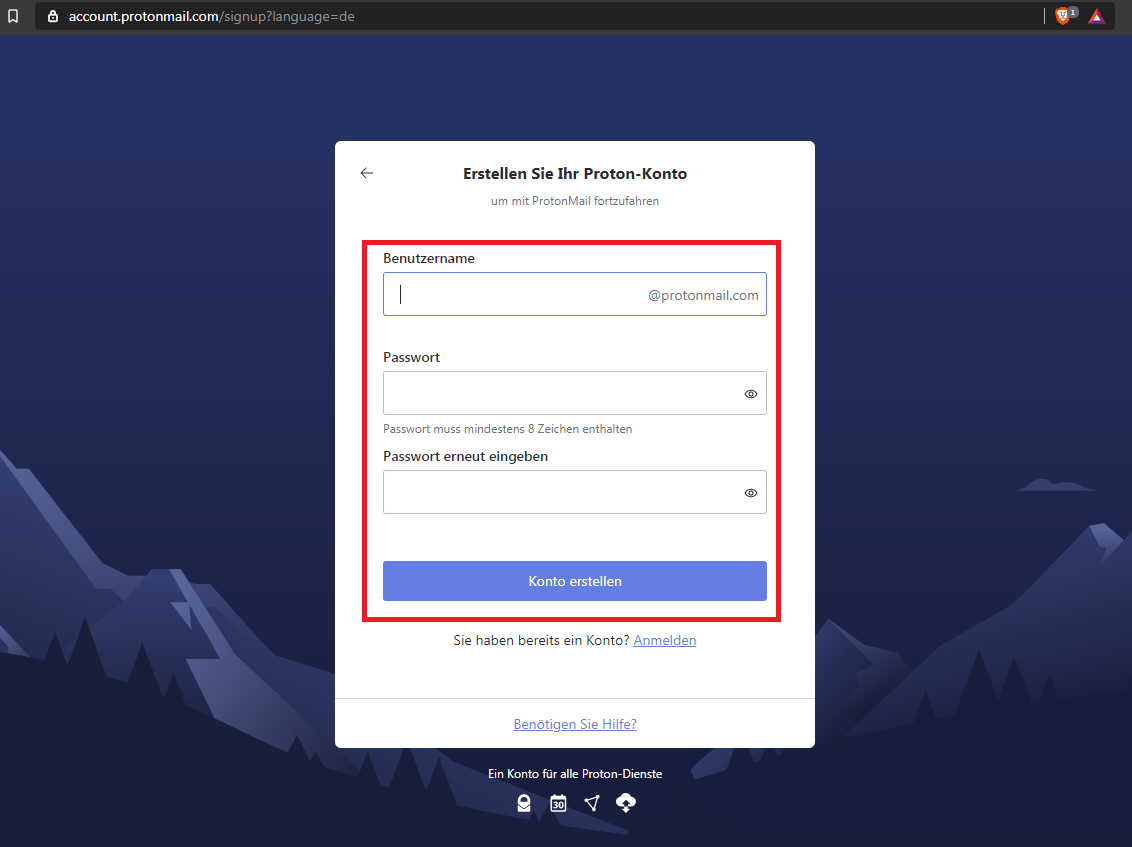
Teil 2: Account anlegen und einrichten
Dieser Schritt funktioniert wie bei jedem anderen Mail-Anbieter:
Mailadresse aussuchen
Passwort aussuchen
Loslegen
Oder, in rascher Bildfolge zum mitklicken:
Schritt 1
Schritt 2
Schritt 3
Schritt 4
Wenn du noch mehr zum Anmelde-Prozess und dem Einsatz von Protonmail wissen möchtest, dieses Video zeigt einen guten Einstieg in die Welt von Protonmail:
Teil 3: Account optimal nutzen
Wie jeder hochentwickelte Mailing-Service dieser Tage hat auch Protonmail ein paar „Special-Features“ unter der Haube. Mein liebstes davon ist „pm.me„. Unter dieser extrem kurzen URL kommst du ohne Umwege direkt zu deinem Mailaccount. Superleicht zu merken, noch schneller eingegeben und extrem intuitiv. Wenn du dich also bei Protonmail anmelden möchtest, reicht auch pm.me.
Wenn du noch tiefer in die Trickkiste möchtest, schreib es mir in die Kommentare. Dann hole ich beim nächsten Update dieses Artikels noch etwas weiter aus.
Und jetzt Du
Fazit zur Sicherheit im Internet
Das Gelernte auf einen Blick, wo du am besten starten solltest und wo es mehr gibt.
That’s it.
Das waren 4 einfache und sofort anwendbare Schritte um Deine Sicherheit in Internet und Cyberspace dramatisch zu erhöhen.
Wenn du noch weitere Schritte zu noch mehr Sicherheit im Internet suchst, kann dieser etwas ältere Leitfaden des BSI helfen.
Und für nahezu alle sonstigen relevanten Sicherheits-Schritte mein 116+ umfassender Leitfaden zur Cybersecurity.
Jetzt bin ich gespannt was Du sagst:
Welchen der ausgeführten Schritte hast Du zuerst gelesen?
Wie bist Du in die Umsetzung gekommen?
Hast Du Dir direkt KeePass geschnappt und Deine Passwörter auf eine Durchschnittslänge von 62 Zeichen gebracht?
Oder mit dem Auslesen von Hyperlinks begonnen?
Egal was es ist und wie Du es umsetzt, ich bin gespannt von Dir zu hören! Wir lesen uns in den Kommentaren, bis gleich!
Die 116 besten Tools und Taktiken zur Cybersecurity
(2021)
Wenn du die besten Cybersecurity- Tools und Taktiken an einem Platz haben möchtest, wirst du diesen Guide lieben.
Nachfolgend findest du die besten 116 Werkzeuge und Möglichkeiten, mit denen du deinen Arbeitsplatz, deine Geräte und dein Unternehmen digital sicher halten kannst. Ergänzt wird diese Liste durch exklusive Empfehlungen von Top-Experten.
Kostenlose Anleitungen zum sofortigen Einsatz der hier genannten Tools und Taktiken sowie Updates kannst du dir hier kostenlos herunterladen:
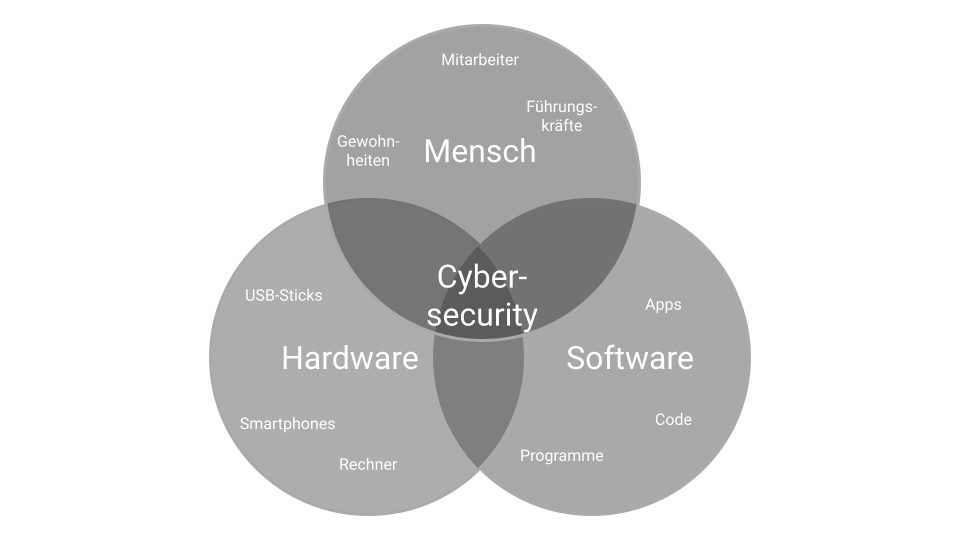
Cybersecurity ist für viele recht abstrakt. So wie “Sicherheitsmaßnahmen” in der “echten” Welt auch alles und nichts bedeuten können.
Grob gesagt besteht Cybersecurity aus drei ineinander verzahnten und aufeinander abgestimmten Bereichen:
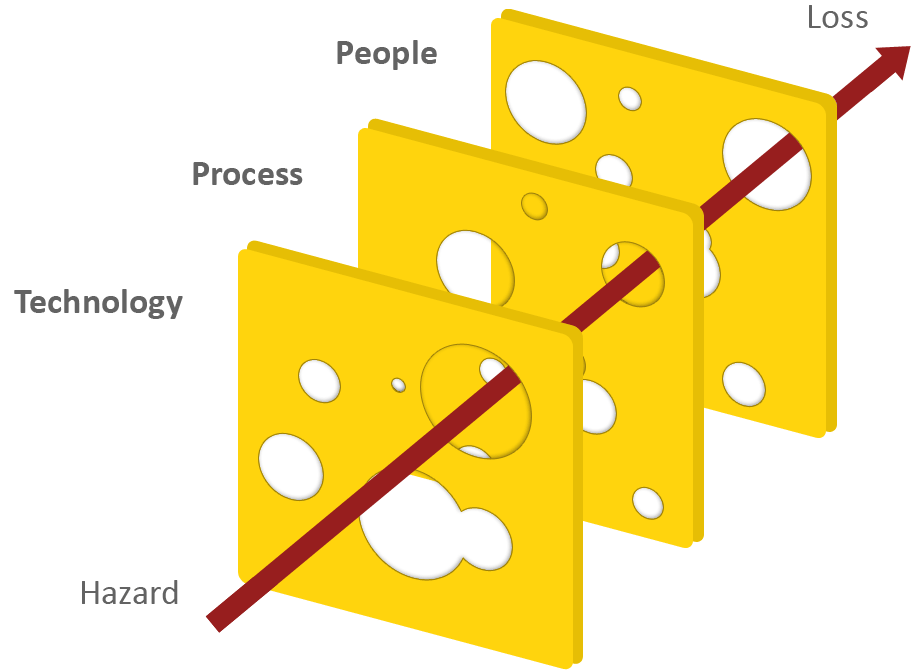
Dabei ist Cybersecurity mehr als die Summe seiner Teile. Du kannst dir Cybersecurity, das „digitale Immunsystem“ wie eine aufgeschnittene Zwiebel oder einen Stapel Schweizer Käsescheiben vorstellen:
Bildquelle und weitere Informationen: https://sketchplanations.com/the-swiss-cheese-model
Dieses Konzept kommt ursprünglich aus der Luftfahrt. Es wird mittlerweile für viele komplexe Gefahrensituationen wie bei der Seuchenabwehr angewandt. Auf die Cybersicherheit projiziert sieht es ungefähr so aus:
Bildquelle und weitere Informationen: https://securityandpeople.com/2017/07/human-errors-in-cyber-security-a-swiss-cheese-of-failures/
Um diese Schichten, die Bestandteile geht es hier. Bzw. um die praktischsten und sofort für dich anwendbaren Bestandteile.
Denn Cybersecurity ist ein so unglaublich komplexes Feld, das keine Seite der Welt sie vollständig abbilden kann.
Deshalb zeige ich hier 116 Facetten und sofort umsetzbare Möglichkeiten, welche den großen Begriff Cybersecurity für jeden Abschnitt mit Leben füllen.
Warum ist Cybersecurity wichtig?
Gibt es überhaupt Angriffe?
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
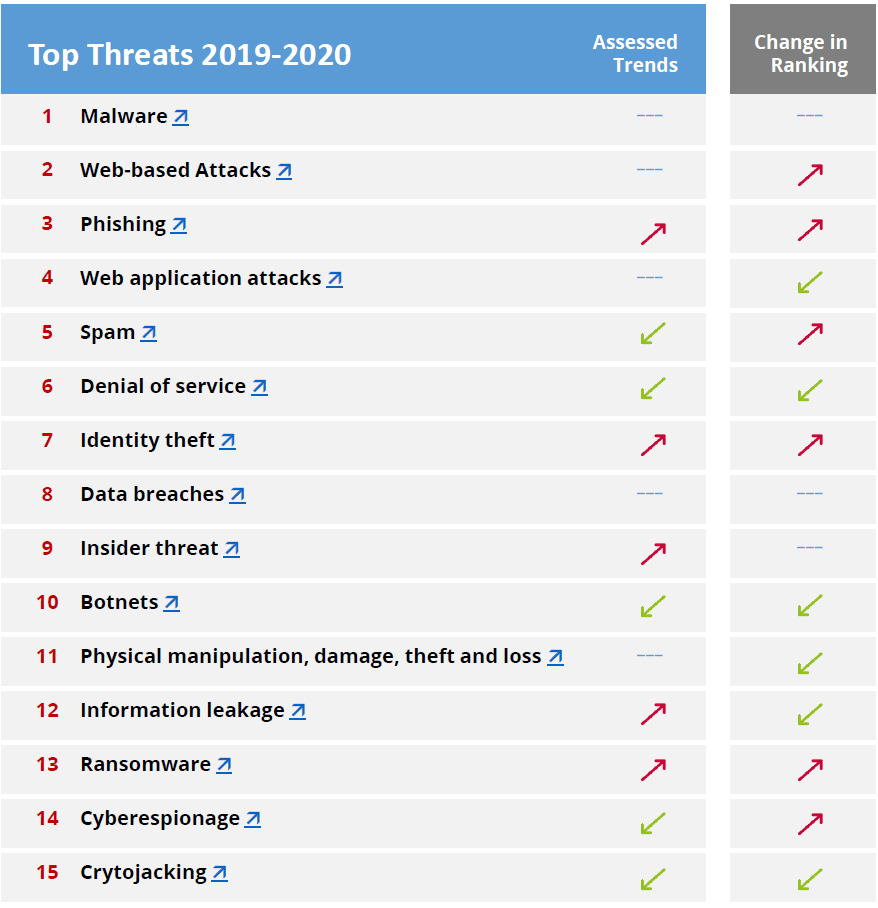
Die größten Gefahrenquellen der Cybersecurity sind laut ENISA, der europäischen Agentur für Cybersecurity, im Jahr 2019 / 2020:
Bildquelle und weitere Informationen: https://www.enisa.europa.eu/publications/year-in-review
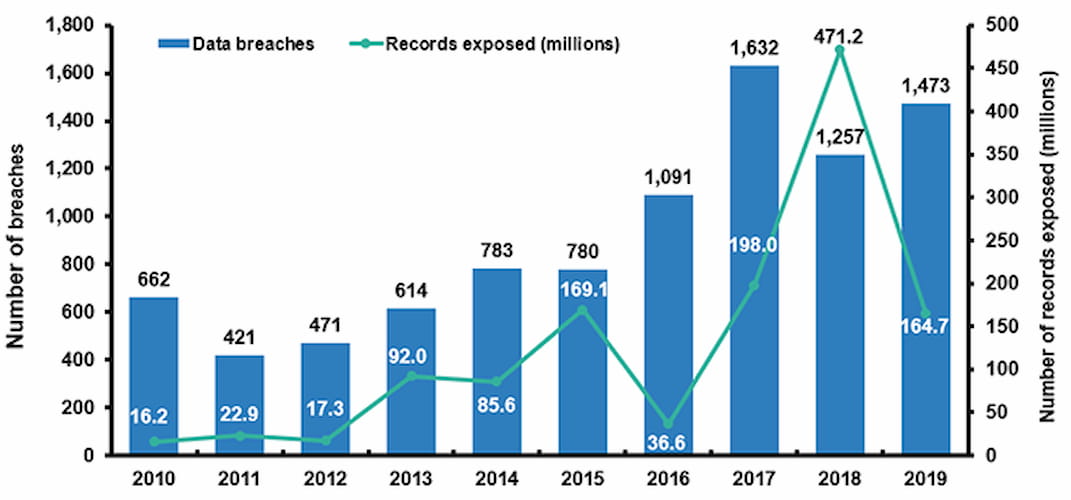
Angegriffen wird dabei jedes Unternehmen, ganz gleich der Größe oder Sparte wie diese und diese Tabelle so eindrucksvoll wie minutiös zeigen.
Die häufigsten Angriffsstrategien sind laut ENISA dabei:
Angriffe auf das menschliche Element
Web- und browserbasierte Angriffsvektoren
Im Internet exponierte Objekte
Ausnutzung von Schwachstellen / Fehlkonfigurationen und Fehlern in Kryptografie / Netzwerken / Sicherheitsprotokollen
Angriffe über Lieferketten
Netzwerkausbreitung / Lateralbewegung
Aktive Netzwerkangriffe
Missbrauch / Eskalation von Privilegien oder Benutzeranmeldeinformationen
Dateilose oder speicherbasierte Angriffe
Fehlinformation / Desinformation
Schön visualisiert auch diese Echtzeit-Cyberthread-Karte von Kaspersky einen Ausschnitt der virtuellen Bedrohung.
Tipps
zur optimalen Umsetzung
Um das Maximum aus den hier genannten Tools und Taktiken herauszuholen ergibt es Sinn:
Überprüfung und Auseinandersetzen mit dem Tool / der Taktik um zu evaluieren, welche und in welcher Form am besten funktioniert.
Rücksprache / Fragen an den jeweiligen zuständigen. Es geht hier nicht um Kompetenzen oder Bevormundung, es geht um eine optimale Sicherheit. Wenn er aus dem Hut sagen kann, wie das bereits umgesetzt ist, großartig. Wenn nicht, kann das ein guter Startpunkt für weitere Sicherheit sein.
Jeder dieser Hinweise ist nach bestem Wissen und Gewissen erstellt, Erfolge in der individuellen Anwendung müssen allerdings individuell abgewogen und ggf. betreut werden.
Jetzt aber mitten rein ins Vergnügen, los geht’s:
Software
Der digitale Teil der Cybersecurity
Prinzipiell sind sehr viele der hier vorgestellten Cybersecurity-Möglichkeiten Software.
Und da der Großteil der Cyber-Security im Cyber-Raum stattfindet, nimmt Software hier logischerweise den größten Teil ein.
In diesem Abschnitt geht es mir allerdings vor allem um die “80/20” Programme, also die 20 % der Cybersecurity-Software, die so unabhängig wie möglich von der Tätigkeit des Anwenders 80 % der Sicherheits-Ergebnisse erzielt. An anderen Stellen gebe ich auch zum Teil Software-Empfehlungen, diese dann aber Abschnitts-spezifisch.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Sichere Passwörter
Auf absehbare Zeit bleiben Passwörter die wichtigste Sicherungsmaßnahme im Digitalraum. Sie können zwar durch andere Maßnahmen ergänzt und eingerahmt werden, doch bleiben sie vorerst die #1 auf der Liste der Verteidigungsstrategien. Doch Passwort ist nicht gleich Passwort.
Ein sicheres Passwort zeichnet aus:
Es ist > 13 Zeichen lang.
Es besteht aus allen Zeichenkategorien auf der Tastatur. (Groß- und Kleinschreibung, Zahlen und Buchstaben, Sonderzeichen etc.)
Weitere Tipps und hilfreiches Rahmenwissen rund ums sichere Passwort findest du hier.
2. Nutzung von Passwortmanagern
Da sich die wenigsten Menschen viele verschiedene lange Zeichenkombinationen merken können, bieten sich hierzu als bequeme, automatische und sichere Lösungen Passwortsafes oder Passwortmanager an. Beispiele sind KeePassX oder 1Password.
Bildquelle und weitere Informationen: https://blog.clickomania.ch/2017/09/21/ein-uberfalliger-umstieg/
3. Passphrasen
Passphrasen sind Kombinationen verschiedener Wörter und Zeichen zu merkbaren “Passwort-Sätzen”.
Ein paar Hinweise um Passphrasen optimal einzusetzen:
Verwende eine leicht zu merkende, aber ungewöhnlichen Phrase. Zum Beispiel “Luke Skywalker isst rosarote Rosenblätter, haha”
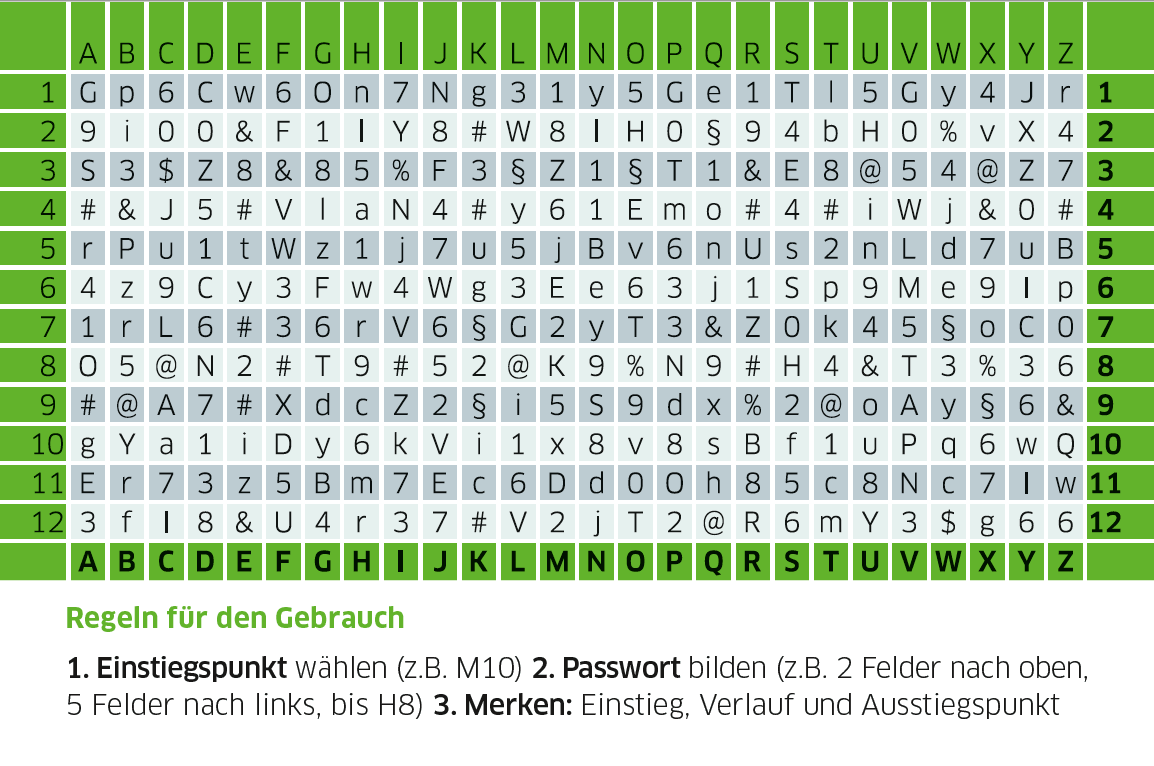
Passwort-Karten verwandeln Passwörter in Schrittfolgen. Du merkst dir mit einer Passwortkarte nur den Startpunkt, das Muster (z.B. immer ein Feld diagonal nach unten) und den Endpunkt. Den Rest macht deine Passwortkarte.
Bildquelle und weitere Informationen: https://www.sicher-im-netz.de/dsin-passwortkarte
5. Passwort-Sätze
Mit Passwort-Sätzen merkst du dir nur einen Schlüsselsatz und gibst von diesem z.B. nur die Anfangsbuchstaben jedes Wortes in diesem Satz ein. Bsp.: „Ich lebe seit ich 10 bin allein zu Hause.“ = „Ilsi10bazH.“
Passwortsätze werden noch effektiver durch Kombination mit “Leetspeak” (Ersetzen von Buchstaben durch ähnlich aussehende Ziffern und/oder Sonderzeichen) Bsp.: Wikipedia = w!k!p3d!4
6. Verschlüsselungs-software
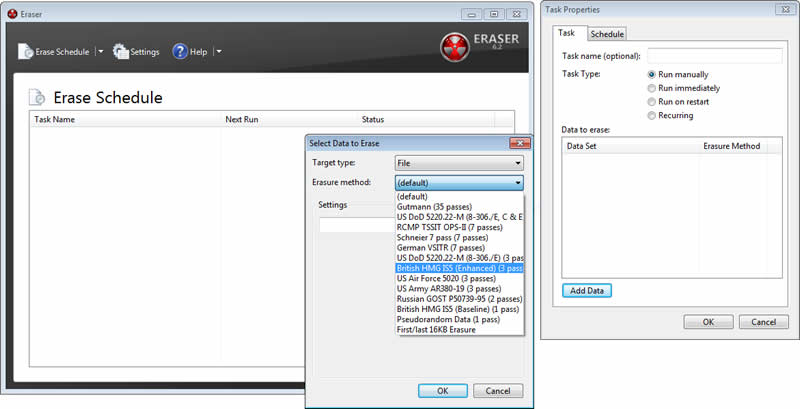
Daten zu verschlüsseln ist sowohl sinnvoll für Daten als auch für Festplatten- und deren Partitionen. Das beste Tool zum Start ist Veracrypt.
Download und weitere Informationen zu VeraCyrypt sowie Bildquelle: https://www.heise.de/download/product/veracrypt-95747
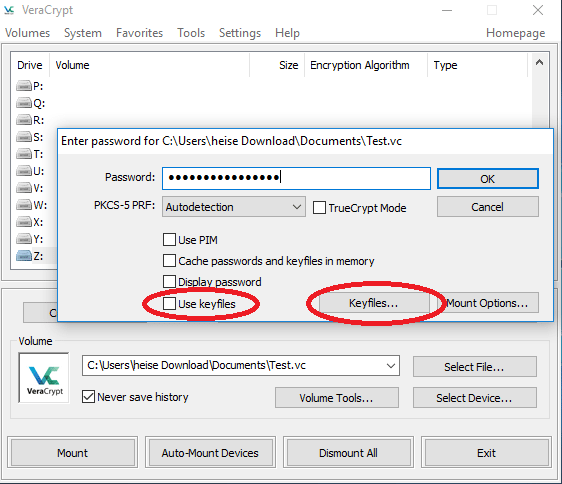
7. Zugriffsdateien
Zugriffsdateien erhöhen die Einbruchssicherheit von Passwortmanagern und Verschlüsselungstools zusätzlich enorm. Sie sind wie ein Schlüssel zusätzlich zum Passwort. Doch Vorsicht: Einmal verloren oder nur um ein Bit korrumpiert sind die Zugriffsdateien niemals wiederherstellbar und unwiederbringlich verloren.
Weitere Informationen und Bildquelle: https://www.heise.de/download/product/veracrypt-95747
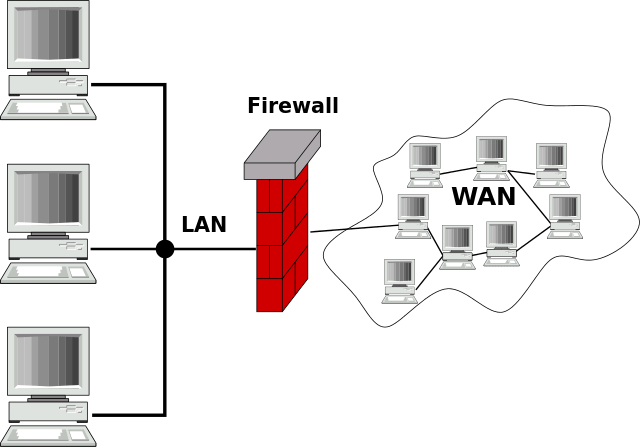
8. Firewall
Eine Firewall schirmt einen Rechner vor einigen Angriffsarten von außen ab. Es gibt verschiedene Firewall-Typen und Anbieter.
9. Antimalware
Malware bezeichnet jeden Schadcode, der Systeme infizieren, infiltrieren und zerstören soll. Dabei gibt es einerseits „klassische“, also von Menschen geschriebene Malware. Und andererseits „intelligente“, also reaktive / anpassungsfähige Malware. Letztere wird durch Machine Learning und künstliche Intelligenz möglich.
Unter Malware zählen zum Beispiel
Computerviren
Trojaner
Ransomware
Keylogger etc.
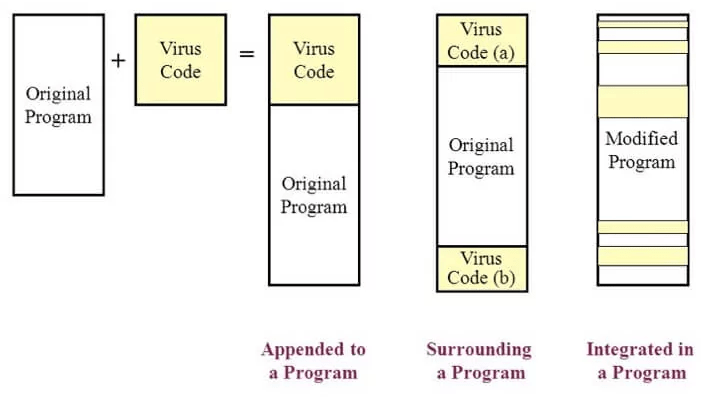
Angriffswege eines Computervirus. Bildquelle und weitere Informationen: https://slideplayer.com/slide/7999162/
10. Angriffsprävention / OSINT
OSINT steht für Open Source Intelligence Tools, also grob “öffentlich nutzbare Werkzeuge”.
Diese werden vor allem von Geheimdiensten genutzt, aber ebenso gern zur Vorbereitung von Großangriffen.
Zu wissen, welche Daten wie herauszufinden sind, hilft enorm bei der Verteidigung gegen Social Engineering Angriffe.
Tools wie TOR, für VPN– oder Maschennetz-Verbindungen sorgen dafür, dass der eigene Datenstrom im Internet schwerer bis nicht mehr nachvollzogen werden kann.
Kombiniert mit Tools wie z.B. TAILS lässt sich so eine sehr hohe Sicherheit gegen fremde Zuschauer erreichen. Der einfachste, schnellste und bequemste Zugang zu TOR ist über den Brave-Browser (Der zeitgleich auch auf andere Wege die eigene Online-Sicherheit erhöht).
Der einfachste Einsatz von Mesh-Nets / Maschennetzen geht via Freifunk oder Firechat (letzteres war leider so wirksam, dass es abgeschaltet wurde).
Bildquelle: Eigener Screenshot
12. Umgebung simulieren / Virtuelle Systeme
Virtuelle Systeme simulieren eine echte PC-Umgebung. Dadurch hinterlässt der Anwender weniger / weniger nachvollziehbare / andere Spuren und/oder kann Programme in einer sicheren Umgebung prüfen.
Zu virtuellen Systemen zählt alles von der Sandbox (mehr dazu beim Punkt “Sandboxes” und “AI-Sandbox” bis hin zum komplett gehärteten System.
TAILS ist das sicherste, am einfachsten nutzbare virtuelle “all in one” System.
Weitere Informationen und Bildquelle: https://en.wikipedia.org/wiki/Tails_(operating_system)
13. Sicherheits- / Penetrationstests
Tools wie Kali Linux oder Metasploit sind Pen-Test-Tools, “Penetrationstest-Tools”. Mit diesen können Systeme angegriffen werden, um Schwachstellen zu finden, um diese dann zu fixen.
Achtung: Einige der Werkzeuge innerhalb dieser Tools können, je nach Land, Anwendung etc., halb- / oder gar illegal in der Anwendung sein.
Bildquelle und weitere Informationen zu Kali: https://www.heise.de/security/meldung/Kali-Linux-2020-1-aktualisiert-Startmedien-Auswahl-und-mustert-Standard-Root-aus-4648751.html
14. Ablenkungsmanöver / Honey Pots
Honeypots oder “Honigtöpfe” sind Systeme oder Maschinen, die Angriffe auf sich ziehen, um das eigentliche Ziel zu schützen und die Angriffe aus sicherer Entfernung analysieren zu können. Honeypot-Tools findest du zum Beispiel hier und hier.
15. Frühwarnsysteme / Sentiment-Analyse-Tools
Sentiment-Analysen sind automatische Suchen nach eingestellten Schlüsselwörtern- und Phrasen. Vor allem zur Stimmungserkennung und Shitstorm-Prävention eingesetzt, helfen diese Tools auch zur Echtzeitüberwachung potenzieller großflächiger Angriffe und deren Vorbereitung.
Tool-Übersicht und Bildquelle: https://www.talkwalker.com/de/blog/die-besten-sentiment-analyse-tools
16. Kontrollierte Sprengung / Sandboxes
Sandboxes sind vom Rest des Systems abgeschottete Testbereiche, in denen die Wirkung von Software in Sicherheit getestet werden kann. Versucht eine Schadsoftware beispielsweise innerhalb einer Sandbox ein System anzugreifen, wird sie samt der Sandbox einfach gelöscht. Die meiste Antiviren-Software setzt Sandboxes automatisch ein, separate Tools findest du hier.
17. Sichere E-Mail-Provider
Mails und Mailprogramme sind eines der größten Einfallstore und Angriffspunkte für Angriffe jeder Art. Neben dem gefährlichen Inhalt von Mails, dem Phishing, ist es ebenfalls wichtig, einen Mailprovider zu wählen, der technisch sicher ist.
Mein persönlicher Favorit ist seit vielen Jahren Protonmail, es gibt aber auch andere empfehlenswerte Anbieter, z.B. hier aus Deutschland.
18. E-Mail Historie auf Mobilgeräten auf max. 30 Tage begrenzen
Dieser Tipp hilft vor allem gegen Diebstähle oder dem Verlust des Mobilgeräts. Sollte aus irgendeinem Grund auf das Gerät zugegriffen werden können, bleiben die abfließenden Daten begrenzt.
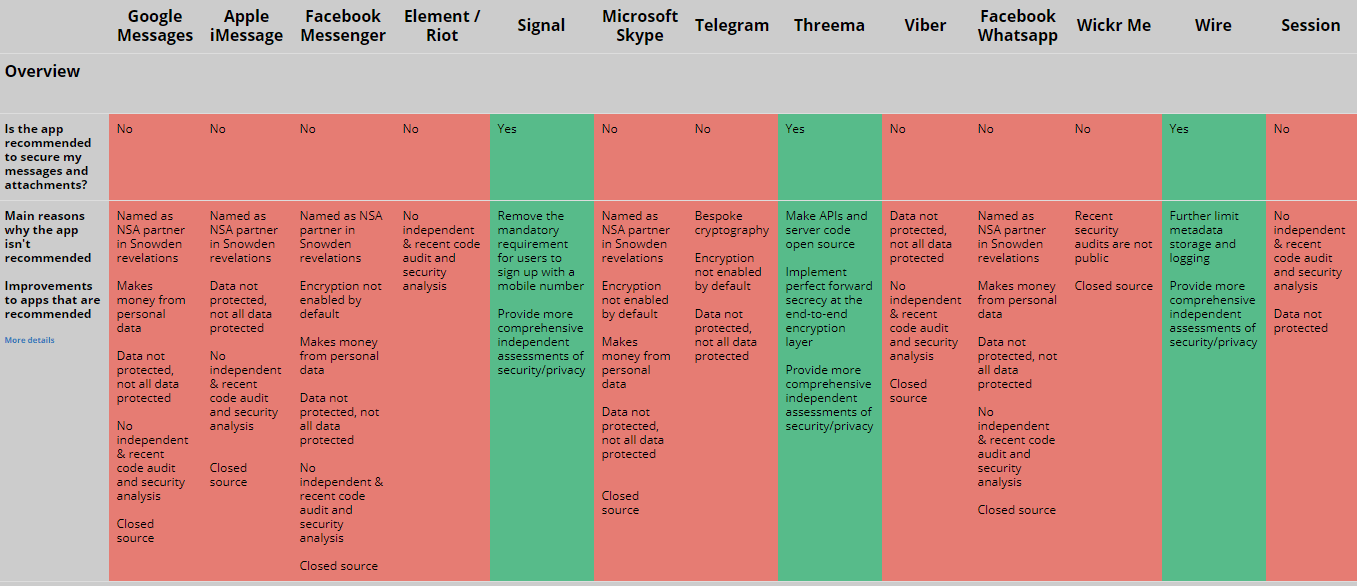
19. Sichere Messenger nutzen
Vor allem in Hacker- und Geheimdienstkreisen hört man immer wieder, man solle so gut es geht auf Mails generell verzichten. Und stattdessen sichere Messenger nutzen. Also Programme wie WhatsApp, nur sicher. Mein persönlicher Favorit ist Wire.
Bildquelle und weitere Informationen zur Übersicht: https://www.securemessagingapps.com/
20. Automatische Gegeninformationen
Das Konzept der Gegeninformation kommt aus dem Militär und spezieller (dessen) Geheimdiensten.
Es werden dabei einfach gezielt falsche Spuren gelegt, durch welche von außen nicht mehr nachvollziehbar ist, welche Spur echt ist und welche nicht. Somit wird die Erstellung detaillierter Profile erschwert
Kann ergänzend zum Trennen von Datenströmen eingesetzt werden. Browser-Plugins wie z.B. TrackMeNot können hier schnell und unkompliziert zum Start eingesetzt werden.
Bildquelle: Eigener Screenshot
21. Ggf. private Tabs zum Standard machen
Private Tabs bieten (abhängig vom jeweiligen Browser) zwar keinen wirklichen Zusatzschutz, aber innerhalb dieser werden keine Daten wie Passwörter, besuchte Seiten etc. gespeichert.
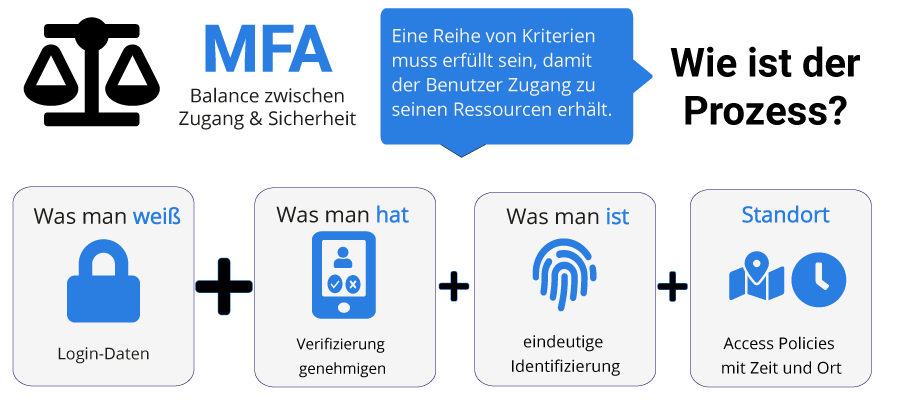
22. Verschiedene Schlösser verwenden / Multi-Faktor-Authentisierung
“X-Faktoren-Authentifizierung”, auch “Multi-Faktor-Authentisierung” genannt ist die Anwendung verschiedener Schlüssel, um ein Schloss öffnen zu können.
Dadurch wird es Angreifern erschwert, in ein System einzudringen. Denn diese brauchen ja immer alle verwendeten Schlüssel, um die Tür zu öffnen.
Faktoren / Schlüssel können zum Beispiel sein:
Link klicken
PhotoTAN scannen
SMS-Code eingeben usw.
Mehr dazu im Abschnitt Gewohnheiten.
Bildquelle und weitere Informationen: https://www.tools4ever.de/glossar/was-ist-multi-faktor-authentifizierung/
23. Die Orientierung behalten / Shortlink-Prüfer
Selbst wenn man Links lesen kann, verschleiern Shortlinks, also Services, die aus langen Links kurze, leicht zu merkende machen wie bit.ly oder ähnliche Services effektiv die tatsächliche Linkquelle. Wenn man den Shortlink anklickt, kann es aber unter Umständen schon zu spät sein.
Shortlink-Prüfer helfen dabei, indem sie den Link anklicken und das Ergebnis aus sicherer Distanz anzeigen. Ähnlich einem virtuellen System.
Ein Shortlink-Prüfungs-Tool. Quelle: Eigener Screenshot
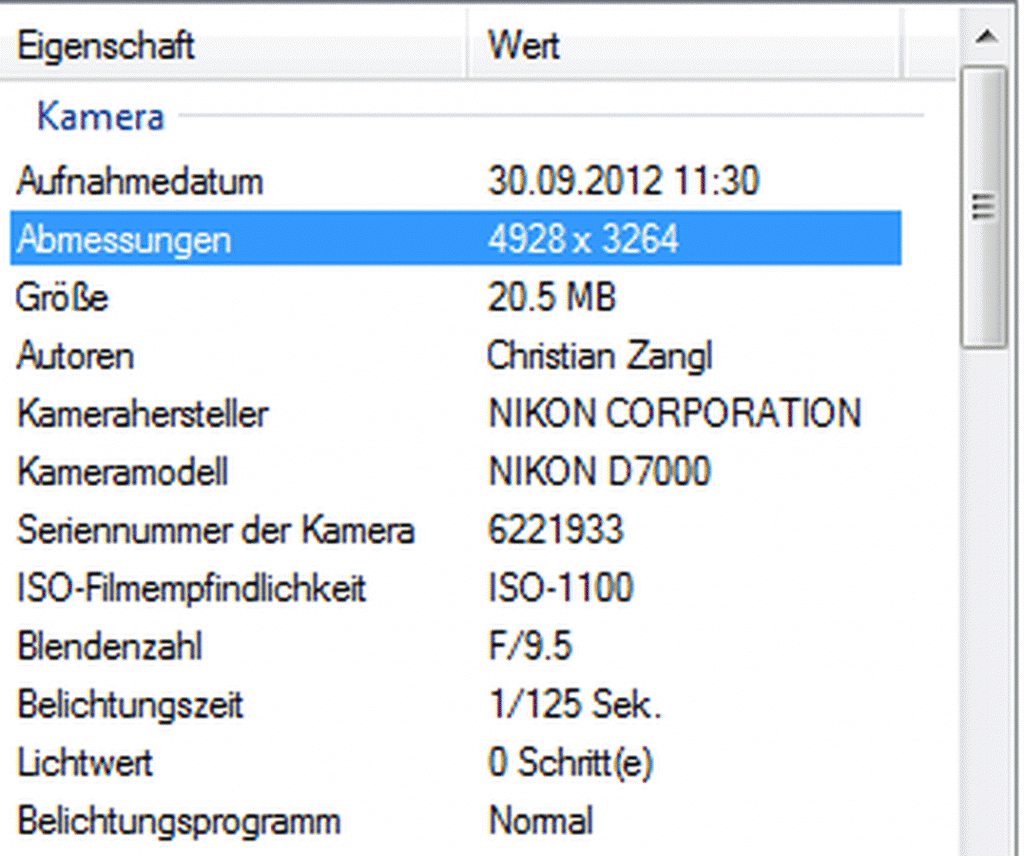
24. Die Privatsphäre bei Bildern sichern / Exif-Daten löschen / verhindern
Exif-Dateien sind spezifizierende Daten, die automatisch rund um ein Foto erstellt werden. Also zum Beispiel Aufnahmeort-, Zeit, etc. Exif-Daten zu löschen verhindert, das jeder, der Zugriff zum Bild hat, erfährt wann, wo, von welchem Gerät etc. das Bild gemacht wurde. Zu verhindern, dass diese Daten anfallen ist nicht ganz leicht, sie zu löschen aber glücklicherweise schon.
Bildquelle und weitere Informationen zu Exif-Daten: https://www.digitipps.ch/fotolexikon/exif-daten/
25. Das Klingelschild des Rechners abmontieren / MAC Adresse randomisieren
Die MAC-Adresse ist das Klingelschild einer Netzwerkschnittstelle. Über die MAC-Adresse kann also überall weltweit dein jeweiliges Gerät exakt zugeordnet werden. Um das zu verhindern, lohnt es sich die MAC-Adresse zu randomisieren. Auf jedem ans Internet angeschlossene Gerät.
Bildquelle und weitere Informationen: https://www.heise.de/download/product/infosniper-ip-adressen-lokalisierung-55629
27. Wurde ich schon gehackt? / Sicherheitsstatus überprüfen
Tools wie HaveIBeenPwned oder der Identity Leak Checker des HPI sind hervorragend geeignet um auf einen Blick zu sehen, welche Daten und Zugriffsinformationen der eigenen Online-Aktivitäten bereits für jeden zugänglich durchs Netz fliegen.
Schnelles Handeln ist dann angesagt. Heißt: Neue Passwörter, Prüfung auf verdächtige Aktivitäten etc.
Bildquelle: Eigener Screenshot
28. WordPress sichern
Ein kleiner Exkurs zum Schluss dieses Abschnitts: Da WordPress knapp 65 % aller Webseiten bedient, ergibt es Sinn hier ein paar kurze Empfehlungen für hilfreiche Tools zur WP-Sicherheit zu geben. Meine Favoriten dabei sind:
Hardware anzugreifen ist nicht so einfach wie eine Attacke gegen Software und bei weitem nicht so leicht wie die Manipulation eines Menschen. Dennoch ist dies ein beliebter Vektor um in Systeme einzudringen.
Bei Hardware gilt die Minimal-Faustregel: Das Sender-Gerät, das Empfänger-Gerät und die Verbindung zwischen beiden Geräten muss gesichert sein. Also z.B. beim Surfen im Internet: der Computer des Anwenders, die Internetverbindung und der Server der aufgerufenen Webseite. Der Rest ist (grob vereinfacht) auf der Seite der Software.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Hardware-Firewall
Eine Hardware-Firewall funktioniert sehr ähnlich wie ihre Software-Schwester, kann ergänzend allerdings für weiter erhöhte Sicherheit sorgen.
Bei der Hardware-Firewall gleicht das Gerät (die Hardware) die verschiedenen Datenströme ab und macht es durch die Andersartigkeit im Vergleich zur Software Angreifern zusätzlich schwer, in ein System einzudringen. Zumal ein Angriff auf den Zielrechner, welche eine Software-Firewall aushebeln kann, die Hardware-Firewall nicht betrifft, da diese vom Rechner getrennt ist.
Bildquelle und weitere Informationen: https://de.malwarebytes.com/
2. Hardware-Schlüssel
Hardware-Schlüssel sind ein hervorragender Teil der Multi-Faktor-Authentisierung und machen es extrem schwer in einen Rechner einzudringen.
Diese Hardware-Schlüssel, auch FIDO-Sticks genannt, erschweren es wie bei einer klassischen Haustür jedem ohne Schlüssel in die “Wohnung” (den Zielrechner) zu gelangen. Ein guter Startpunkt ist der Titan Security Key von Google.
Bildquelle und weitere Informationen: https://store.google.com/de/product/titan_security_key?hl=de
3. Niemals (YMYL) Login-Daten auf (mobilen) Geräten speichern
YMYL steht für “Your Money Your Life” und bezeichnet sämtliche Daten die mit deinem Geld und deinem Leben / deiner Gesundheit verbunden sind. Den Zugriff auf diese besonders sensiblen Daten zu sichern hat oberste Priorität. Vor allem auf mobilen also leicht beweglichen Geräten sollten daher nach Möglichkeit keine Login-Daten gespeichert werden.
Die im Bild aufgezählten Themen bieten eine gute Orientierung, welche Login-Daten besser nicht gespeichert werden. Bildquelle und weitere Informationen zu YMYL: https://static.googleusercontent.com/media/guidelines.raterhub.com/en//searchqualityevaluatorguidelines.pdf
4. Smartphone ggf. abschalten und die Batterie entfernen
Um eine passive Datensammlung / Tracking zu vermeiden, kann es sinnvoll sein, sein Smartphone abzuschalten und den Akku zu entfernen.
5. Mobilgeräte regelmäßig auf Werkseinstellungen zurücksetzen
Dieser einfache Trick vermeidet Schadsoftware, die sich ohne das Wissen des Nutzers auf dem Smartphone breitgemacht hat. Indem sie bei jedem Root-Vorgang gelöscht wird. (Root-Vorgang = Das Gerät wird in den Urzustand zurückversetzt)
6. Kameras abkleben
Mark Zuckerberg, der Chef des FBI und alle auf Ihre Sicherheit bedachte Personen kleben die Kameras und Mikrofone Ihrer Geräte ab. Denn diese sind unzählbar oft nachgewiesen direkte Spionagetools.
Eine grundsätzliche Alternative können “harte”, also von Werk aus cybersichere Geräte wie zum Beispiel Kryptohandys sein.
Bildquelle und weitere Informationen: https://9to5mac.com/2016/06/21/facebook-mark-zuckerberg-tape-over-camera/
7. Gesamte Festplatte verschlüsseln
Festplattenverschlüsselungen können eine gute erste Verteidigungslinie gegen Angreifer bilden. Noch wichtiger als ohnehin schon: Regelmäßige Sicherungen anlegen! Festplattenverschlüsselungen können Hand in Hand mit Partitionsverschlüsselungen und verschlüsselten Containern eingesetzt werden.
8. NIEMALS USB-Sticks anschließen, denen du nicht vertraust!
Mit infizierten USB-Sticks wurden schon Kernkraftwerke ausgeschaltet.
Daher: Egal was auch passiert, schließe niemals einen fremden USB-Stick an einen Rechner mit sensiblen Daten an. Nie. Mals. Egal wie fancy er auch aussieht.
Ein drahtloses Netzwerk zu sichern ist keine ganz leichte Aufgabe. Denn: Jeder mit einem Gerät, welches sich in das WLAN einloggen kann, kann dieses prinzipiell angreifen. Hier ein paar grundlegende Tipps zur WLAN-Sicherheit: (WPA2) Verschlüsselung aktivieren Sicheres Passwort für Verschlüsselung, Router und Zugang nutzen (unterschiedliche Passwörter für jeden Punkt nutzen) Sämtliche Software immer auf dem neuesten Stand halten. Wenn möglich Kabel statt WLAN nutzen Datei- und Drucker-Freigabe deaktivieren SSID-Broadcasting deaktivieren
Smartphones sind ein Schlaraffenland für Cyber-Angreifer. Denn sie sind mobil, also leicht zu entwenden, verknüpfen sich mit verschiedenen Netzwerken via WLAN, sind dank Ihren Sensoren, Kameras und Mikrofonen mobile Spionagegeräte und speichern sehr oft potenziell kompromittierendes Material.
Deshalb ist es sehr wichtig, sein Smartphone zu sichern. Im Fachjargon spricht man von “härten”.
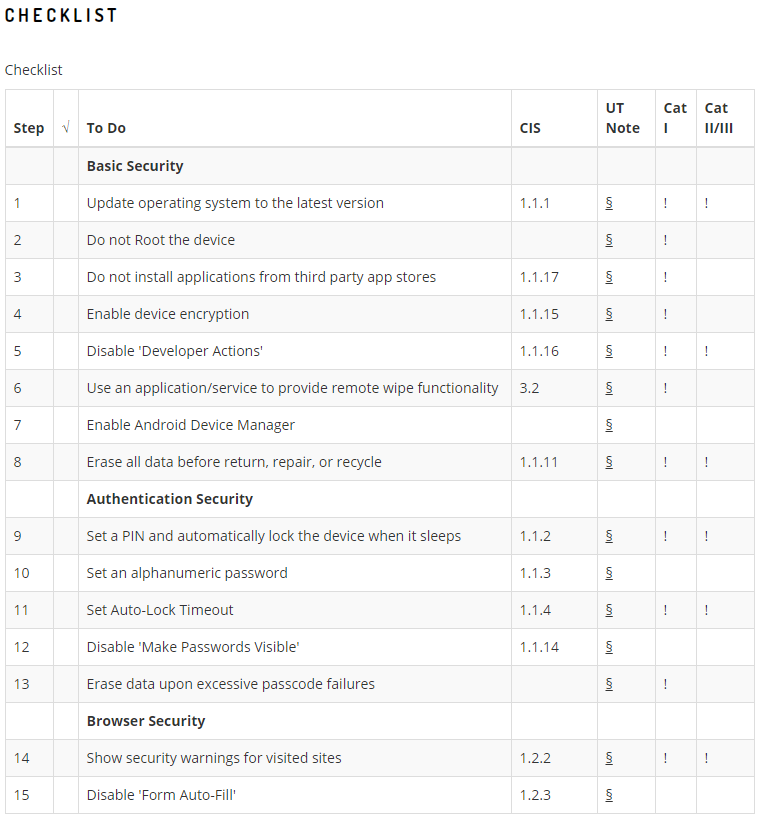
Wie weiter oben bereits angesprochen ergeben ggf. Kryptohandys oder zumindest gehärtete Betriebssysteme wie dieses Sinn, ansonsten können diese und diese Anleitung sehr gut helfen.
Bildquelle und vollständige Checkliste: https://security.utexas.edu/handheld-hardening-checklists/android
Mitarbeiter
Der größte Teil der Cybersecurity
Der Mensch ist in > 99 % der größte und einfachste Schwachpunkt jedes Systems.
Viele Hacker beschäftigen sich aus diesem Grund schon gar nicht mehr mit Technologien, denn User zu manipulieren ist fast immer im Vergleich kinderleicht.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Das eigene Gehirn sichern / Amgydala-Hijacking
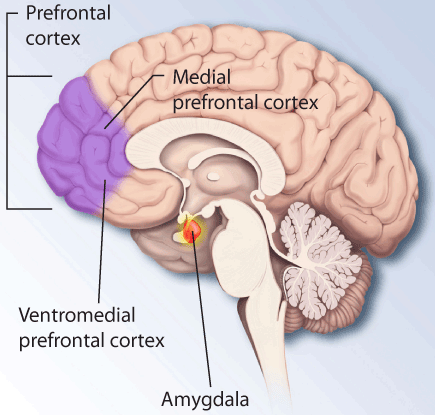
Eine der effektivsten Strategien des Social Engineering ist es, das Angriffsziel in eine starke Emotion wie Angst oder Stress zu versetzen. Dadurch schaltet das Gehirn des Angriffsziels von “komplex denkend” in den “Kampf oder Flucht” -Modus. Das Angriffsziel kann dann kaum / nicht mehr abstrakt denken und z.B. Rechnungen ausführen, sondern nur noch “quasi-panisch” reagieren. Ab diesem Moment ist man buchstäblich Spielball des Angreifers.
Und das passiert nicht in Gedanken. Deine Wahrnehmung wechselt durch diesen Angriff den “Wohnort” vom präfrontalen Kortex aus deinen höheren Hemisphären in die Amygdala, dein Stammhirn. Unvorbereitet kannst du also buchstäblich nichts (sinnvolles) gegen eine “Amygdala-Geiselnahme” machen.
Ein Bewusstsein dieser Möglichkeit, Standardprotokolle und Strategien sowie Stresstests können dabei effektiv helfen. Weitere Optionen findest du hier.
Bildquelle: https://commons.wikimedia.org/wiki/File:Ptsd-brain.gif Weitere Informationen: https://benjamineidam.com/phishing-anruf
2. Regelmäßige Schulungen und Tests
Wie heißt es so schön: “Boxen lernst du nur, indem du boxt”.
Genauso verhält es sich mit Cybersicherheit: Sicherheitslücken findest du nur heraus, indem deine Wälle angegriffen werden. Und die sich dadurch offenbarenden Schwachstellen freigelegt und bewusst behoben werden.
Gute Möglichkeiten dazu fürs ganze Unternehmen sind Stress- bzw. / Pentests.
Für Mitarbeiter im Speziellen ist die beste Möglichkeit allerdings die, die sichere Option zur Standardoption zu machen. Also die Gewohnheiten gezielt anzupassen.
Am einfachsten geht dies durch Umgebungsdesign. Mehr zur gezielten Gestaltung sicherer Gewohnheiten im gleichnamigen Abschnitt.
3. Keine letalen Daten in der Öffentlichkeit
Letale Daten sind alle Informationen, die in den falschen Händen zu schwerwiegenden bis vernichtenden Schäden führen können. Je nach Situation zum Beispiel Passwörter, Schlüsselkarten, Zugangscodes etc.
Eine gute Faustregel dazu ist: “Würdest du dich wohlfühlen, das Gesagte per Megafon in eine Gruppe Menschen zu sprechen?”
Wenn sich dir bei dem Gedanken daran der Magen umdreht, führe das Telefonat lieber im Nachbarraum, denke zweimal über das Aufschreiben deines Passworts nach etc.
4. Angriffsflächen bewusst machen
Jeder Mensch ist angreifbar, vor allem mit virtuellen Hilfsmitteln. So weit nichts Neues.
Doch die spezifischen Schwachpunkte unterscheiden sich individuell und nach Persönlichkeitstyp. Eine hervorragende Einführung in das Thema ist dieser Artikel des IT-Experten Philipp Schaumann.
Die beste und zugleich schnellste Persönlichkeitsanalyse als Startpunkt findet sich hier.
Schwachstellenprofile können ein guter Startpunkt für die Security Awareness sein. Bildquelle und weitere Informationen: https://www.sicherheitskultur.at/social_engineering.htm
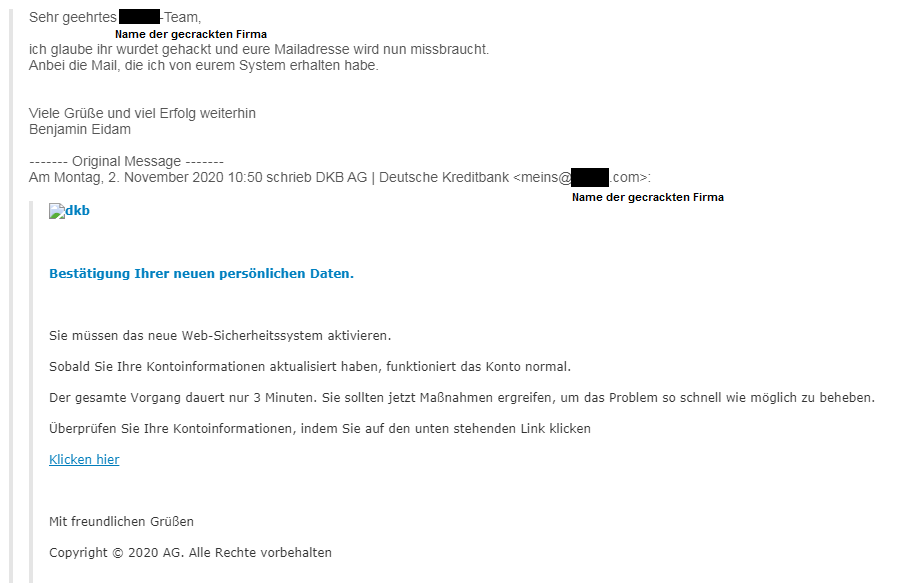
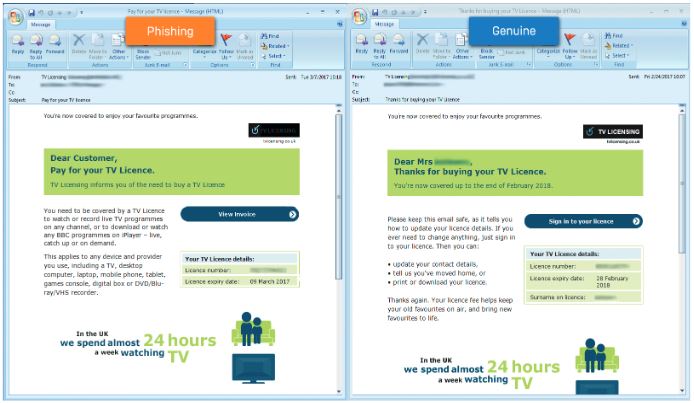
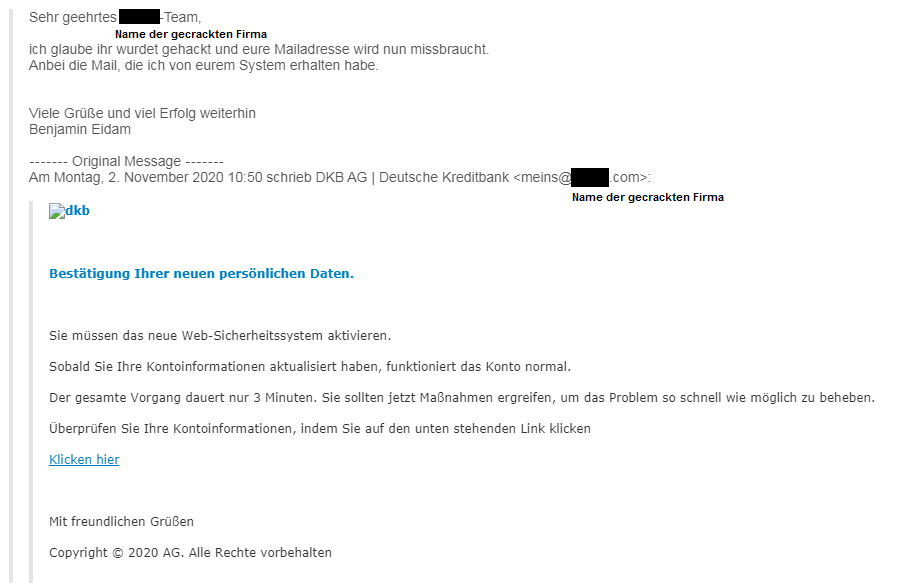
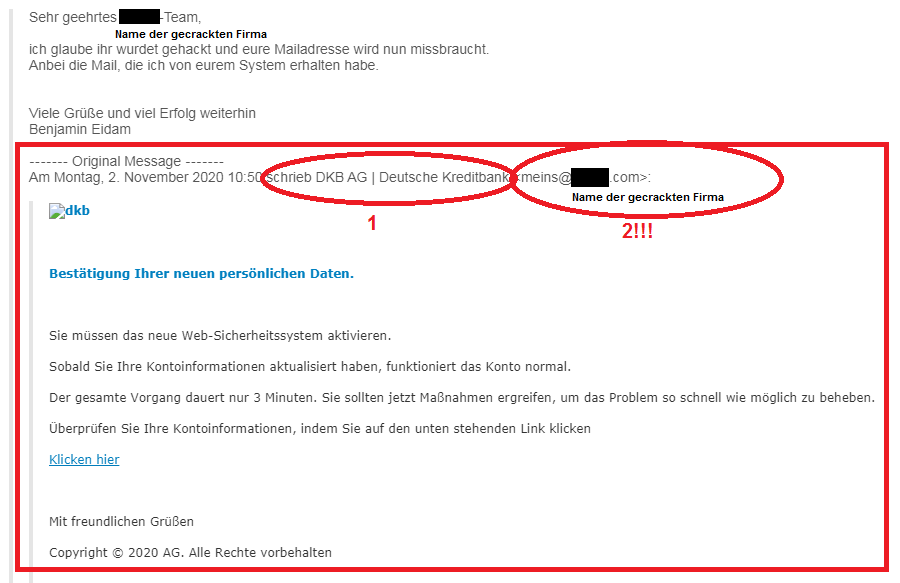
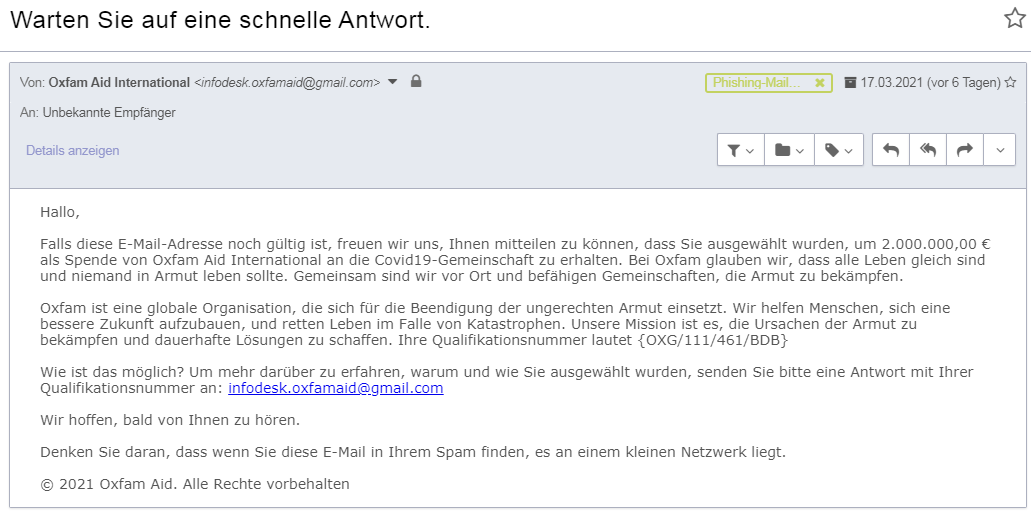
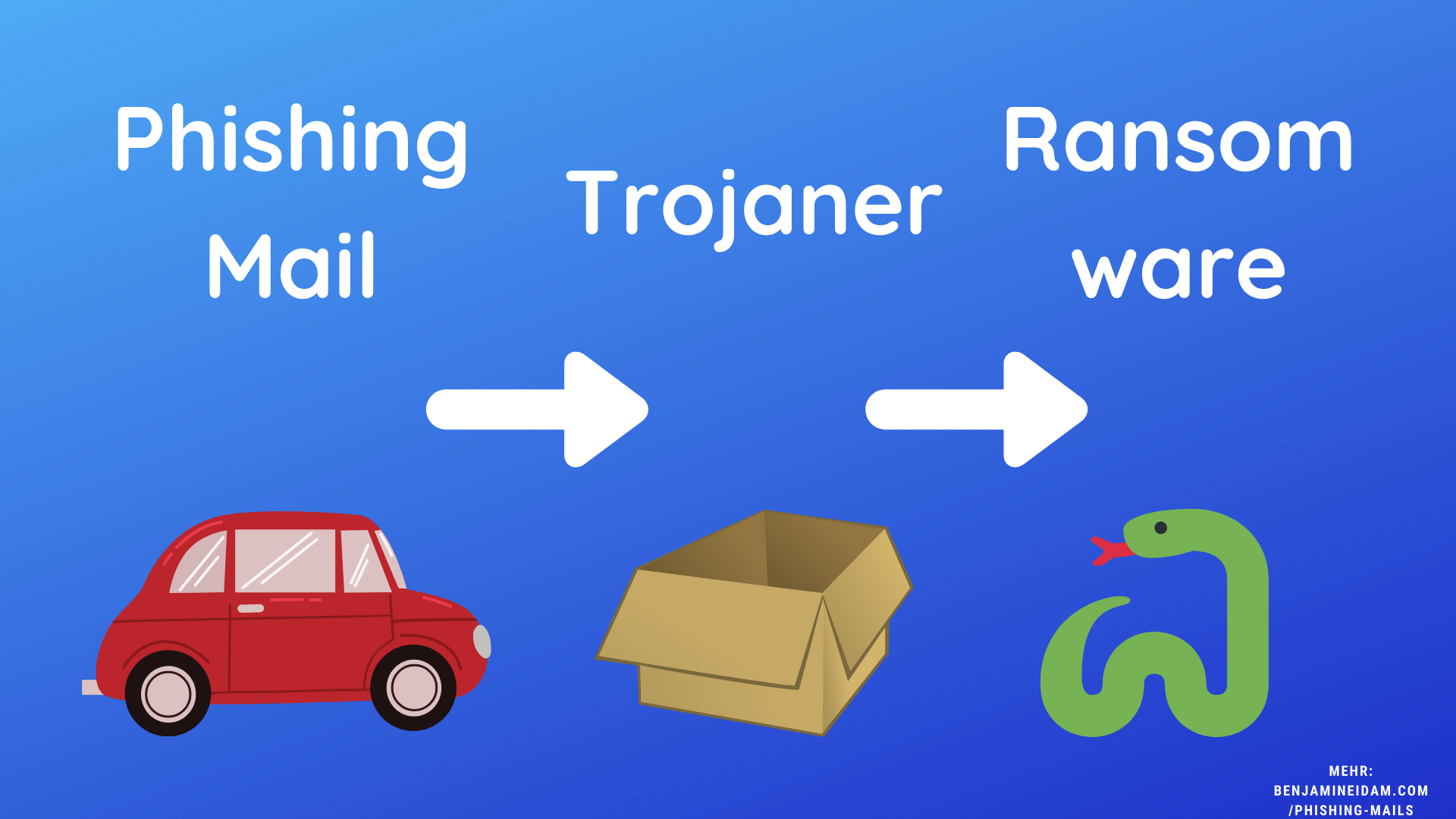
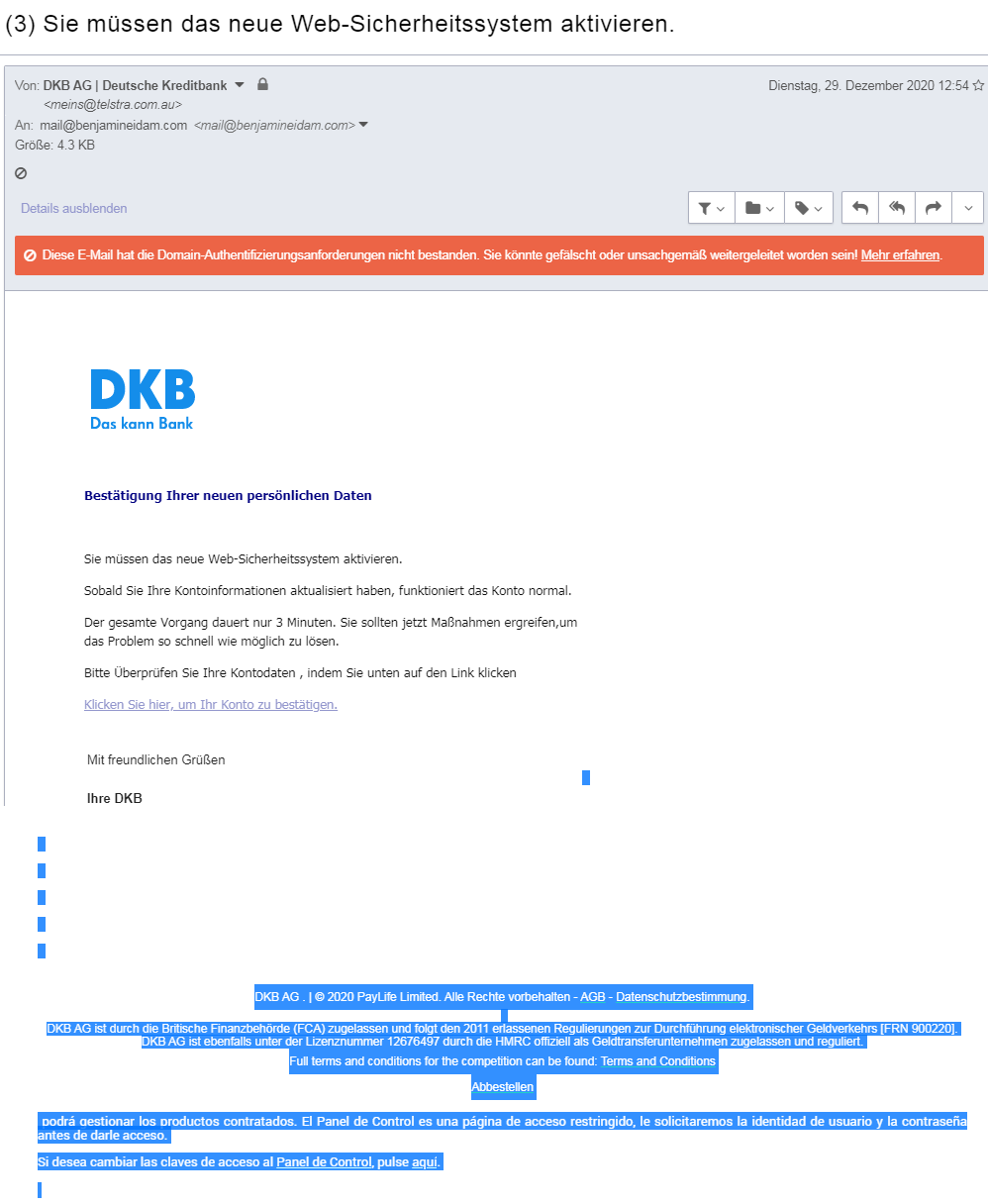
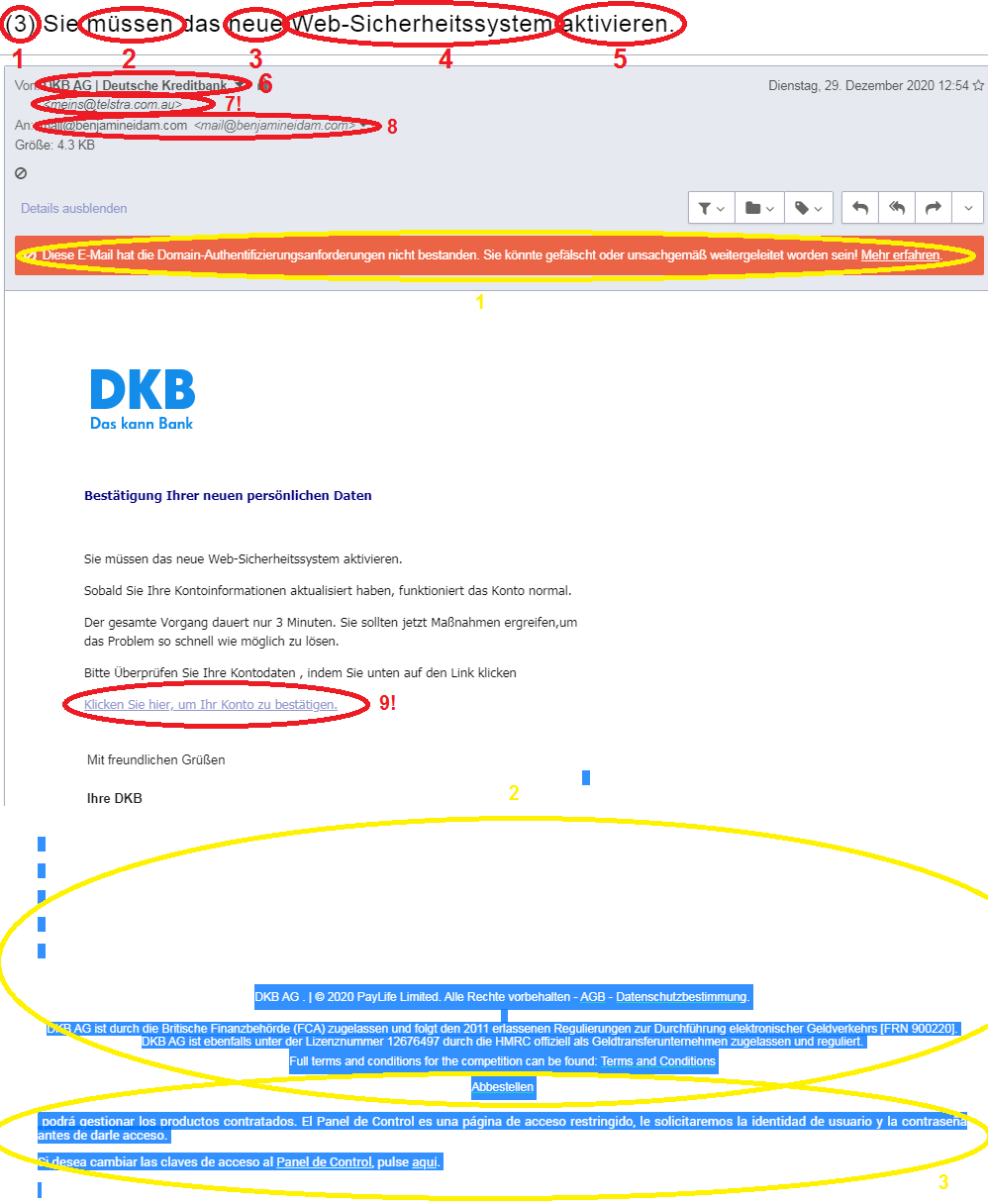
5. Die größte Gefahr im Internet vermeiden / Phishing
Phishing ist die beste Waffe des digitalen Verbrechens. Denn sie ist extrem erfolgreich, kinderleicht anpassbar, problemlos skalierbar und richtig gemacht nicht nachverfolgbar.
Anatomie einer Phishing-Mail. Bildquelle und weitere Informationen: https://benjamineidam.com/phishing-mails
6. Identitätsmissbrauch
Der Missbrauch digitaler Identitäten ist eine weitere asymmetrische Angriffsmethode.
Der Aufwand ist, je nach Szenario, nahezu verschwindend gering. Der Schaden allerdings kann gigantisch sein; Jobverlust, Scheidung, Stress mit dem persönlichen Umfeld und hohe Geldverluste sind da noch die verhältnismäßig harmlosen Auswirkungen. Suizid die schlimmste.
Das Thema ist sehr komplex und individuell unterschiedlich zu behandeln, zwei gute Startpunkte um auf einen Blick zu sehen, ob man in Gefahr ist oder eigene sensible Daten bereits in den falschen Händen sind, sind diese beiden Seiten:
Bildquelle und weitere Informationen: https://www.heise.de/hintergrund/Identitaetsklau-nimmt-zu-und-wird-raffinierter-4305746.html?seite=all
Neben dem “klassischen” Identitätsmissbrauch gibt auch den “synthetischen” Identitätsdiebstahl- / Missbrauch. Bei diesem wird aus der eigenen digitalen Identität eine künstliche gemacht und damit Schaden verursacht. Mehr dazu im Abschnitt künstliche Intelligenz.
7. Mental Models
Mental Models sind kontextuelle Blickwinkel auf Situationen. Zum Beispiel sieht ein Botaniker in einem Wald einen biologischen Schatz und überlegt sich Schutzstrategien. Ein Agrarspekulant hingegen sieht im selben Wald einen monetären Schatz und überlegt sich Verkaufsstrategien.
Mentale Modelle können extrem wirksam bei Cybersecurity-Problemen sein, allen voran Social Engineering-Herausforderungen.
1. What are the 3-5 biggest mistakes newcomers make when they start cybersecurity?
- Influenced by the vendors, trainers and research papers
- Choosing a product from external recommendation, endorsement instead of looking at it from his/her own use case
- Missing key success criteria during PoC (Proof Of Concept)
2. What mistakes are also common among professionals?
- Heavily dependent on technology
- Poor focus on people and processes
- Considering it as a cost center than a value creation center
3. What 3-5 actions bring the greatest impact to cybersecurity?
- Continuous upskilling
- Finding a right mentor
- Periodic assessment of skills applied VS only learned
Führungsetage
Der effektvollste Teil der Cybersecurity
Manager, Leiter und Chefs verschiedener Bereiche, Gruppen und Abteilungen sind eine Cybersecurity-Kategorie für sich. Technisch gesehen sind sie zwar ebenfalls Menschen und Mitarbeiter, also auch genauso anfällig.
Praktisch sieht es allerdings anders aus: Für Menschen mit Verantwortung und Berechtigungen innerhalb von Unternehmen gibt es ein eigenes “Angriffs-Universum”.
Dementsprechend müssen die Verteidigungsstrategien hier grundlegend überdacht / angepasst werden.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Regelmäßige Schulung / Test
Für Personen mit Verantwortung, Sicherheitsfreigaben und Zugriff auf sensible Informationen gilt noch mehr als für “den Rest” der Belegschaft: Das Härten der eigenen Handlungsweisen hat für die Cybersicherheit des gesamten Unternehmens einen sehr hohen Stellenwert.
Der „1½ Ansatz“ funktioniert dabei sehr gut: Das sichere und routinierte Handeln sollte entweder auf Platz 1 oder maximal Platz 2, je nach Tätigkeit stehen. Bei YMYL-Bereichen auf Platz 1, bei allen anderen individuell zu entscheiden.
Heißt: Bevor zum Beispiel ein Bankmanager seinem Alltag nachgeht, muss er zuallererst cybersicher sein. Ansonsten kann er seinen Job schlicht nicht sicher ausführen.
2. Stress- und Pentests als Routine
Aufgrund des Triviums Verantwortung, Freigaben und Zugriffen sind nicht nur Schulungen, sondern auch die regelmäßige Simulation des digitalen Ernstfalls sehr wichtig und sogar wichtiger als für “normale” Mitarbeiter.
Eine gute Faustregel lässt sich hier aus der “Effekt-Proportion” ableiten: Proportional zur maximalen Wirkung der eigenen Handlung müssen die Ergebnisse und die Regelmäßigkeit von Stresstests sein. Hat ein durchschnittlicher Mitarbeiter zum Beispiel eine maximale Verfügungsgewalt über 10.000 $ bevor es zur Gegenprüfung kommt, ein Manager aber von 1.000.000 $, dann sollten die Ergebnisse dementsprechend sein.
Ab einem Faktor ≥ 10 sollten die Ergebnisse mindestens 90 % bei den letzten > 3 Tests betragen. Ab dem Faktor ≥ 100 sogar > 95 % bei den letzten > 3 Tests.
Weitere Taktiken wie diese im Abschnitt Gewohnheiten.
3. Keine letalen Daten in der Öffentlichkeit
Geheime Dokumente auf einem Rechner zu öffnen, dessen Bildschirm zu einem öffentlichen Platz gerichtet ist oder Daten wie Kreditkarteninformationen lautstark ins Telefon sprechen. Es gibt Situationen, die sich schnell in Gefahrenquellen verwandeln können. Social Media insgesamt ist wie ein riesiger Honeypot und eine Einladung dazu.
Faustregel: YMYL-Daten nur hinter verschlossenen Türen heißt in einer sicheren Umgebung verwenden und bearbeiten.
4. Angriffsflächen bewusst machen
Es gibt buchstäblich unendlich viele Angriffsmöglichkeiten auf jedes beliebige digitale Ziel. Ein Rechner ist beispielsweise angreifbar via Internet, lokalem Netzwerk, Speichermedien, Eingaben, Programmen, Hardware-Hacks etc. Und Rechner sind buchstäblich überall dieser Tage, wie allein der Trend “Smart Home” zeigt.
Eine gute Faustregel um Angriffsvektoren zu identifizieren und einzudämmen:
Die ehrliche und so vollständig wie möglich beantwortete Frage: “Was ist mir wichtig?” Das kann alles von der eigenen Familie über den Neuwagen bis hin zum Investmentfonds sein.
Die Antwort auf die Frage “Was tue ich aktuell, um die Antwort auf 1. zu schützen?”
Die Antwort auf die Frage “Was kann ich tun, um die Antwort auf 1. zu schützen?” (Für ein möglichst breites Antwortspektrum hast du diese Seite)
Die Antwort auf die Frage “Ergibt es Sinn, weitere Maßnahmen zu ergreifen? Und wenn, welche?”
Hier ergibt es nahezu immer Sinn, sich gemeinsam mit einem Profi Optionen und Maßnahmen anzuschauen und umzusetzen. z. B. via individuellen Schulungen und Coachings.
5. Der Stich ins Herz / Phishing
Selten wird der Unterschied zwischen Prioritätszielen und “normalen” Mitarbeitern so klar wie beim Phishing. Denn Phishing + Unternehmens-VIPs = Spear- bzw. Whale-Phishing. Spear- bzw. Whale-Phishing bedeutet auch E-Mails, die falsch behandelt Angreifer ins Zielsystem lassen. Doch Spearphishing-Mails sind ein anderes Kaliber. Während normale Phishing-Mails mehr oder weniger generisch sind, mal falsch übersetzte Anhänge haben, mal der Absender nicht zum Inhalt passt usw. sind Spearphishing-Mails heimtückisch. Oft mit wochen- oder gar monatelanger Vorbereitung und exakter Maßanfertigung auf ihr Ziel. Meist werden dabei Präferenzen und Vorlieben des Ziels ausspioniert, vertrauenswürdige Proxys gehackt und von dort aus die Mail abgeschickt etc.
Eine Phishing-Mail von einer Mail zu unterscheiden ist wie eine Blume von einem Busch zu unterscheiden. Für die meisten relativ einfach und schnell machbar.
Eine Whalephishing-Mail hingegen ist wie eine blaue blume von einer anderen blauen Blume zu unterscheiden. Machbar, wenn man ein wenig Hintergrundwissen in Botanik hat. Ansonsten potenziell giftig.
Bildquelle und weitere Informationen: https://www.wud.de/it-security/7-gefaehrliche-phishing-angriffsmethoden-die-sie-kennen-muessen/
6. Identitätsmissbrauch
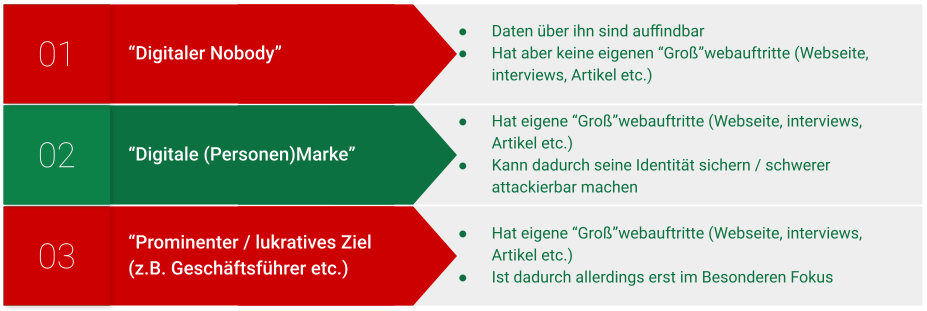
Wie bereits weiter oben angesprochen ist Identitätsmissbrauch ein wichtiger Bestandteil der Cyber-Kriegsführung. Und rein logisch ist eine Identität mit mehr Reputation, also zum Beispiel ein Manager, Geschäftsführer oder auch Prominenter ein lohnenderes Ziel, als ein “normaler” Mitarbeiter, richtig?
Fast. Das lässt sich nicht pauschal sagen. Es gelten die “Goldilocks-Conditions” der Cybersecurity:
Bildquelle: Eigene Grafik
Heißt: Der “digitale Niemand” ist angreifbar und lohnenswert. Prominente und ähnliche lukrative Ziele ebenfalls.
Doch die Herrschaft über die eigene digitale Marke erschwert Angreifern den Erfolg vor allem bei Rufmordkampagnen, Stalking und ähnlichen Identitätsmissbrauchs-Versuchen enorm.
Mehr zu synthetischem Identitätsmissbrauch im Abschnitt künstliche Intelligenz.
7. Mental Models
Wie bereits oben angesprochen sind die richtige mentale Einschätzung, Haltung und daraus hervorgehende Handlungsoptionen im Bereich Cybersecurity überlebenswichtig.
Für die wichtigsten Mitarbeiter eines Unternehmens gelten dabei noch zwei besondere Regeln:
Bei allen berufsrelevanten Themen muss der Gesprächspartner besonders vertrauenswürdig sein. Es gibt verschiedene Schemata und Checklisten dafür, ein solides Bauchgefühl bei genügend Erfahrung ist ein guter Start.
Je potenziell ertragreicher und/oder waffenfähig der eigene Wissensstand und Arbeitsplatz, desto wahrscheinlicher ein Angriff auf den Inhaber von diesem.
Unternehmen sind die zentralen Ziele der Cyber-Angriffe, denn sie sind der zentrale Wertschöpfer der Wirtschaft. Hier gelten 3 Faustregeln:
Je höher der Nutzwert, desto lukrativer ein Angriff.
Je weiter entfernt von Cybersecurity-Expertise, desto lukrativer ein Angriff.
Je näher an kritischen Infrastrukturen, desto lukrativer ein Angriff.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Sicherheitsstufen kennen und einsetzen
Zugriffe sinnvoll zu steuern kann eine einfache aber asymmetrisch effektive Sicherheitsmethode sein. Ein guter Startpunkt und/oder Abgleich dabei kann die Normungs-Roadmap der DIN sein. Diese gemeinsam mit allen (relevanten) Mitarbeitern zu gestalten, kann zusätzlich der Sicherheitskultur helfen.
Die Traffic Light Protocoll (TLP) Stufen der Allianz für Cybersicherheit sind ein weiteres gutes Framework zur Orientierung der eigenen Sicherheitsabschnitte. Bildquelle und weitere Informationen: https://www.allianz-fuer-cybersicherheit.de/Webs/ACS/DE/Home/_/merkblatt_behandlung_vertraulicher_informationen.html?nn=145680#download=1
2. Mit Profis zusammenarbeiten
Dieser Punkt ist vermutlich (hoffentlich) kein Geheimtipp: Es ergibt vor allem bei der Cybersicherheit des eigenen Unternehmens Sinn, mit Experten verschiedener Schwerpunkte zusammenzuarbeiten. Bzw. deren Updates auf dem Schirm zu haben.
Viele der hier genannten Maßnahmen akkumulieren sich zu mehr als der Summe Ihrer Teile. Es gilt wie im Kapitel-Intro geschrieben: Je weniger lohnenswert ein Ziel ist, weil es vergleichsweise zu gehärtet ist, desto unwahrscheinlicher ist ein Angriff, weil nahezu unendlich viele andere, einfachere Ziele vorhanden sind.
Heißt: Jede Sicherheitsmaßnahme erhöht die Sicherheit auch ohne tatsächlichen Angriff, einfach, weil sie den Angriffs-Aufwand erhöht und damit die Angriffs-Wahrscheinlichkeit senkt. (Dies gilt natürlich nicht für gezielte Angriffe explizit gegen dein Unternehmen aufgrund eines Auftrages etc.)
4. Die Vokabeln kennen
Die technische Vokabelliste ist endlos und die wichtigsten Vokabeln hoffentlich hier bereits abgedeckt. Auf der Seite der Social Engineering Angriffe gibt es allerdings noch ein paar Kernbegriffe:
Diese Liste erhebt selbstverständlich keinen Anspruch auf Vollständigkeit. Viel eher kann sie als hilfreiche, konzeptionelle Ergänzung und Inspiration betrachtet werden.
5. Den “Krebs-Regeln” folgen
Wenn ich nur einen Cybersecurity-Experten benennen müsste, der den meisten, kontinuierlichen und verständlichen Wert bringt, es wäre Brian Krebs.
Von ihm sind auch die drei wundervollen “Krebs-Regeln”:
1. “If you didn’t go looking for it, don’t install it!” – Wenn du nicht danach gesucht hast, installiere es nicht!
2. “If you installed it, update it.” – Wenn du es installiert hast, update es!
3. “If you no longer need it, remove it.” – Wenn du es nicht länger brauchst, lösche es!
Die wichtigsten Begriffe und deren Eigenschaften und Bedeutung sollte jeder mit Zugriffsberechtigung zu einem Gerät mit Display kennen. Das gilt auch für ausschließliche Zugriffsberechtigungen im Notfall.
Die meisten der dort genannten Tipps findest du in diesem Guide auch schon ausgeführt.
8. E-Mails gegen Bots sichern
Du möchtest verhindern, dass Unternehmens-E-Mail Adressen automatisch von Programmen gesammelt, verknüpft und dann angegriffen werden. Dazu lohnt es sich diese auf den eigenen Webauftritten zu härten (Und generell so selten wie möglich im Netz zu posten).
Mögliche Wege dazu sind zum Beispiel:
“@” durch “(ät)” oder ähnliches ersetzen. Beispiel: xyz(ät)abc.de
Zusätzliche Zeichen hinzufügen, um die E-Mail-Adresse zu verschleiern. Beispiel: xyz@remove-this.abc.de
Die Mailadresse nur als Bild einblenden. Beispiel: Siehe Bild.
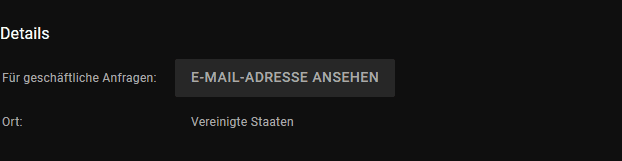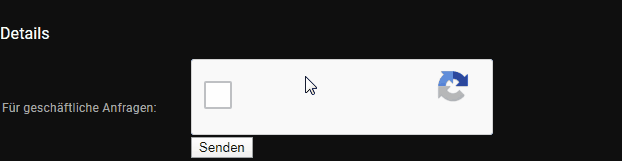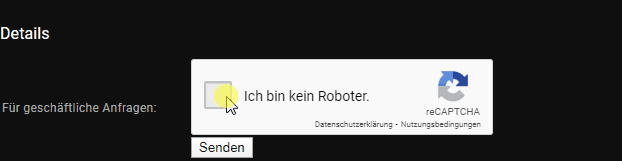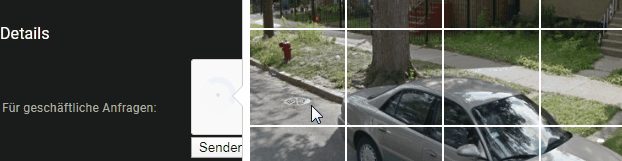
Ein Captcha oder Verschlüsselung vorschalten. Beispiel: YouTube:
Captchas können gute Hürden gegen Bots sein. Quelle: Eigener Screenshot.
9. Sicherheits-Frameworks kennen und nutzen / NIST-Framework
Das NIST-Framework ist das beste Framework als Startpunkt zur Prüfung der eigenen Sicherheitsprozesse. Die wichtigsten weiteren findest du hier.
Bildquelle und weitere Informationen: https://www.nist.gov/cyberframework/framework
10. Die eigene Verteidigung prüfen (professionell)
Auf Penetrationstests oder kurz “Pen-Tests” bin ich weiter oben bereits eingegangen. Bei größeren Unternehmen / besonderem Augenmerk auf Sicherheit ergeben derartige Tests durch externe Dienstleister Sinn. Soweit man mit Werkzeugkästen und Tools wie Kali auch kommt, für einen “echten” Pentest braucht es firmenexterne Experten. Kombiniert mit dem kontinuierlichen Austausch mit Experten erreicht man so ein sehr gutes Sicherheitslevel.
11. Passwortstärken testen
Oft “Password Auditing” genannt. Cain & Abel und John the Ripper sind die ersten Adressen dafür. Mehr zu sicheren Passwörtern und dem richtigen Umgang mit diesen findest du weiter oben.
12. Netzwerksicherheit prüfen
Hier bieten sich interne Audits, Stresstests und/oder Prüfungen mit Tools wie zum Beispiel Netstumbler, Aircrack oder KisMAC an.
13. Zugriffsrechte einschränken
Wie bei den Schlüssel-Vokabeln und anderen Punkten bereits angesprochen, ergibt es Sinn “Schotts” zu implementieren.
So das nicht jeder Mitarbeiter, Gast usw. die gleichen Zugriffe hat. Kann manchmal hinderlich bis ärgerlich sein, rettet dafür aber ggf. das Unternehmen.
Denn ein infizierter Bereich ist besser als, wenn das ganze Schiff brennt. Hier kann man viel von der Marine lernen.
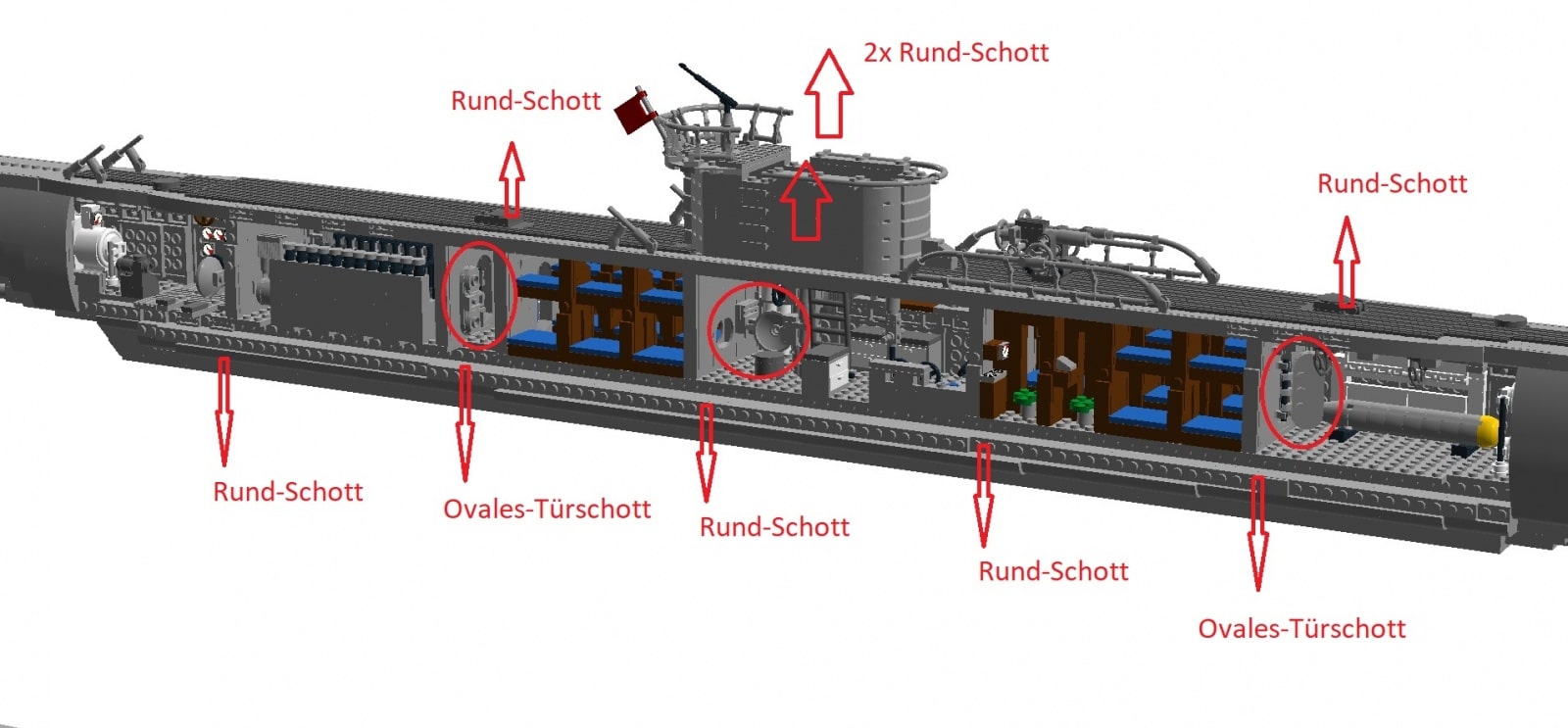
Dieser Forenuser achtet auf Sicherheit wie diese schöne Grafik seiner eingebauten Schottwände zeigt. Bildquelle und weitere Informationen: https://www.1000steine.de/de/gemeinschaft/forum/?entry=1&id=451260&lastid=1
14. Personenkontrollen- / Sperren
Stichprobenartige, unangekündigte Taschen-, System- und Personenkontrollen können sehr wirksam sein. Durch die reine Wahrscheinlichkeit dieser Möglichkeiten verändert sich das Sicherheitsempfinden.
Diese Taktik sollte, je nach Umfang, mit Vorsicht getestet und erst nach positiven Ergebnissen weiter eingebaut werden. Denn in beinahe jeder Kultur außerhalb von Russland oder China gehört diese Art der Überwachung und Eingriff in die persönlichen Rechte nicht zum Alltag.
15. Zeitgemäße Hardware einsetzen
Die NASA kann dank Problemen mit der Hardware-Kompatibilität älterer und aktueller Systeme nicht korrekt arbeiten. Dieses Problem ist allerdings kein rein interstellares, meist sind irdische Systeme betroffen. Veraltete Hardware kann ggf. keine aktualisierte Software einsetzen, bringt Schwachstellen in inhomogene Systeme und führt zu Mehraufwand der automatisch zu weiteren Schwachstellen führt. Da Hardware die Grundlage für sämtliche Aktivitäten und Sicherungen ist, sollte hier entsprechend fundamental gearbeitet werden.
16. Digitaler Hagelschlag / DDOS
DDoS, der “Distributed Denial of Service” ist für Angreifer gegen ungeschützte Systeme einer der leichtesten Wege, ein Unternehmen anzugreifen. Dabei werden die mit dem Internet verbundenen Systeme eines Unternehmens, meist die Webauftritte, attackiert.
Die Angreifer “müllen” die Systeme so lange zu, bis diese kapitulieren und damit nicht mehr verfügbar sind. Der populärste Service zum Schutz gegen DDOS-Angriffe ist Cloudflare.
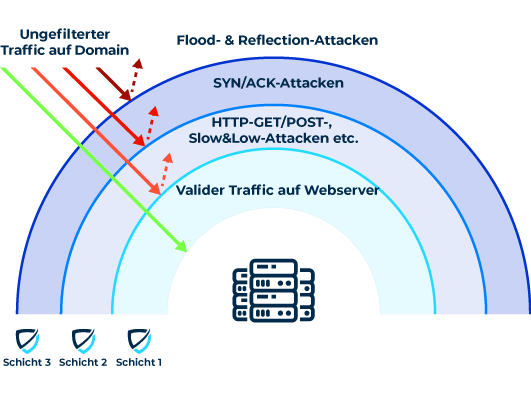
DDOS-Angriffe können verschiedene Schichten / Phasen haben. Bildquelle und weitere Informationen: https://www.myrasecurity.com/de/was-ist-ein-ddos-angriff/
17. Unbestechliche Türsteher / Injections
Injections, allen voran SQL-Injections, kurz “SQLi’s” sind der Missbrauch von Programmen durch das Einschmuggeln von Fremdcode- / Befehlen.
Bildquelle und weitere Informationen: https://owasp.org/www-project-top-ten/2017/A1_2017-Injection
Firmenkultur
Der unterschätzte Teil der Cybersecurity
Eine “Quasi-Diktatorische Führung mit einem Klima der Angst” in einem Unternehmen ist das Traumszenario für jeden Angreifer.
Aber auch “Aneinander vorbei-gearbeitete Quasi-Anarchie” bringt nichts.
In kurz: Nur wenn das Unternehmen als Team agiert, kommt von außen schwer jemand einen Keil in dieses getrieben. Mitarbeiter jeder Ebene andernfalls gegeneinander auszuspielen und zu manipulieren ist sonst ein Kinderspiel.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Idea Meritocracy
Eine Ideen-Meritokratie bezeichnet das Prinzip, dass immer die beste Idee gewinnt. Egal von wem sie kommt.
Diese von Investor Ray Dalio und seinem Unternehmen Bridgewater geprägte und gelebte Idee der Ideen-Meritokratie ist zeitgleich eine Cybersecurity-Maßnahme. Denn unsinnige und sicherheitsgefährdende Phänomene wie Mobbing, Machtspielen etc. werden damit fundamental entschärft. Und gewertschätzte Mitarbeiter hegen keinen Groll und sind nicht ignorant gegenüber potenziellen Gefahren.
Ein Shitstorm ist aus Cybersicherheits-Perspektive noch eines der leichteren Szenarien zu denen Mitarbeiter führen können. Bildquelle und weitere Informationen: https://www.talkwalker.com/de/blog/krisenmanagement-wie-man-sich-auf-einen-shitstorm-vorbereitet
2. Grundverständnis der Evolutionsbiologie
Menschen handeln menschlich. Soweit keine Sensation. Doch was das im (Arbeits)Alltag tatsächlich bedeutet ist einerseits noch nicht lang wissenschaftlich fundiert bekannt. Und andererseits noch viel seltener beachtet.
Das kann sich nicht nur organisatorisch, sondern auch sicherheitstechnisch als Gefahr herausstellen.
Dinge wie:
Entscheidungsmüdigkeit (Je mehr getroffene Entscheidungen, desto weniger Energie für jede weitere Entscheidung)
Stammeszugehörigkeit (Der Mensch ist ein Gruppen-Tier, was ausgenutzt werden kann)
Kollektivschuld (Abgabe von Verantwortung bei Ausführung einer Handlung)
Usw.
Bildquelle und weitere Informationen: https://jamesclear.com/willpower-decision-fatigue
3. Extreme Ownership
Extreme Ownership bedeutet, dass sich jeder Mitarbeiter so verhält, als wäre er der Eigentümer des Unternehmens. Grob übersetzen kann man es mit “extremer Verantwortung”. Eine Firma bei der allein dieser Wird gelebt wird, ist ungleich sicherer gegen Social Engineering etc. aufgrund von Proaktivität, selbstverständlicher und gegenseitiger Unterstützung, Ursachenbekämpfung direkt an der Quelle etc.
4. Die Gruppe als Einheit / Teambuilding
Spätestens der Cyberkrieg macht aus zusammengewürfelten Mitarbeitern zwangsläufig ein Team. Oder genau genommen: sollte es besser.
Denn das Team wird angegriffen, ob es sich als Team fühlt oder nicht.
Wenn ein Mitarbeiter den anderen nicht fragen oder seine Gedanken teilen kann, fehlt eine wesentliche Schutzschicht gegen jedwede Social Engineering Attacke. Deshalb: Teambuilding ist eine Cybersecurity-Maßnahme.
Security Advisor, Investor and President, CISO & Head of Services of KLC Consulting, Inc.
What are the 3-5 biggest mistakes newcomers make when they start cybersecurity?
1) Start planning cybersecurity projects without understanding the company's business and without involving business teams
- Different business has different attack vectors and threat actors. For example, you need to protect the user's privacy, user identity, access, and transaction integrity if you are in banking. If you are in the defense industry, your priority will be protecting intellectual property, sensitive government information, supply chain security, and manufacturing facilities. There are also regulations to comply with.
2) Communicate to business people without a common language
Newcomers tend to use many technical terms with business people, which degrade the relationships with business groups. New cybersecurity professionals should learn to simplify the technical terms to a common language that business people will understand. It is a better way to build trust and show that you are helpful to them.
3) Not ask questions when getting stuck with a problem -
Ask for help. People are willing to help.
The worst thing a professional can do is NOT ask questions when getting stuck with a problem, then make up excuses on why they can't complete a project.
2. What mistakes are also common among professionals?
1) Security pros tend to make too many assumptions when working with business teams and not ask questions. For example, assuming business people will like the new security solutions to be put in place, only to find out that business teams hated it after the deployment.
2) Stop learning is a big mistake. Technologies are advancing very fast. Security professionals must keep up with the technologies and trends; otherwise, they will get left behind.
What 3-5 actions bring the greatest impact to cybersecurity?
1) Conduct short and frequent security awareness training to all employees.
2) Do regular independent vulnerability assessment and penetration testing to address the company's unknown risks.
3) Enforce multi-factor authentication on all systems, on-prem and cloud. ID and Password alone are not sufficient.
4) Enhance identity and access management. Remove unnecessary privileges after a job transfer. Terminate accounts after job termination.
5) Get threat intelligence. The company should assign at least one security team member to track daily security news for new vulnerabilities, new threats and exploits, new emergency patches, etc.
Zulieferer
Der übersehene Teil der Cybersecurity
Ein oftmals übersehener Teil der Sicherheitskette ist das “davor” und “danach”: Supply-Chain-Attacks.
Es bringt die dickste Festung nichts, wenn der Karawan aus dem Nachbardorf ein trojanisches Pferd hinter die Mauern bringt.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Sicherheit von Anfang bis Ende / SSL
SSL-Zertifikate machen aus Webseiten “Rohre” zwischen Sender und Empfänger, in die nicht hineingeschaut werden kann. Sie sichern also die Verbindung von einem Ende zum anderen.
Ein ähnliches Prinzip verfolgt die Quantenkryptografie. Obwohl theoretisch gesehen unknackbar da auf Naturgesetzen basierend, brauch sie noch etwas Entwicklungszeit bis zur Praktikabilität. Zur Sicherheitsplanung ergibt es aber Sinn, diese auf dem Schirm zu haben.
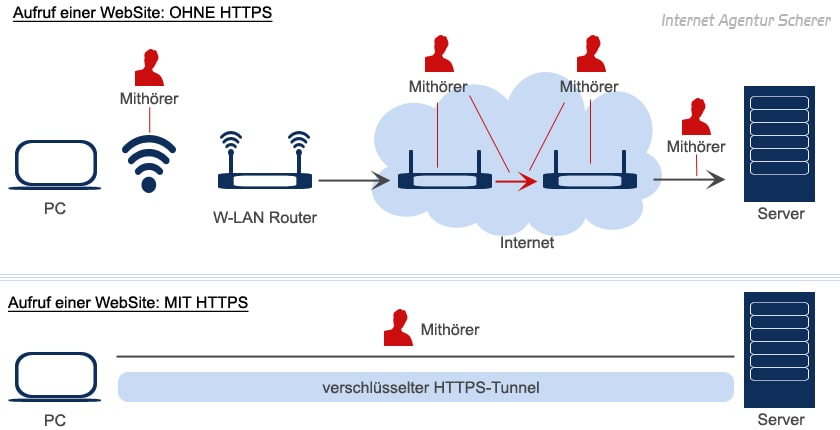
Bildquelle und weitere Informationen: https://www.internetagentur-scherer.de/index.php/blog/82-https-verschluesselung-mit-sicherheit-punkten
2. Schnittstellen / APIs
APIs, „Application Programming Interfaces“, sind Schnittstellen der eigenen Software zur Software anderer Nutzer, Programmierer oder Unternehmen. Diese zu sichern hat eine hohe Priorität, da die andere Seite der Schnittstelle nicht kontrolliert werden kann.
Beispiel-Stationen die rundum gesichert sein müssen. Bildquelle und weitere Informationen: https://en.wikipedia.org/wiki/Supply_chain_attack
3. Fremdzugänge- und Rollen (managen)
Nahezu jedes (größere) Unternehmen hat Lieferketten, “Vorarbeiten” oder ähnliche Verknüpfungen mit anderen Firmen. Alles vom “klassischen” Zulieferer bis hin zu Software-Testern im Anschluss an eine Entwicklung.
Da diese Verknüpfungen einer in sich geschlossenen Festung Sicherheitslücken hinzufügen können, sollte man diese auf dem Schirm haben und entsprechende Maßnahmen umsetzen.
Ein guter Startpunkt ist das Aufzeichnen sämtlicher Kontaktpunkte und ein anschließendes Brainstorming über mögliche Sicherungsmaßnahmen. Bei der Implementierung können Profis dann ggf. helfen.
Im Bereich Cybersecurity kann dieses Versäumnis profunde Probleme nach sich ziehen.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Spezialglas einsetzen
Dein Passwort kann aus deinem Fenster gelesen werden: Jedes Klicken auf einer Tastatur und jedes gesprochene Wort erzeugt eine spezifische Frequenz. Diese Frequenz wird von manchen Oberflächen, z.B. Fensterscheiben aufgenommen und erzeugt eine spezifische, mess- und interpretierbare Vibration.
Diese Sprech- und Tipp-Vibrationen können unter den richtigen Umständen gesammelt und verarbeitet werden.
2. Nicht-identifizierbare Räumlichkeiten nutzen
Es gibt Signalquellen wie zum Beispiel Stromleitungen, die individuelle und eindeutig zuordenbare Muster erzeugen. So können zum Beispiel aus dem Hintergrundrauschen von Videobotschaften Standorte ermittelt werden.
Was mit dem Austausch einer Schale Kekse gegen eine mit Äpfeln klappt, wirkt sich auch auf die Cybersicherheit aus.
Poster, Schreibtischunterlagen, jederzeit gut sichtbare Aufbewahrungsorte für Hardware-Schlüssel usw. können die sichere Option zur einfachsten Option machen. Und damit die Cybersicherheit ohne Mehraufwand zum Standard machen.
Ein guter Startpunkt zum Design der Entscheidungsarchitektur ist die Frage “Für welchen Zweck wurde dieser Raum designt?” Eine Anleitung findest du hier: https://benjamineidam.substack.com/p/schwellen
4. Die Untiefen des Internets verstehen
Gestohlene Daten, Accounts etc. landen sehr häufig im Darknet und werden dort verkauft. Manche Daten werden aus dem Deep Web gestohlen und dann im Darknet angeboten.
Doch was sind Dark- und Deep Web überhaupt? Auf einen Punkt:
Darknet: Internetabschnitt, der nur mit spezieller Software betreten werden kann. (TOR etc.)
Deep Web: Internetabschnitte, zu denen kein Link führt. Kennt man den Link, hat man Zugriff, ansonsten ist die jeweilige Seite (theoretisch) unsichtbar.
Das Thema ist sehr komplex, aber das Verständnis dieser beiden Schlüsselbegriffe bringen bereits viel Nutzen.
Bildquelle und weitere Informationen: https://medium.com/@smartrac/the-deep-web-the-dark-web-and-simple-things-2e601ec980ac
5. Kartierungsservices richtig nutzen
Programme wie Google Maps oder Open Street Maps sind im Alltag extrem praktisch. Doch können sie im Rahmen einer OSINT-Analyse benutzt werden um gezielt Angriffswege herauszufinden. Hier ergibt es Sinn, mit Experten mögliche Maßnahmen zu erörtern.
6. “Sicherheits-Flure” einsetzen
Vor allem bei militärischen und geheimdienstlich genutzten Anlagen gibt es manchmal “Sicherheits-Flure. Das sind Korridore voller Hightech wie Tiefen-Retina-Scannern, Ganganalyse-Tools, Körperwärme-Scannern etc. Das Ziel dieser Gänge ist es, in Echtzeit und mit nahezu 100%iger Sicherheit die jeweilige Person identifizieren zu können. Die Idee: Alles, was individuell ist, eignet sich zur Identifizierung. Und je größer die Kombination, desto schwerer ist es, irgendetwas zu fälschen. (Abseits direkten Hackings der Software)
Muss man nicht im eigenen Unternehmen einsetzen. Es ist aber gut die Möglichkeiten zu kennen um Entscheidungen zu treffen.
7. Security by Design
Security by Design ist ein holistischer, also ganzheitlicher Ansatz beim Bau von Software, allen voran Apps. Der beste mir bekannte Startpunkt ist dieser kostenlose, nur wenige Minuten dauernde Mini-Kurs von Google.
Bildquelle und weitere Informationen: https://playacademy.exceedlms.com/student/path/63550-security-by-design
Deutschlands bekanntester Hacker, Informatiker und Dozent u.a. in Barcelona und Frankfurt
1. Welche sind die 3-5 größten Fehler, die Neulinge machen, wenn sie mit Cybersecurity beginnen?
Wenn man Security macht, finde ich es enorm wichtig, Prioritäten zu setzen. Denn wenn man ein wie üblich viel zu kleines Budget vorgesetzt bekommt, bringt es nichts, sich im Detail mit einer Nebenanwendung zu beschäftigen, aber die Hauptanwendung offen für alles zu lassen. Natürlich wäre ein höheres Budget schöner, aber das ist selten der Fall.
Zudem fällt oft auf, dass Überprüfungen nur ein mal gemacht werden (falls überhaupt). Das reicht nicht, im besten Fall muss kontinuierlich gesucht werden. Und damit kommen wir zum dritten Punkt:
Nicht von der KI, sondern vor allem auch vom Menschen. Tools sind nett und gut und ermöglichen einen schnellen automatisierten Check beim Build, doch ist es nicht zu vergleichen mit einem manuellen Pentest, der mindestens ein Mal im Jahr gemacht werden sollte.
2. Welche Fehler sind auch unter Profis verbreitet?
Leider sind auch viele Profis von der eigenen Kompetenz zu sehr überzeugt, wie ich finde. Man muss sich eingestehen, dass man nicht alles kann und, dass eine Person immer weniger findet, als zwei.
Daher ist es wichtig, sich auch externe Hilfe zu holen. Je mehr man durchwechselt, desto mehr unterschiedliche Kompetenzen holt man ab.
3. Welche 3-5 Handlungen bringen die größten Effekte für die Cybersicherheit?
Die Mitarbeiter gelten noch immer als größtes Einfallstor für Schadware. Daher ist das wichtigste oft eine gute Mitarbeiter-Policy mit verpflichtendem Security KEy und Schulung für Social Engineering.
Ständiges Monitoring und regelmäßige Tests bilden einen weiteren fundamentalen Baustein, jedoch darf man nicht vergessen, dass Schadware auch von Partnern eindringen kann.
Das heißt, dass Partner und Zulieferer sicher sind, ist fast so wichtig, wie die eigene Sicherheit - auch wenn das eher nicht direkt so scheint.
Künstliche Intelligenz
Der alles verschlingende Teil der Cybersecurity
Künstliche Intelligenz (KI) ist seit einigen Jahren in aller Munde und in beinahe jedem Gerät aktiv.
KI ist die wahrscheinlich wichtigste Technologie dieses Jahrhunderts und wird dementsprechend auch die Cybersecurity noch mehr als einmal revolutionieren.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
1. Automatisierte Betrugserkennung
Künstliche Intelligenz wird immer besser darin Betrugsfälle, Unterschlagungen und Falschaussagen zu erkennen und entsprechend zu handeln. Egal ob bei Phishing, Kreditkartenbetrug, Ausweisfälschungen, Fake-Accounts etc. KI kann bei all diesen und weiteren Bereichen helfen. Ein guter Start zum Einsatz ist dieser Artikel.
Bildquelle und weitere Informationen: https://spd.group/machine-learning/fraud-detection-with-machine-learning/
2. Datenlecks in Lichtgeschwindigkeit erkennen
Vor allem Machine Learning lernt anhand (großer) Datenmengen und filtert Muster aus diesen heraus. Entweder mithilfe eines Menschen (supervised Learning) oder selbstständig (unsupervised Learning).
Bei großen, komplexen Datenströmen kann KI so in Echtzeit helfen, Datenlecks zu erkennen und Alarm zu schlagen.
3. Modellierung von Nutzerverhalten
Menschen sind Gewohnheitstiere. Und künstliche Intelligenzen arbeiten hervorragend mit Mustern. Kombiniert man diese beiden Variablen mit intelligenten Sensoren wie Gyroskopen, der Auswertung von Datenströmen und Überwachung wie durch Kameras etc. hat man eine hohe Sicherheit gegen Manipulation und Fälschungen.
Egal ob so in Echtzeit geprüft wird, ob der echte Nutzer an Gerät und Dokument x arbeitet. Oder ob verdächtiges Verhalten automatisch ausgewertet und weitergeleitet wird.
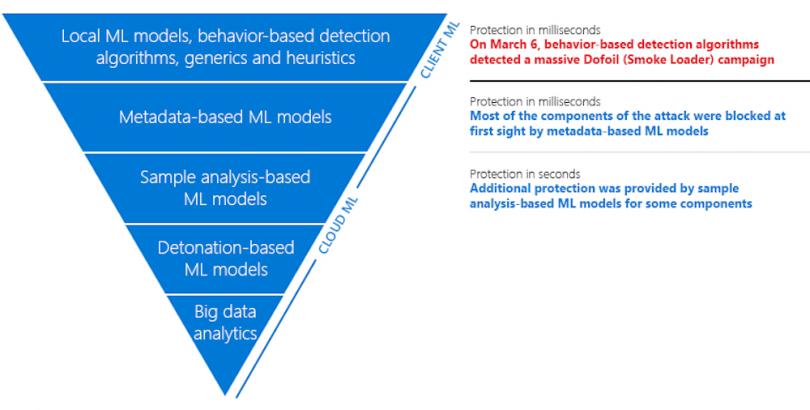
Bildquelle und weitere Informationen: https://www.microsoft.com/security/blog/2018/03/07/behavior-monitoring-combined-with-machine-learning-spoils-a-massive-dofoil-coin-mining-campaign/
Die meiste aktuelle Antiviren-Software basiert auf der Prüfung von Signaturen in Software. Neue Malware wird dann einfach mit diesen Signaturen abgeglichen. Doch bei z.B. reaktivem, also sich selbst veränderndem Code funktioniert das nicht. Künstliche Intelligenz kann hier eine entscheidende Rolle bei Echtzeitschutz spielen. Auch kann so zum Beispiel Ransomware entschärft werden, bevor sie Systeme verschlüsselt.
Erste größere Anbieter wie zum Beispiel Blackberrys Cylance füllen diesen spannenden Markt.
Bildquelle und weitere Informationen: https://usmsystems.com/ai-ml-in-cybersecurity-use-cases-examples/
5. Schwachstellenmanagement
Unternehmen stehen vor der Herausforderung die große Anzahl neuer Schwachstellen, auf die sie täglich stoßen, zu verwalten und zu priorisieren. Herkömmliche Techniken zum Schwachstellenmanagement reagieren erst auf Vorfälle, nachdem Hacker die Schwachstelle bereits ausgenutzt haben.
KI und Techniken des maschinellen Lernens können die Fähigkeiten von Schwachstellen-Datenbanken beim Schwachstellenmanagement verbessern.
Dies kann dazu beitragen, Unternehmen zu schützen, noch bevor Schwachstellen offiziell gemeldet und gepatcht werden.
Bildquelle und weitere Informationen: https://www.capgemini.com/wp-content/uploads/2019/07/AI-in-Cybersecurity_Report_20190711_V06.pdf
6. Identifizierung von Netzwerkbedrohungen
Um alle Datenströme die in- und aus der Firma fließen zu überwachen, braucht es viele Ressourcen. Von der Bewertung ganz zu schweigen.
Herauszufinden welche Datenpakete gefährlich sind und rechtzeitig zu reagieren ist eine der größten Herausforderungen der Cybersecurity. Künstliche Intelligenz kann hier immer besser unterstützen.
Unternehmen, wie Esentire spezialisieren sich verstärkt mit KI auf diese Felder.
7. E-Mail Monitoring
Wie in den Abschnitten zum Phishing bereits angesprochen sind Gesprächsverläufe via Mail einer der zentralen Knackpunkte jeder Cybersicherheit.
Machine Learning kann hier helfen Erkennungsgeschwindigkeit- und Genauigkeit zu erhöhen und via Natural Language Processing Texte analysieren.
Automatisierten Bedrohungen kann man nicht (mehr) allein mit manuellen Maßnahmen begegnen. KI und maschinelles Lernen helfen dabei, ein gründliches Verständnis des Website-Traffics aufzubauen und zwischen guten Bots (wie Suchmaschinen-Crawlern), schlechten Bots und Menschen zu unterscheiden.
KI ermöglicht die Analyse einer riesigen Datenmenge und erlaubt es Cybersecurity-Teams, ihre Strategie an eine sich ständig verändernde Landschaft anzupassen.
Firmen wie beispielsweise Netacea arbeiten an derartigen Services.
9. Vorhersage von Einbruchsrisiken
Künstliche Intelligenz kann in Echtzeit Anzahl, Einsatz und weitere Vektoren von Geräten, Benutzern, Software und mehr überwachen. Und zeitgleich mit den erlaubten Zugriffen und Protokollen abgleichen und wenn nötig Meldung abgeben.
Durch diese ständige Digital-Inventur können Algorithmen Schwachstellen und Angriffsziele erkennen und melden.
Wenn beispielsweise Computer mit hohen Zugriffsleveln an der Straßenseite eines Gebäudes stehen, in welchem regelmäßig unternehmensfremde Personen ein und aus gehen.
10. Verkürzung der Reaktionszeit
Künstliche Intelligenzen sind schneller als Menschen. Deshalb haben wir autonomes Fahren.
Um nahezu in Echtzeit Angriffe registrieren, kategorisieren und abwehren zu können kommt man in Zeiten von KI-gestützten Attacken nicht mehr herum. Firmen wie AtoS arbeiten an derartigen Lösungen.
Bildquelle und weitere Informationen: https://www.ponemon.org/
11. Verbesserung der (Datacenter) Architektur
Künstliche Intelligenz hat bereits zu unglaublichen Optimierungen beim Energieverbrauch von Datacentern geführt. Sie designt die komplexesten Strukturen automatisch. Auch zur Optimierung von Sicherheitsarchitektur wie Grundrissen, Ausrüstung wie Kameras etc. kann KI stark beitragen.
Googles Datencenter sind KI-optimiert. Bildquelle und weitere Informationen: https://www.wired.com/2012/10/ff-inside-google-data-center/
12. Automatisierte Gegenangriffe
Künstliche Intelligenz kann die Möglichkeiten der digitalen Verteidigung von reiner Defensive und Reaktion auch in die Offensive Aktion bringen. So können Angreifer durch lernende Algorithmen ausgespäht und ihre Identität entschlüsselt werden. Und die Ergebnisse durch ein kleines bisschen Zusatzcode direkt an die zuständigen Behörden geleitet werden. In Echtzeit.
In der Geschichte des “Schwert gegen Schild, Einbrecher gegen Verteidiger” bei der die Verteidigerseite bisher immer zur Reaktion verdammt war, ändert sich jetzt das erste Mal etwas.
13. AI Sandboxes
Wie ich weiter oben bereits angesprochen und in einem Artikel für die Societybyte näher ausgeführt habe, werden “KI Sandkästen” immer wichtiger.
Denn nur eine intelligente simulierte Umgebung kann mit intelligenten, sich selbst verändernden Algorithmen Schritt halten.
14. Reverse-Blackbox
KI kann auch intelligente Algorithmen prüfen und “den Wasserfall rückwärts hinauf” klettern um zu testen, ob es Schwachstellen gibt. Sofern Zugang zur Angreifer-KI besteht, kann die eigene KI deren Schichten des neuronalen Netzwerkes rückwärts entlang gehen und so den Angriffs-Algorithmus dechiffrieren. Basierend darauf ist es dann ein leichtes, Gegenmaßnahmen zu ergreifen.
Bildquelle und weitere Informationen: https://read.deeplearning.ai/the-batch/
15. Identitätssicherung
Künstliche Intelligenz kann zum Beispiel durch Reverse Image Search, Sentimentanalyse oder Tools wie Virality Maps verhindern, dass die eigene Identität digital missbraucht wird.
Bildquelle und weitere Informationen: https://read.deeplearning.ai/the-batch/issue-75/
17. KI als helfende Hand
Künstliche Intelligenz kann als permanenter Partner in der eigenen digitalen Verteidigung eingesetzt werden. Zum Beispiel um Fehlerquellen im eigenen Code zu finden, Vorschläge für Hacks / Schwachstellen zu machen oder Hinweise zu möglichen Problemen zu geben.
Gewohnheiten
Der wichtigste Teil der Cybersecurity
Die meisten nichttechnischen Tipps und Ansätze in der Cybersicherheit haben einen suboptimalen Startpunkt. Sie gehen davon aus, dass genug Angst und/oder Verständnis automatisch zur richtigen Handlung führt.
Doch der Mensch ist effizient. Menschen tun immer das routinemäßig, was am einfachsten, energiesparendsten ist.
Deshalb ist es elementar wichtig, gezielt Gewohnheiten zu härten. Denn nur Sicherheit die zur Routine geworden ist, ist wirklich Sicherheit.
Kostenlose Anleitungen zum sofortigen Einsatz sowie Updates kannst du dir hier herunterladen:
In Internet und Digitalraum gilt die “türkische Basar” Regel: Prinzipiell misstraue der gesamten Erfahrung und jeder Interaktion mit einem anderen User.
Je mehr potenzieller Wert im Raum steht, desto stärker sollte die Schuldvermutung als “Default Mode” berücksichtigt werden: Jemand möchte dich angreifen oder zumindest manipulieren, bis das Gegenteil bewiesen ist. Es gibt zwei Möglichkeiten zu dieser Art von “Erfahrungs-Bewusstsein” zu kommen:
Jahre- und Jahrzehntelange Erfahrung und Lernen daraus.
Arbeit mit Experten.
Zusätzlich hilft ein Grundverständnis von Computer- und Netzwerktechnologie enorm.
2. Für jede Eingabemöglichkeit ein eigenes Passwort nehmen
Diese Regel ist so alt wie selbstverständlich und hat viele Vorteile:
Selbst wenn ein von dir genutzter Service geknackt wird, bleiben sämtliche andere Zugänge passwortseitig unangreifbar
Kombiniert mit Tools wie Passwortsafes ist diese Option einfacher als die Alternativen.
Du kannst in Bedrohungssituationen glaubhaft abstreiten, dass du den Zugang kennst. Denn wahrscheinlich kennst du ihn nicht. (Wenn du mit Verschlüsselungs- und Passwortwerkzeugen arbeitest)
Für jedes Einzelne neue Passwort gelten natürlich die gleichen Regeln.
Um Gegeninformation zur Gewohnheit zu machen und deine Spuren zu verwischen, je mehr du legst, ergibt es Sinn, für jedes Profil eigene Daten zu nutzen.
Je unabhängiger und verwirrender / generischer, desto besser:
In einem Forum heißt du zum Beispiel “Archangel789”
Auf Facebook heißt du “ManfredMüller07”
Auf einer Bewertungswebseite heißt du “Cucaracha_ox” usw.
Wichtig dabei: Die Profile sollten so wenige gemeinsame Verknüpfungspunkte wie möglich haben. Also zum Beispiel maximal eine anonyme Mailadresse / Wegwerfadresse unabhängig von deiner standardmäßig verwendeten teilen etc.
Wegwerf-Mails können bei der Verschleierung der eigenen Datenspur helfen. Bildquelle und weitere Informationen: https://muellmail.com/
4. Updates so schnell wie möglich einsetzen
Wie in den Krebs-Regeln bereits angesprochen ist dies eine der Gewohnheiten mit wenig Aufwand aber enormen Effekten. Kombiniert mit regelmäßigen Backups, virtuellen Systemen etc. zur weiteren Sicherheit minimiert diese Routine die Angriffsfläche enorm.
Update-Geschwindigkeit am Beispiel Betriebssystem. Bildquelle und weitere Informationen: https://www.drwindows.de/xf/threads/statistik-windows-10-version-20h2-l%C3%A4uft-jetzt-auf-jedem-f%C3%BCnften-pc.174662/
5. Regelmäßige Backups
Wie bereits mehrfach angesprochen sind Backups sehr wichtig. Denn ein defekter Datencluster kann deine gesamte Arbeit zerstören.
Daher möchtest du:
Regelmäßige (Minimum 2x pro Jahr)
Gern automatisierte
Gern gespiegelte Backups erstellen (lassen) und diese
Prüfen (mindestens stichprobenartig
Du kannst diesen Prozess auch auslagern. Allerdings gilt wie immer die Faustregel: Was nicht auf deinen Geräten geschieht, ist unsicher. Egal ob verschlüsselt etc. oder nicht.
6. Informiert bleiben und ggf. adaptieren
Der Cyberspace ist eine eigene Welt für sich und in jeder Welt gelten die Regeln dieser.
Deshalb ist es von zentraler Bedeutung, selbstständig up-to-date zu bleiben. Abseits und zusätzlich zu Schulungen etc.
Denn jeder hat ständig mit digitaler, vernetzter Technologie zu tun. Auch, wenn gerade keine Schulung war.
Gute aktive Startpunkte in Deutschland sind heise und Golem.
Gute passive Startpunkte können Tools wie Google Alert für Keyword wie “Cybersecurity” oder “Hacking” sein. Oder auch individualisierte Tools wie Such-Widgets oder Googles Discover.
Bildquelle und weitere Informationen zu Google Alerts: https://reputationup.com/de/google-alerts-leitfaden/
7. Nur von sicheren Quellen
Dinge downloaden Dieser Punkt ist einer der selbstverständlichsten dieser Liste. Er ist das digitale Äquivalent zu “in der Apotheke nichts naschen”. Dennoch wird er zu oft übersehen oder falsch umgesetzt.
Sichere Quellen sind:
Immer SSL-Verschlüsselt (haben ein httpS in der URL)
Fast immer länger als 10 Jahre online (Überprüfbar z.B. mit diesem Tool)
Erzeugen ein “gutes Bauchgefühl” (Wenn du auf mehr als 100 Webseiten in deinem Leben warst, wirst du wissen, was ich meine)
Von überprüfbaren und hochreputativen Quellen (z.B. Journalisten etc.)
Diese Regeln gelten natürlich nicht alle immer, sind aber hilfreiche Orientierungen.
8. Datensparsam leben
Da das Internet ein Netzwerk aus vielen Rechnern mit Festplatten ist, vergisst das Netz buchstäblich nichts. Denn jede Information die existiert, wird irgendwo in eine Festplatte “gestanzt”.
Heißt: Je weniger Daten du erzeugst, desto sicherer. Selbst Gegeninformation ist da nur die zweitbeste Strategie. (Allein weil sie mehr Aufwand bedeutet und niemals 100 % sicher ist)
9. Datenströme trennen
Um die Erstellung und Nachverfolgung von Profilen weiter zu erschweren lohnt es sich, seine Datenströme zu trennen. Die beliebteste Trennung ist dabei die in berufliche und private Aktivitäten.
Das kann zum Beispiel bedeuten nur über Browser A Onlinebanking auszuführen und nur über Browser B Onlineshopping. Oder nur über Gerät A Onlinesuchen durchzuführen und über Gerät B ausschließlich Firmenaccounts zu öffnen etc.
Kombiniert mit Fakeaccounts, automatisierter Gegeninformation, gehärteten Geräten und Software etc. kann das eine sinnvolle Routine sein. Mehr zu diesem im Detail etwas komplexeren Thema findest du in diesem Artikel.
Gleiches System, verschiedene Profile: Eine Möglichkeit zur Trennung von Datenströmen. Bildquelle und weitere Informationen: https://blog.everphone.de/geschaeftliche-und-private-daten-trennen-smartphones
10. Voreingestellte Passwörter bei neuen Geräten ändern
Wie bereits in den Abschnitten rund um Passwörter erwähnt ist diese Maßnahme eine sehr einfache und zugleich sehr wirksame. Bei manchen Geräten sind die Passwörter von Haus aus immer die gleichen. (z.B. Fabrikationsort, Herstellungsjahr) Dadurch kann ein Angreifer unter Umständen nicht geänderte Passwörter beim ersten Versuch richtig eingeben.
11. Rechte & Profile aktuell halten
Was für Unternehmen im Besonderen gilt, gilt auch im Privaten. Zum Beispiel sollte man niemals Zugriffe von Ex-Partnern länger als notwendig im eigenen System belassen.
12. Regelmäßig nicht benötigte Daten löschen / zerstören
Da Datenträger wie bereits erwähnt potenzielle “Geiseln” werden können, ergibt es Sinn diese zumindest per Software sauber zu halten. Je nach Letalität der Daten sollte auch die Hardware einer Festplatte an Ihrem Lebensende zerstört werden. Mein Favorit auf Software-Seite ist Eraser, da dieses auch nach Militärstandard Daten überschreiben kann.
Bildquelle und weitere Informationen: https://www.datenrettung-fakten.de/datenloschung/14-freeware-programme-zur-sicheren-datenloeschung.html
13. Links lesen können
Links auslesen und interpretieren zu können ist der wahrscheinlich wichtigste Skill zum sicheren Umgang mit dem Internet. Mehr dazu findest du in diesem Artikel.
Bildquelle und weitere Informationen: https://benjamineidam.com/phishing-mails
14. Cybermobbing vermeiden / minimieren
Dieser ist einer der schwierigsten Punkte dieses Grundlagen-Guides. Grundlegend gelten hierzu die Faustregeln und Grob-Empfehlungen:
Lebe datensparsam.
Arbeite mit Gegeninformation.
Behalte die Hoheit über deine digitale Identität.
Sei achtsam auf Veränderungen die auf Hacks hindeuten können.
Sei skeptisch.
Nutze automatisierte Tools zur Benachrichtigung über Updates zu deiner Person.
Weitere, aktive Gegenmaßnahmen lassen sich schwer empfehlen, da diese
Individuell abzuwägen und umzusetzen sind
Sich gesetzlich im halb- bis illegalen Bereich bewegen können
Know-how und eine wehrhafte Persönlichkeit voraussetzen.
Ein gutes Video zur Übersicht zum Thema findest du hier:
Dieser Tipp ist mit den richtigen Tools sehr schnell eine unterbewusste Routine, die vor allem in (lebensbedrohlichen) Ausnahmesituationen hilft.
Tools wie Veracrypt erlauben es sogenannte “Hidden Volumes”, also versteckte Partitionen innerhalb eines verschlüsselten Containers zu erstellen.
Diese Hidden Volumes erlauben es dir, im Ernstfall den Zugang zu deinem verschlüsselten Container freizugeben, ohne das der Angreifer tatsächlich wertvolle Daten erhält.
Bildquelle und weitere Informationen: https://www.online-tech-tips.com/computer-tips/how-to-add-a-hidden-area-inside-an-encrypted-veracrypt-volume/
16. Social Media richtig einstellen
Hier gilt Zweckmäßigkeit und die Hoheit über die eigene digitale Präsenz. Eine hilfreiche Faustregel: Stelle nur ins Internet, was
Ein Headhunter sehen sollte und
Deinem Privatsphäre-Anspruch gerecht wird.
Das kann bedeuten, dass außer deinem LinkedIn-Profil sämtliche anderen privat und anonymisiert sein sollten. Sonst sind OSINT-basierende Angriffe (extrem) leicht.
Hier lohnt es sich, ungefähr einmal im Jahr sämtliche Dienste zu prüfen, ob alle Einstellungen noch optimal sind / sich durch Updates irgendetwas geändert hat.
Fazit und FAQ
Offene Fragen und Antworten
Das Gelernte auf einen Blick, wo du am besten starten solltest und wo es mehr gibt.
Fazit
Das war eine Menge zu verdauen.
Fassen wir die wichtigsten Cybersecurity Tools und Taktiken deshalb hier noch einmal zusammen:
Software
Hardware
Mitarbeiter
Führungsetage
Unternehmen
Firmenkultur
Zulieferer
Umgebung
Künstliche Intelligenz
Gewohnheiten
Jetzt möchte ich gern von dir wissen:
Welches Tool oder welche Taktik ist neu für dich?
Oder vielleicht habe ich in dieser Liste auch etwas vergessen. (?)
Egal was es ist: Lass es mich in den Kommentaren wissen.
Technisch gesehen besteht Cybersecurity aus drei Bestandteilen: Hardware, Software und Mensch, also dem Benutzer der ersten beiden. Um die hier gezeigten Tools und Taktiken allerdings auf einen Blick erkennbar und für jeden Leser sofort anwendbar zu machen habe ich mich für diese Kategorisierung entschieden. Jeder Gerätenutzer muss mit Hard- und Software arbeiten. Doch braucht ein Mitarbeiter ohne Sicherheitsfreigaben und Verantwortung andere Handlungsweisen als eine entsprechende Führungskraft. Daher diese Aufteilung.
Am besten beginnst du mit den “Krebs-Regeln” und schaust dir im Anschluss Passwortsafes und Verschlüsselungs-Tools an.
Wenn du diese Taktiken beherzigst, Links VOR dem Klicken ausliest und keine fremden Anhänge öffnest, bist du schon ungleich sicherer als > 80 % der anderen ungeschulten Internetbewohner.
Von dort aus solltest du spätestens individuell weiter vorgehen.
Eine gute Übersicht an Tools gibt es hier, eine gute Einführung zur Vertiefung in diesem Video und ein guter Start zur Auseinandersetzung mit verschiedenen hilfreichen Tool-Anbietern hier.
Phishing ist die größte Gefahr im digitalen Raum. Privatpersonen, Unternehmen, Staaten – Sie alle sind bereits durch Phishing beschädigt und erpresst worden.
Phishing wirkt vielleicht auf den ersten Blick harmlos. Doch hinter einer Fake E-Mail oder einem manipulierenden Anruf stecken oftmals Rufmordkampagnen, Spähattacken und Cyberangriffe die weltweite Systeme zerstören.
In diesem Artikel geht es um Phishing. Darum was Phishing ist, was es so gefährlich macht und wie du dich davor schützt.
Egal ob am Telefon oder per E-Mail.
Schritt für Schritt und mit Praxisbeispielen aus dem echten Leben erklärt.
Damit du keine weitere Nummer auf der nicht enden wollenden Liste von Angriffsopfern wirst.
In diesem Artikel geht es um eines der wichtigsten Themen des Internets. Beziehungsweise der Sicherheit im Internet. Es geht um den zentralen blinden Fleck deiner Cybersecurity:
Phishing.
Nach dieser Lektüre weißt du, welche Alarmglocken bei diesem Bild läuten sollten und warum:
Was sich hinter jedem der markierten Punkte verbirgt und vieles mehr, jetzt.
Konkret erfährst du in diesem Artikel:
➡️ Was ist Phishing überhaupt genau?
➡️ Was genau passiert beim Phishing?
➡️ Wie gefährlich ist Phishing tatsächlich?
➡️ Welche Arten von Phishing werden wie angewendet und wer ist davon jeweils besonders gefährdet?
➡️ Alles rund um Phishing-Mails (Wie sie aussehen, woran du sie erkennst, was du tun solltest, wenn du draufgeklickt hast und vieles mehr)
➡️ Wie du nie wieder Opfer von Phishing-Mails wirst (Anhand echter Beispiele aus dem Alltag)
Bereit für mehr Sicherheit im digitalen Alltag? Dann lass uns loslegen!
Von vorn:
Level 1:
Grundlagen
Was ist Phishing?
Phishing ist, einfach erklärt, der Versuch, an deine Daten zu kommen. Nur eben mit (sehr) unsauberen Mitteln. Und meistens im Cyberraum, also via Internet und Co.
Stell dir folgende Situation vor:
Jemand bietet dir an einem Limonadenstand ein Glas Zitronenwasser an. Vollkommen kostenlos. Alles, was du im Gegenzug tun sollst, ist, dem Limonadenstandbetreiber deine E-Mail-Zugangsdaten zu geben.
Wenn du dir jetzt denkst: What the Hedgefond? Warum sollte ich meine E-Mail-Zugangsdaten rausrücken? Und warum so leicht? Dann bist du mitten drin. Online wird dir natürlich niemand einen solch komischen Deal anbieten. Aber viele andere Varianten, um ähnliches zu erreichen.
Phishing ist mindestens so alt wie Limonadenstände. Genau genommen so alt wie das gezielte Einsetzen von Informationen, um anderen Menschen zu schaden und sich einen eigenen Vorteil daraus zu erschaffen.
Denn Informationen, bzw. Wissen, war schon immer Macht. Früher vor allem das Wissen um Ränkespielchen und militärische Informationen um Machthaber zu erpressen. Heute trifft es jeden. Technologie demokratisiert nicht nur die positiven Dinge wie freien Zugang zum Weltwissen. Manchmal bringt sie auch weniger erfreuliche Dinge mit sich.
Eine einfache Phishing-Definition
Wenn dir die Erklärung in Geschichtsform nicht genug Licht ins Dunkel bringt, hilft dir vielleicht eine kurze und knackige Phishing-Definition zum tieferen Verständnis:
Phishing Definition:
Phishing bezeichnet jeden Versuch, bzw. jede Handlung, die darauf abzielt, gegen den Willen und / oder ohne das Wissen des Informationsbesitzers / der Informationsquelle Informationen von diesem / dieser zu stehlen und / oder Zugang zu diesen Informationen zu erhalten.
Klingt auf den ersten Blick vielleicht etwas abstrakt, zwirbelt sich aber relativ schnell auf in 5 Schlüsselkomponenten:
Versuch / Handlung: Es gibt einen Angreifer mit einer Intention.
Gegen den Willen / ohne das Wissen: Gegenteil der Angreiferintention.
Informationsbesitzer / Informationsquelle: Es gibt einen Angegriffenen.
Informationen: Es gibt “Beute”.
Stehlen / Zugang erhalten: Es gibt ein konkretes Ziel hinter dem Angriff.
Ich denke, das sollte als Phishing Definition ausreichen.
Das “Was” ist also klar. Phishing ist das “fischen” nach brauchbarem (Informationen). Und ähnlich wie ein Fisch nicht sonderlich erfreut darüber ist, an einer Angel baumelnd in einen Holzeimer geworfen und dann buchstäblich ausgeweidet zu werden, sind Phishing-Opfer nach einem Angriff selten fröhlicher als zuvor.
Warum heißt es aber Ph-ishing und nicht F-ishing, wenn es doch ums Datenangeln geht? Weil Phishing eine Kombination aus dem Ausflug auf die offene See und der Abkürzung
Password-
Harvesting
also “passwort-ernten” ist. (Und Hacker gern eigentümliche Schreibweisen mit “Ph” nutzen. Jede Subkultur hat Ihre Codes und Eigenheiten)
So wie der Laichgrund das “Feld” des Fischers ist, so ist das Internet das Feld der endlos nachwachsenden Ressource Passwörter, Zugangsdaten, Kreditkarteninformationen und mehr.
Deswegen, auch im Deutschen, Phishing.
Ausgesprochen wird “Phishing” übrigens praktisch gleich zu “fisching”. Besonders exakte Betoner können das “Ph” am Anfang natürlich noch etwas spitzer formen. Aber jeder versteht dich, wenn du phishing “gut-deutsch” wie „fisching“ aussprichst.
Kommen wir zum nächsten Fundament-Teil, dem “Wie”:
Die zwei primären (Angriffs)Arten des Phishings sind
Ausnutzen mangelnder Security Awareness (Was zum Großteil Social Engineering ist)
Mehr zu den beiden Phishing-Arten inklusive Beispielen und Verteidigungsstrategien erfährst du in meinen Artikeln zu Social Engineering und Security Awareness.
Also in kurz:
Phishing umfasst sämtliche Angriffe gegen Menschen um ohne / gegen deren Wissen an sensible Daten zu gelangen.
Ok. Das Intro haben wir also fast durch. Fehlt nur noch eines: Das “Wie genau”.
Es gibt wahrscheinlich mehr Phishing-Möglichkeiten als Moleküle im Universum, picken wir an dieser Stelle also nur 2 konkrete zur besseren Vorstellung heraus.
Die Phishing-Kampagne: Vorbei die Zeiten, in denen Phishing-Angriffe offensichtlich schlecht gemachte Versuche der Informationsgewinnung sind. Mittlerweile hat sich bei der Cyberkriminalität eine ähnliche Professionalisierung durchgesetzt, wie im Online-Marketing. Deswegen sind Phishing-Attacken mehr und mehr keine Einzelfälle, sondern von langer Hand geplante und komplex verwobene Angriffs-Lawinen. Da gehen Mails mit gezielter vorheriger Informationsbeschaffung und persönlicher Beeinflussung des Mailempfängers und vielem mehr Hand in Hand. Wie die Vorbereitung für einen solchen “höherwertigen” Angriff aussehen kann, habe ich dir in meinem kostenlosen Webinar zur gezielten Internetrecherche exemplarisch aufgezeichnet.
Das Phishing-Gewinnspiel: Eine weitere Kategorie von beliebten Phishing-Varianten sind Fake-Gewinnspiele. Bei diesen wird ein Gewinnspiel gefälscht / frei erfunden um an Nutzerdaten zu gelangen und mit diesen dann Unsinn zu treiben. Oder, noch einen Schritt weiter gegangen, auf Basis der so gewonnenen Daten die Gewinnspiel-Teilnehmer anzurufen und weitere, noch sensiblere Daten in Erfahrung zu bringen. (“Herzlichen Glückwunsch zum Gewinn! Natürlich brauchen wir jetzt Ihre Kontodaten, wie sollen wir Ihnen sonst Ihren Gewinn auszahlen? …”) Auch hier ist der Einzige wirkungsvolle Schutz das Wissen um richtige Informationsbeschaffung. Denn nur wenn ich etwas wirklich fundiert überprüfen kann, kann ich sicher entscheiden, wie ich weiter vorgehe. Wie du dabei konkret agieren kannst, zeige ich exemplarisch in meinem kostenlosen Webinar zur Online Recherche.
Ich denke jetzt sprechen wir beide dieselbe Sprache zum Thema Phishing.
Zeit für das nächste Level:
Level 2:
Schlüsselwissen
Was passiert bei Phishing?
Wir wissen jetzt was es ist. Doch wie genau funktioniert es? Wie läuft eine typische “Phishing-Session” ab? Aus welchen Bestandteilen besteht sie?
Entzaubern wir das Unbekannte etwas.
Bei Phishing passiert immer das gleiche, nur die individuellen Bestandteile ändern sich je nach konkretem Fall:
Die eigenen Kommunikationsdaten sind in fremde Hände geraten und bilden das Fundament der Phishing-Attacke.
Auf Basis der eigenen Daten wird ein Angriff unternommen. Entweder direkt oder indirekt um noch mehr sensible Daten zu erhalten um dann den Angriff mit mehr Wucht / höherer Erfolgswahrscheinlichkeit auszuführen.
Ist der Angriff erfolgreich und das eigene System geknackt, geschieht der tatsächliche Schaden: Wie Wasser, das nach einem Dammbruch das Tal flutet, schlägt die “Schadphase” zu. Diese kann aus den verschiedensten Dingen und Kombinationen dieser Dinge bestehen. Von simplem Datendiebstahl über Ransomware bis hin zum Cryptojacking ist dabei alles im Rahmen des Möglichen.
Hier auch nochmal als handliche Infografik auf einen Blick:
Wir wissen was Phishing ist und woraus es sich zusammensetzt. Doch wie “schlägt” sich Phishing im Kontext anderer Angriffsmethoden?
Zeit für das große Grundlagenwissen-Finale zum Thema Phishing:
Phishing und der Rest: Das “Who is Who” der virtuellen Angriffsmethoden auf einen Blick
Den Fundamenten des Phishings haben wir uns jetzt hinreichend gewidmet.
Schauen wir uns nun kurz an, wo Phishing sich im Vergleich zu anderen Onlinegefahren einordnet.
Am häufigsten werde ich in meinen Webinaren zur Abgrenzung von Phishing zu Skimming, Hacking und Spam gefragt. Stellen wir diese 4 Gauner also mal gegenüber:
Ablauf
Angriffsziel
Methode
Phishing
Input: Du erhältst Informationen, auf welche du reagieren sollst. Kann in Form einer E-Mail, einer SMS, eines Anrufs etc. geschehen.
Reaktion: Du sollst auf den Input reagieren. Oftmals indem du Daten angibst, Dateien öffnest oder Links öffnest.
Infektion: Während du mit etwas anderem an der Oberfläche abgelenkt wirst, wird im Hintergrund dein System angegriffen.
Buchstäblich jeder. Je mehr Macht / Geld / Einfluss etc. vorhanden ist, desto lohnenswerter. Aber auch bei „normalen“ Menschen lohnt sich ein Angriff. Und sei es nur um Sie zum Teil eines Folgeangriffs zu machen.
Phishing ist eine hinterhältige Unterart des Spam.
Beim Phishing werfen die Angreifer Ihre virtuelle „Angel“ aus und warten darauf, dass das Opfer klickt / zubeißt.
Und ähnlich wie beim echten fischen ist das Opfer nach dem Biss nahezu chancenlos ausgeliefert.
Skimming
Manipulation: Die Angreifer verändern eine Geldschnittstelle so, dass diese Ihnen automatisch und unerkannt Daten ausgibt.
Anwendung: Die manipulierte Geldschnittstelle wird benutzt.
Diebstahl: Während der Benutzung werden die eingegebenen Daten kopiert und ggf. direkt übermittelt / automatisch zum Diebstahl eingesetzt.
Jeder, der an Geldschnittstellen wie Bankautomaten Geld abholt.
Skimming ist wie Phishing, nur spezifischer.
Beim Skimming werden ebenfalls Daten von dir abgesaugt, nur hier ausschließlich direkt geldbezogen.
Hacking
Ausspähen (optional): Je nach Größe, Umfang und Ziel der Hackingattacke wird das Ziel ggf. vorab ausgespäht um Schwachstellen zu finden.
Nachbehandlung (optional): Bei manchen Angriffsarten ist das Hacking selbst nicht der zentrale Teil. Hier wird zum Beispiel ein Spähprogramm hinterlassen um nach dem Hacking weiter an Daten zu gelangen.
Jeder, bei dem es sich aus Hackersicht lohnt. Kann ein Unternehmen sein, kann ein Staat sein, kann eine Privatperson sein.
Ein Fremder übernimmt das eigene System und/oder manipuliert dieses.
Hacking kann in verschiedensten Varianten mit Phishing kombiniert werden, chronologisch wie technisch.
Spam
Sammlung: E-Mail-Adressen werden gesammelt.
Versendung: Versand von unerwünschten Mails an jeden User, dessen Mailadresse bekannt ist.
Ziel von Spammern ist es, Gewinn über Werbeklicks von Spam-Opfern auf Links in Spam-Mails erzielen.
Da dies allerdings nur die wenigsten tun, wird prinzipiell jeder mit einer E-Mail-Adresse mit Spam überzogen.
Unmengen von Spammails in jeden Winkel versenden. Nach dem “Gießkannen-Prinzip” Gewinne damit einfahren.
Spam- und Phishing-Mails sehen sich manchmal sehr ähnlich. Manchmal hat eine Fake-E-Mail auch sowohl Phishing- als auch Spamcharakter.
Hier mal ein Beispiel für eine etwas ausgeklügeltere Phishing-Mail:
Wenn du dich jetzt fragst, was an dieser Mail auffällig ist und woran du in wenigen Sekunden erkennst, dass es sich hierbei um eine Phishing-Mail handelt, bist du in meinem Phishing-Mail-Artikel goldrichtig.
Hier einige der Angriffspunkte, welche beim Skimming attackiert, bzw. manipuliert werden können auf einen Blick:
Mehr zum Thema Skimming erfährst du in einem anderen Artikel, den ich hier verlinke, sobald er fertig ist.
Gefahr oder bloß nervig? Die Bedeutung von Phishing
Nachdem wir Phishing mittlerweile besser kennen als unseren Nachbarn wird es Zeit diesen Angriffsvektor einzuordnen.
Und damit die Antwort auf die Frage zu geben:
Welche Bedeutung hat Phishing für meinen digitalen Alltag?
Die Kurzantwort konnte ich glaube ich weiter oben bereits hinreichend geben: Eine enorme Bedeutung! Egal ob als Privatperson oder in Unternehmen, ein falscher Klick kann Milliarden kosten, Karrierepfade beenden und Leben zerstören. Mehr zum Thema Bedeutung von Phishing findest du auch in meinem Artikel zum Thema:
Schauen wir uns die gängigsten Phishing Arten und die häufigsten Medien an, in welchen man auf diese Arten trifft.
Auf einen Blick sieht die Welt des Phishings grob ungefähr so aus:
Jede der Phishing Arten auf der x-Achse kann mit fast jedem Angriffsmedium auf der y-Achse kombiniert werden.
Da prinzipiell jede dieser Phishing-Arten einen eigenen Artikel verdient, verlinke ich hier nach und nach eben diese, sobald ich sie geschrieben habe.
Exemplarisch für alles außer Mails hier mal am Beispiel Telefon:
Warum ist Phishing per Telefon so “lukrativ und verlockend”? Weil die direkte Beeinflussbarkeit für “ungehärtete”, also nicht zum Thema Sicherheit weitergebildete Mitarbeiter bei Telefonaten vergleichsweise hoch ist. Und der Angreifer, anders als zum Beispiel beim direkten Gespräch, dennoch nahezu unerkannt agieren kann.
Der einzige wirkliche Nachteil von Phishing per Telefon ist der, dass es nicht skalierbar ist. Und dieser Nachteil ist derart groß, dass relativ betrachtet Telefon-Phishing recht selten vorkommt.
Schauen wir uns das Thema Phishing Anruf etwas näher an:
Seltener aber persönlicher: Der Phishing Anruf
Da Phishing Anrufe so etwas wie die Präzisionswaffen für besondere Fälle sind, habe ich mich diesen in einem Artikel ausführlich gewidmet:
In diesem Artikel gehe ich unter anderem darauf ein:
Was Phishing Anrufe so gefährlich macht
Wie Phishing Anrufe „vor deinen Augen“ dein Gehirn kidnappen.
Wie du dich ganz leicht vor derartigen Angriffen schützen kannst, indem du eine einfache 4-Punkte-Checkliste abhakst.
Was uns zum „Standard“ des Phishing führt. Der Phishing-Mail:
Das „Bread & Butter“ im Phishing: Phishing Mails
Das Feld der Phishing Mails ist so groß wie es gefährlich ist. Die Spannweite reicht dabei von generischem Spam, der hundertmillionenfach ins Internet geworfen wird wie Pflanzensamen. Und dabei durch schlichte Wahrscheinlichkeitsrechnung erfolgreich ist.
Bis hin zu personenspezifisch maßgeschneiderten Mails, denen manchmal monatelange Recherche und Observierung der Zielperson vorausgeht. Denn bei diesen Spear-Phishing oder auch Whaling Mails muss nur ein einziger Klick passen.
Da dies den Rahmen dieses Artikels mehr als sprengen würde, habe ich dazu einen eigenen Artikel geschrieben:
Wie ein einziger Klick eine komplette Firma für Wochen zum Stillstand gezwungen hat.
Wie Phishing-Mails aufgebaut sind.
Warum du überhaupt Phishing-Mails bekommst.
Konkrete Beispiele aus der Praxis anhand derer du erkennen kannst, was Phishing Mails ausmacht.
Was uns zum letzten Abschnitt dieses Artikels führt. Dem Schutz vor Phishing:
Level 3:
Praxis
Phishing Schutz: Und nun?
Jetzt weißt du also wie solche Angriffe und Mails aussehen, woran du sie erkennst und was die Ziele und Wege zum Ziel von Angreifern sind.
Doch wie nun weiter?
Den effektivsten Phishing Schutz hast du bereits kennengelernt: Deine Fähigkeit Phishing Angriffe zu identifizieren und Ihnen zu widerstehen.
Anders formuliert: Deine Security Awareness. Dein digitales Sicherheits-Bewusstsein. Du bist dir jetzt bewusst, dass Link nicht gleich Link ist. Du weißt jetzt wie ein Anhang komplette Serverfarmen zerstören kann. Du weißt, dass auch du im Fadenkreuz stehst.
Sehr gut! Allein durch dieses Wissen bist du „härter“ bzw. stärker „gehärtet“. Also sicherer im Digitalraum.
Weitere Schutzmaßnahmen gegen Phishing können sein:
Verschärfte Einstellungen bei Spamfiltern und Antiviren-Software
Der Einsatz verschlüsselter Container und Passwortsafes
Das Härten aller insgesamt beteiligter IT-Systeme
Und vor allem: Das ständige Training der eigenen Achtsamkeit!
Das klappt im Rahmen von Security Awareness / Social Engineering Trainings meist ganz gut. Wenn ich dich dabei unterstützen soll, melde dich gern bei mir.
Auch hilfreich um ein Gefühl für die Bedrohungslage zu bekommen, kann das Phishing Radar sein:
Dieser Artikel kann deine Karriere und dein Unternehmen retten. Und vielleicht sogar noch einiges mehr…
Phishing Mails sind hinterlistige und ohne das richtige Wissen schwer erkennbare Angriffe. Hier lernst du Schritt für Schritt alle wichtigen Elemente kennen, mit denen du sicher bist. Legen wir los!
Was kann eine einzige Mail schon großartig anrichten?
Diese Frage stellen sich noch immer viel zu viele Menschen. Und viel zu oft sind diese in sehr wichtigen Positionen.
Schauen wir uns ein aktuelles und anschauliches Beispiel an. Zitat aus einem Artikel des Handelsblatts:
“ … Selbst wenn Unternehmen wie etwa im Fall EDAG sehr schnell auf die Attacke reagieren, ist der Aufwand, diese abzuwehren, häufig gewaltig. Das zeigt das Beispiel der Wuppertaler Schmersal. Ende Mai vergangenen Jahres wurde der Automatisierungsspezialist vom Landeskriminalamt vor einem Cyberangriff gewarnt. Sofort fuhren die Verantwortlichen alle Systeme herunter – mit massiven Folgen. Die Fertigung in sieben Werken und die Arbeit in über 50 Niederlassungen ruhte länger als zunächst gedacht.
Gut zwei Wochen dauerte es, bis jeder Winkel in dem weitverzweigten IT-Netz durchsucht war. Am Ende musste das Unternehmen die gesamte IT neu aufsetzen. Die Kosten bezifferte Philip Schmersal, der geschäftsführende Gesellschafter, auf über zwölf Millionen Euro. …“
Klingt drastisch? Ist es auch! Und hier kommt noch hinzu, dass die Verantwortlichen vorab gewarnt wurden UND vorbildlich gehandelt haben!
Im Großteil der Fälle passiert weder das eine noch das andere.
Und wie ist dieser massive Ausfall zustande gekommen?
Das wird in einem Nebensatz, beinahe beiläufig in besagtem Artikel ebenfalls erwähnt:
Auslöser – so zeigte sich bei den Analysen – war eine Mail, die völlig unverdächtig war, die aber den Trojaner in das System eingeschleust hatte.
Eine Phishing Mail hat 14 Tage lang 7 Werke in mehr als 50 Niederlassungen lahmgelegt und dabei mehr als 12.000.000 € Schaden verursacht.
Obwohl nahezu mustergültig reagiert wurde und es eine ernstgenommene Vorwarnung gab!
Was kann eine einzige Mail schon großartig anrichten?
Einiges.
Und damit sind wir direkt im Thema: Phishing Mails.
Beim Thema Phishing Mails sind wir beim “Bread and Butter” des Phishing angelangt. Denn Fake Mails, wie Phishing E-Mails auch oft genannt werden, bilden den absoluten Großteil sämtlicher Phishing-Attacken ab. Warum?
Weil Mails extreme Vorteile für Angreifer bieten. Denn Phishing Mails sind
100%ig anonym
Automatisiert,
In unendlicher Zahl und
Nahezu in Echtzeit erstellbar
Einnisten in Firmen-Proxys möglich und Angriff über diese (Siehe Praxis-Beispiel weiter unten)
Phishing Mails sind aus Sicht der Angreifer so etwas wie eine Gelddruckmaschine für Banken. Sie liefern einen nahezu unendlichen Strom an Ressourcen zu relativ geringen Kosten.
Schauen wir uns daher in diesem Artikel Phishing E-Mails genauer an.
Unter anderem erfährst du:
Was Phishing Mails überhaupt sind und was diese Fake Mails von „normalen“ Mails unterscheidet
Eine Beispiel-Chronologie von Phishing Mail bis eingetretener Schaden
Warum du überhaupt Phishing Mails bekommst / wie Kriminelle an deine Emailadresse kommen, um Phishing Mails an dich zu schicken
Wie du kugelsicher Phishing Mails im Schlaf erkennst und filtern kannst, ohne auch nur mit der Wimper zu zucken
Konkrete Beispiele von Phishing Mails die ich selbst erhalten und betreuen durfte
Eine handliche und sofort einsetzbare 15-Punkte Checkliste um verdächtige Mails auszusondern
Legen wir los!
Was sind Phishing Mails?
Warum + Wie Links für dich zur Gefahr werden können
Beginnen wir beim Anfang: Was sind Phishing Mails überhaupt?
Phishing Mails sind technisch betrachtet und von außen besehen “normale” E-Mails. Mit einem elementaren Unterschied:
Eine Phishing Mail bringt dich nicht zum angegeben Ziel, sondern direkt in eine Gefahrenzone. Eine Gefahrenzone, die so gut getarnt ist, dass du nicht einmal dann sicher sagen kannst, dass Gefahr im Verzug ist, wenn du mitten drin stehst und unter Umständen bereits deine Daten eingibst.
Das funktioniert über gefälschte Anhänge, Dateien innerhalb von Mails und vor allem über gefälschte Links. Schauen wir uns den letzten Fall genauer an.
Echte vs. Fake Mails
Das kannst du dir ungefähr so vorstellen:
✅ Eine “normale” Mail enthält einen Link zu einem Ziel, zum Beispiel einem Artikel. Angenommen zum Thema Feuersalamander. Der Link funktioniert dabei wie ein Tunnel, welcher deinen Browser und dich zusammen durch eben diesen Tunnel direkt zur Zieladresse Artikel führt. Dort erfährst du also mehr über das Leben des Feuersalamanders und bist beeindruckt. Diese bekommst du zum Beispiel von deinem Kollegen Frank. Soweit alles gut, danke für die Mail, Frank.
Im Quelltext, also der Sprache, in welcher Franks Computer mit deinem “spricht”, sieht diese Mail so aus:
<p>Hey, ich habe gerade diesen spannenden Artikel zum Thema Feuersalamander entdeckt, schau ihn dir unbedingt mal an: <a href=“https://www.geo.de/geolino/tierlexikon/840-rtkl-tierlexikon-feuersalamander“>https://www.geo.de/geolino/tierlexikon/840-rtkl-tierlexikon-feuersalamander</a></p><p><br></p>
<p>Frank.</p>
Im Wesentlichen sprechen auch Computer unsere Sprache, sie sind nur sehr große Liebhaber von eckigen Klammern.
Der farbig hervorgehobene Teil wird gleich noch relevant.
❌ Eine Phishing Mail enthält ebenfalls einen Link zu einem Ziel. Doch anders als im obigen, harmlosen Beispiel, führt dich dieser Link nicht zu einem harmlosen Artikel. Sondern in eine gezielt für dich gestellte Falle. Wenn der Tunnel von Frank dich ins Salamander-Biotop geführt hat, führt dich der Tunnel der Phishing-Mail direkt in ein Minenfeld. Das tückische dabei: Die Mail kann auf den ersten Blick sogar exakt so aussehen, wie die Mail von Frank. Doch unter der Haube, im Quelltext, verbirgt sich die Bombe. Schauen wir uns die Phishing-Variante von Franks Mail an:
Erkennst du den Unterschied? Siehst du die Zacken der Landmine aus dem Boden ragen? Noch nicht? Dann lass uns gemeinsam etwas näher ran gehen:
<p>Hey, ich habe gerade diesen spannenden Artikel zum Thema Feuersalamander entdeckt, schau ihn dir unbedingt mal an: <a href=“https://www.bsi.bund.de/DE/Home/home_node.html“>https://www.geo.de/geolino/tierlexikon/840-rtkl-tierlexikon-feuersalamander</a></p><p><br></p>
<p>Frank.</p>
Du siehst den Unterschied noch nicht? Oder siehst ihn zwar, aber weißt nicht, was dir das sagen soll? Dann klicke mal auf beide blau markierte Links und schau mal, ob sie dich zum gleichen Ziel bringen. Sollten sie doch, sie sehen schließlich gleich aus, richtig?
Die Krux liegt hierbei unter der Motorhaube. Es ist wie im echten Leben, nicht überall wo Tesla draufsteht, ist auch Tesla drin.
Was genau drin ist, sieht man meist erst beim hereinschauen. So auch hier. Der Schlüssel ist der Vergleich der beiden grün markierten Bereiche. Denn dieser Bereich ist der, der die “Ausfahrt des Tunnels” bestimmt. Der rote, sichtbare Bereich ist quasi nur das Eingangsschild. Wo du am Ende tatsächlich rauskommst, entscheidet aber der grüne Bereich.
Ich kann auch ein Schild mit der Aufschrift “In 2km Nordseeküste” vor den Gotthard-Tunnel stellen. Doch der Tunnel-”Inhalt” bestimmt, wo du tatsächlich am Ende landest.
Und deshalb ist es egal, was der blau markierte Bereich sagt. (Der Linktext) Ausschließlich der Inhalt des grünen Bereiches zählt. (Das Linkziel)
Wie im echten Leben: Nur wenn alles im grünen Bereich passt, macht die ganze Sache wirklich Spaß.
Heißt in Kurzform:
Nein, du brauchst keinerlei informatisches Vorwissen um Fake-Links in Phishing-Mails zu erkennen und zu umgehen. Tatsächlich musst du nur eine Einzige Sache können:
Den Unterschied zwischen dem Link erkennen, der suggeriert wird. Und dem tatsächlichen Linkziel. Wenn du einen Apfel und eine Birne voneinander unterscheiden kannst, hast du hier also gute Karten. (Mehr dazu weiter unten)
Die Kurzantwort auf die Frage “Was sind Phishing Mails?” lautet also: Mails, die dich zu einem anderen Ziel bringen, als sie suggerieren.
…Aber warum?
Welchen Sinn hat das? Warum erstellt jemand ein Linkziel, welches ein anderes ist als das, was er angibt? Machen wir ein einfaches Beispiel:
Angenommen du bekommst eine Mail von deiner Bank mit der Aufforderung, dein Onlinebanking zu ändern. Dann klickst du auf den Link, gibst deine Zugangsdaten ein und änderst, was du ändern sollst.
Gleiches Szenario, diesmal in der Phishing Variante:
Du bekommst eine Mail von einem Angreifer, welcher sich als deine Bank ausgibt. Die Mail sieht exakt gleich aus, bis hin zum Wortlaut und Logo oben links in der Ecke. Du erhältst wieder die Aufforderung, deine Onlinebanking-Daten zu ändern. Nur diesmal wirst du nicht zur tatsächlichen Bankseite geführt, sondern zu einer gefälschten, nachgebauten.
Du gibst wieder deine Daten ein, doch dann kommt eine Fehlermeldung. Du bist verwirrt, weißt aber nicht was du tun sollst, und fährst den Computer herunter.
Währenddessen haben die Kriminellen deine Zugangsdaten durch ihre gefälschte Seite erhalten, melden sich mit diesen in deinem Konto an und räumen dieses leer.
Das ist der Grund, warum Banken niemals derartige Aufforderungen per Mail senden würden.
Multidimensionale Angriffe: Drei zum Preis von einem.
Wirklich gefährlich im großen Maßstab werden Phishing Mails allerdings erst kombiniert mit anderen virtuellen Waffen.
Häufig kommt dabei das Dreigespann aus Phishing Mail – Trojaner – Ransomware zum Einsatz. Beim eingangs genannten Beispiel war dies genau die Angriffsabfolge.
Es gibt eine nahezu unendliche Anzahl von Kombinationsmöglichkeiten digitaler Waffen. Bei dem Großteil ist Phishing allerdings die Speerpitze. Aus den oben genannten Gründen.
Schauen wir uns dieses unheilvolle Trivium kurz etwas näher an.
Du kannst dir das ganze ungefähr so vorstellen:
Es klingelt bei dir und es meldet sich ein Handwerker, der bei dir ein undichtes Fenster reparieren soll.
Verwirrt und verunsichert lässt du ihn herein, schaust aus dem Fenster und ein Fahrzeug fährt die Einfahrt entlang.
Ein Mann in Montur steigt mit einem braunen Karton unterm Arm aus und kommt zu dir in die Wohnung.
Er spricht kurz mit dir, stellt den Karton auf den Küchentisch und geht mit dir ins Wohnzimmer um den Schaden zu besprechen.
Nachdem ihr alles geklärt habt und du so verwirrt wie vorher bist, siehst du überall auf dem Flur Schlangen.
Keine aus Papier. Waschechte, lebendige Schlangen kriechen langsam und zischend überall durch deine Wohnung.
Und nun?
Was Handwerker, Autos, Kartons und Schlangen mit Phishing Mails zu tun haben?
Der Handwerker ist der Grund, warum du die Mail öffnest.
Das Auto ist der Anhang oder der Link, welcher den Sprengstoff in deinen Rechner bringt.
Der Karton ist der Trojaner, welcher nach Lust und Laune auf deinen Rechner Software installiert, ohne das du es mitbekommst.
Die Schlangen sind die Ransomware, die deine Technik kidnappen und dich gefangennehmen.
Fragst du dich immer noch „Was kann eine einzige Mail schon großartig anrichten?„
Gut. Bevor wir in die Praxis gehen und ich dir anhand konkreter Beispiele erkläre, wie du Phishing Mails entschärfst, bleibt nur noch eine letzte Frage zu klären:
Warum bekomme ich überhaupt
Phishing Mails?
Die Antwort auf die Frage “Warum bekomme ich Phishing Mails?” läuft in etwa 80 % der Fälle auf eine oder beide der folgenden Optionen heraus:
Deine E-Mail-Adresse wurde von einem Service weitergegeben. Es passiert nicht selten, dass Firmen übernommen werden oder Datenbanken “unter der Hand” oder auch offiziell verkaufen und große Mengen Mailadressen dadurch den Besitzer wechseln. Und nicht selten bedeutet das: Hallo Phishing Mails. Deshalb: Achte darauf, welchem Service du im Internet vertraust. Und welche Mailadresse du wo / überhaupt angibst. (Eine E-Mailadresse nur für solche Fälle ist zum Beispiel wirklich hilfreich)
Ein Service wurde geknackt, die Daten gekapert und in Zehntausender-Paketen auf dem virtuellen Schwarzmarkt für Centbeträge verschleudert. Das ist meistens der Fall, wenn du wirklich “hässliche” Phishing Mails bekommst.
Schnell und einfach prüfen ob deine Mailadresse betroffen ist
Wie kannst du mit einem Klick, kostenlos und ohne Aufwand prüfen, ob deine Mailadresse(n) in einer solchen Schwarzmarkt-Schleuder im Umlauf sind?
Am einfachsten durch Services, welche die bekannten Datenbanken im Darknet kopieren und per Klick durchsuchbar machen.
Mit diesen 3 “Tricks” und den entsprechenden Reaktionen auf das Ergebnis bist du sicher gegen jede Phishing Mail.
Wenn du dich mit mehr Informationen allerdings noch besser für diesen Kampf gerüstet fühlst, kriegst du hier noch einige weitere Punkte, welche dir garantierte Sicherheit und ein gutes Bauchgefühl bescheren:
Headline prüfen (Will sie dir nur Emotionen wie Angst bringen? -> Verdächtig. Zum Beispiel “illegale Account Aktivität erkannt”)
Mailabsender prüfen (Ist es irgendein spammy Bullshit? NUR die URL nach dem letzten Punkt zählt. Alles davor ist egal)
Inhalt prüfen (Ist es auf Englisch obwohl ich auf Deutsch unterwegs bin?
Link lesen BEVOR du auf irgendeinen Button klickst.
Falls eine Trap Door / Link Cloaking von einem gehackten / erstellen ähnlich klingenden Service, zB ionos.biz statt wie normal ionos.com benutzt wurde, Link in der URL-Leiste lesen und NICHTS tun, bevor du dir nicht sicher bist, dass der Link sauber ist.
Empfänger: Ist es unbekannt? Dann bist du nur einer von vielen (Hunderten bis Tausenden), denen diese Mail gerade zugeschickt wurde.
Alright, dann kommen wir jetzt zu den konkreten Beispielen. Ich habe derer 3 mitgebracht, in aufsteigenden „Echtheitsgraden“ und Gefahrenstufen: ( Du kannst mit dem Slider stufenlos zwischen der Originalmail, so wie sie auch in deinem Posteingang landet und den wichtigen Stellen auf die du achten solltest, switchen)
Die Anatomie einer Phishing Mail
Schritt für Schritt zur Sicherheit
Fall #1: „Gießkannen“-Phishing auf gut Glück
Diese Art von Phishing Mail begegnet einem am häufigsten im Netz. Hierbei werden einfach Phishing Mails erstellt und wahllos an jeden gesendet, der in der Zieldatenbank ist.
Kann mal klappen, kann mal nicht funktionieren.
Wenn diese Mails funktionieren, dann eher aufgrund der gewählten Sprache und verwendeten Wörter. Schauen wir uns systematisch die wichtigsten Warnsignale an:
(3): Impliziert, dass der Empfänger bereits zwei Nachrichten zuvor verpasst hat. Führt dadurch halbbewusst zu mehr Dringlichkeit und Druck zu reagieren.
Müssen: Siehe 1. Keine Bitte sondern weiterer psychischer Druckaufbau.
Neue: Impliziert je nach Interpretation etwas besseres, aktuelleres oder generell eine sicherere Lösung als die Vorhergehende. Hier wird also ausgenutzt, dass Updates gut sind und neues gern genutzt wird.
Web-Sicherheitssystem: Hier wird explizit Sicherheit vorgegaukelt. Und gerade bei einer Bank möchte man sicher sein. Man ist also angehalten, der Mail zu folgen.
Aktivieren: Hier wird nicht „installieren“ oder „konfigurieren“ geschrieben. Sondern lediglich aktivieren, also einen Knopf drücken. Klingt einfach, dafür das man danach sicher ist, richtig? (Spätestens hier fällt auf, dass gute Copywriter auch sehr direkt gefährlich sein können 😉
Absendername: Erklärung siehe oben.
Absender-Mail: Wichtig! Wenn du sonst nichts in einer Mail scannst, die Mailadresse des Absenders und den Link auf den du klicken sollst, musst du prüfen! Warum siehe oben und bei Beispiel #3 weiter unten.
Empfänger-Mailadresse: Siehe oben.
Link auf den der Empfänger klicken soll: Wichtig! Wie oben und weiter unten geschrieben, Links immer vor dem Draufklicken lesen!
So viel zu den kritischsten Checkpoints. Es gibt noch ein paar hilfreiche Indizien, die man zusätzlich prüfen kann:
Domain-Authentifizierung: Manche Programme warnen den Empfänger bereits groß und rot vorher, achtsam zu sein.
Mail-Footer: Manchmal entlarven sich Phishing Mails auch über schlecht geschriebene, logisch inkonsistente oder schlicht falsch oder nicht übersetzte Texte / Textabschnitte. Passierte früher öfter, mittlerweile immer seltener.
Sinnlose Inhalte am Ende der Mail: In einigen Fällen enden Phishing Mails mit sinnlosen Zeilen. Warum ist schwer zu sagen, aber es ist ein recht sicheres Indiz für eine Fake Mail. Manchmal geschieht dies in weißer Schrift auf weißem Hintergrund wie in dieser Mail, deshalb ist dieser Abschnitt auf dem Bild auch blau markiert.
Wichtig hierbei: Das sind wie gesagt generische Mails. Eine Mail für alle. In meinem Fall offensichtlich sinnlos wenn man den Absender-Service, in diesem Falle die DKB, nicht benutzt.
Doch mit relativ wenig Analyse und Recherche können solche Mails wie maßgeschneidert werden und ungleich schwerer zu identifizieren. Wie die Grundlage dafür aussehen kann, erfährst du in meinem kostenlosen Webinar.
Fall #2: Phishing getarnt im weißen Rauschen
Diese Art von Fake Mails ist vor allem gefährlich für Personen und Firmen die viele Pakete erhalten.
Denn dabei geht eine solche Mail schnell unter, da mal täglich Dutzende wie diese erhält.
Schauen wir uns die Anatomie einer solchen Phishing Mail am Muster aus der Praxis an:
Wichtig: Alle bei #1 genannten Punkte gelten uneingeschränkt weiterhin und zusätzlich zu den hier ausgeführten!
Nachricht aus einer Verteilerliste: Wenn das eigene Programm eine Funktion anbietet, die Quell-Liste der Phishing Mail zurückzuverfolgen, kann man dies durchaus machen. Kann im Folgeschritt dabei helfen, gezielt Adressen zu blockieren, bei Behörden zu melden und in der Zukunft besser zu wissen, worauf man achten muss. Eher optional und für Menschen mit Drang zur Technik-Detektei.
Inhalt der Mail: Wenn du bis hierhin alle Punkte richtig überprüft hast, macht der Inhalt keinen großen Unterschied mehr. Dennoch können sich natürlich auch hier noch mögliche Indizien für Phishing-Ambitionen offenbaren.
Weitere Absenderdaten: Auch die Prüfung von Firmendaten in der Mail und der Abgleich mit der Realität kann die Sicherheit über die Authentizität erhöhen. Anhaltspunkte können zum Beispiel sein: Verwendetes Logo, Unterschrift, Firmenname etc.
Fall #3: Phishing Mail via vertrauenswürdigem, gehacktem Proxy
Diese Art der Fake Mail ist besonders gefährlich. Denn die tatsächliche Phishing Mail wird von einer real existierenden, überprüfbaren und oftmals seriösen Firma versendet.
Und ist zeitgleich noch schwieriger zurückverfolgbar, da ein missbrauchter „Bote“ zur Zustellung der Phishing Mail genutzt wird.
Du kannst dir das vorstellen wie einen Brief den du in die Hand gedrückt bekommst, in welchem sich Juckpulver befindet. Der sich wild kratzende Empfänger wird dir nach der Übergabe die Schuld zuschieben, nicht deinem Auftraggeber.
Phishing Mails über so genannte Proxys, also „Außenstellen“ sind noch aus weiteren Gründen gefährlich, aber bleiben wir beim Beispiel und schauen uns Anhaltspunkte an:
Auch hier gilt wieder: Die Tipps von #1 und #2 gelten zusätzlich zu den hier genannten!
Absender: Selten wird ein Unternehmen geknackt und als Proxy missbraucht, welche einen ähnlichen Namen oder ähnliche andere Daten hat. Der Abgleich von Namen und Mailadresse des Absenders ist hier also oftmals die einzige wirkliche Möglichkeit zur Identifikation.
E-Mail-Adresse des Absenders: In diesem Fall wurde eine unprofessionell klingende Mailadresse mit „meins@“ statt zum Beispiel „kontakt@“ oder „business@“ genutzt. Was zwar einerseits sicherer vor dem möglichen Auffliegen des Einbruchs macht, aber andererseits auch die Abwehr erleichtert. Andererseits hatte die gehackte Firma über welche die Phishing Mail zugestellt wurde absolut nichts mit einer Bank zu tun. Da ich den offiziellen Firmennamen nicht nennen darf, machen wir es an einem Beispiel: Du erhältst eine Mail von Autohaus Ziegel, die Mail abgeschickt wurde aber von „auto@blumen-sommerfrische.de“. Ziemlich offensichtlich, wenn man weiß, wonach man schauen muss.
Dauerskill #1: Links lesen
Was uns zum meiner Meinung nach wichtigsten Skill der Cybersicherheit insgesamt bringt: Der Fähigkeit, Links zu lesen und zu interpretieren.
Wenn du Interesse an einem ausführlichen Artikel dazu hast, kommentiere gern diesen Artikel. ⬇️
Die Kurzform siehst du im Screenshot neben diesem Text.
Zwei Dinge solltest du tun, bevor du auf irgendeinen Link im Internet klickst:
Die Maus über den Link halten.
Lesen, welches Linkziel dir unten links in der Ecke deines Bildschirms angezeigt wird. Wenn es das Ziel ist, zu dem du möchtest, klicke frei und unbeschwert. Wenn nicht: Finger weg!
Die Schäden, die auf einen einzigen Klick folgen können, sind gigantisch. Persönlich wie geschäftlich.
Doch mit dem richtigen Wissen lässt sich diese Gefahrenquelle ganz leicht umschiffen. Ich hoffe ich konnte dir genau dieses Wissen in diesem Artikel vermitteln.
Und zum Schluss bekommst du hier wie versprochen die Checkliste zum ausdrucken und anwenden. Damit du jetzt nicht jedes Mal diesen Artikel öffnen, Bilder hin- und herwischen und alles händisch prüfen musst.
Wenn du mehr von mir wissen möchtest, abonniere am besten meinen Newsletter oder schreib mir direkt.
Stay safe!
Ben
Hier kannst du dir die Anti-Phishing-Mail Checkliste kostenlos herunterladen
Was ihn so gefährlich macht und wie du dich schützt
Phishing Anrufe sind wie Funde von Weltkriegsbomben: Gemessen an den Gefahren des digitalen Alltags relativ selten aber mit umso mehr Vorsicht zu behandeln.
Was den Phishing Anruf so gefährlich macht, wie du dich schützen kannst und eine handliche 4-Punkte-Checkliste zur sofortigen Identifikation und Entschärfung von Phishing Calls gibt es in diesem Artikel.
Der Phishing Anruf ist im Vergleich zu seinem großen Bruder, der Fake- oder Phishing Mail eher ein kleiner Player im “Phishing-Game”. Was nicht schwer ist, lassen sich Mails doch beliebig replizieren, brauchen Anrufe allerdings noch immer Menschen.
Doch nur weil sie seltener sind, heißt es nicht, dass man nie von diesen attackiert wird. Und erst recht nicht, dass Phishing Anrufe harmlos sind. Im Gegenteil. (mehr zur Bedeutung von Phishing erfährst du in diesem Artikel)
Glücklicherweise ist es hier noch viel leichter, sicher zu sein. Denn die meisten Phishing Anrufe lassen sich leicht identifizieren und dementsprechend entschärfen. Wenn also keine Profis mit langer Vorbereitung am anderen Ende der Leitung sitzen, hat man hier ganz gute Karten.
Zumindest wenn man die Tipps auf dieser kleinen “Phishing Anruf Checkliste” beherzigt:
Deine "4-Punkt Sicherheits-Checkliste"
bei Phishing Anrufen
Auf 4 Vorkommnisse / Eigenschaften von Telefonaten solltest du achten, bzw. vorbereitet sein, um Phishing Calls nicht auf den Leim zu gehen:
Es ist ein unbekannter / komisch klingender Anruf. Kann prinzipiell überall vorkommen, hier ist eine zentrale Sache wichtig: → Höre auf dein Bauchgefühl. Menschen sind im Laufe der Evolution wirklich gut darin geworden, Gefahren “aus dem Bauch heraus” zu erkennen. Lass dich von eben diesem leiten. Ist der Anruf einfach nur verwirrend oder möglicherweise gefährlich? Dein Bauch weist dir den Weg.
Du sollst sensible Daten weitergeben. Wenn Handlungen wie Freigaben oder Zugänge von dir gefordert werden solltest du prinzipiell die → Notbremse ziehen und nichts sagen / entschieden gegenfragen wofür genau / ggf. direkt auflegen, statt das Notizbuch zu zücken. Mehr zum Umgang und Gefahren dabei findest du in meinen Artikel zu den Theman Security Awareness und Social Engineering.
Es werden intensive Emotionen als Waffe gegen dich aufgebaut und eingesetzt. Immer wenn ein Anruf schnell und auf dem direkten Weg Druck, Angst oder ähnliche Gefühle in dir erzeugen möchte, solltest du einen radikalen Cut setzen. Entweder indem du → entschieden dagegen gehst oder auflegst oder ähnliches. Warum so kompromisslos? Weil wir emotionsgeleitet buchstäblich nicht denken können. Nicht weil wir doof sind, sondern weil unser Gehirn so funktioniert. Die Details sind etwas komplexer aber an einem Beispiel: Auf Einschüchterung folgt Angst, folgt das sogenannte “Amygdala Hijacking”, dein “fight or flight” Mechanismus und die Sicherheit von Soft- und Hardware ist buchstäblich vergessen. Extrem wichtiger Punkt! Mehr dazu im nächsten Abschnitt.
Es werden vermeintliche Sicherheiten eingesetzt, um dein Vertrauen zu gewinnen. Wie kann so etwas aussehen? Zum Beispiel wird dir während des Telefonats eine professionell aussehende Webseite angesagt, welche du in Echtzeit anschauen kannst. („Gehen Sie mal auf www. …„) Diese soll beweisen, dass der Anrufer “sauber” ist. Wenn du dir derartiger Tricks allerdings nicht bewusst bist und keine Fähigkeiten wie dem Auslesen von Hyperlinks besitzt, kannst du hier leicht aufs Kreuz gelegt werden. → Sei hier also prinzipiell skeptisch. Je mehr dir jemand etwas beweisen möchte, desto mehr versucht er etwas zu verkaufen. Kann gut sein, kann aber auch böse enden.
So viel zum Thema Phishing Calls for now. Jetzt weißt du, wie du mit einem Phishing Anruf angegriffen werden kannst und wie du dich dagegen verteidigst. (Zumindest grob, die Feinheiten brauchen eine ganze Menge mehr Wörter, aber als 80/20 Variante sollte das schon weiterhelfen)
Doch wie funktioniert die wichtigste Waffe von Phishing-Angreifern? Wie funktioniert das „Amygdala-Hijacking“? Schauen wir es uns an:
Amygdala-Hijacking:
Wie dein Gehirn "vor deinen Augen" gekidnappt wird
Viele Angriffe, egal ob offline oder digital, basieren darauf, dich kampfunfähig zu machen. Im Bestfall für den / die Angreifer, bevor der tatsächliche Angriff beginnt.
Beim Phishing geschieht dies besonders perfide. Denn du siehst den Angreifer nicht einmal und doch kann er dich wie eine Marionette tanzen lassen.
Und das alles nur, indem er die richtigen Knöpfe bei dir drückt.
Der größte und wichtigste Knopf dabei ist deine Amygdala.
Du kannst dir dein „Ich“ in verschiedenen binären Varianten vorstellen; Zukunfts-Ich vs. Jetzt-Ich, Allein-Ich vs. Gruppen-Ich und eben auch Rationales-Ich vs. „Instinkt“-Ich. (Auch hier: vereinfacht gesprochen)
Wenn du normal und ungestört deinem Alltag nachgehst, befinden sich deine höheren Hemisphären, deine Ratio am Steuer. Du kannst dabei gut rechnen, langfristige Pläne schmieden und ausführen und komplexe / abstrakte Handlungen ausführen.
Und dann gibt es noch dein „niederes“ Ich. „Nieder“ im architektonischen Sinne, denn das Gehirn ist aufgebaut wie eine Aufeinanderschichtung von Speiseeiskugeln. Und die unterste Kugel die bei dir im Sommer vielleicht Schokolade ist, ist im Gehirn dein Stammhirn. Und Teil davon ist die Amygdala.
Das ist der „Urzeit-Teil“ in uns allen. Der Teil, der zwischen Mammuts und Säbelzahntigern großgeworden ist und nichts von Computern und Cyberangriffen gehört hat.
Und genau diesen Teil möchten Kriminelle in dir wecken, wenn sie angreifen. Denn wenn dieser Teil am Steuer ist, ist der Rest von dir, deine Ratio in den Keller verbannt. Dann kannst du nur noch in schnellen, einfachen und simplen Lösungen denken. Buchstäblich. Du kannst dann nicht mehr anders denken.
Und so aufs kognitive Kreuz gelegt ist es für Angreifer ein Leichtes, an deiner Verteidigung vorbei und direkt zu den sensiblen Daten zu kommen.
Das ist auch der Grund warum bei Militärnahkampf-Training wie Krav Maga immer auch „Stresstests“ involviert sind.
Um genau diesen blinden Fleck zu trainieren und zu flicken.
Abseits der oben stehenden Checkliste helfen auch Atemtechniken und Meditation. Vor allem aber das Wissen um diese Angriffsmöglichkeit. In diesem Sinne bist du jetzt bereits sicherer, egal was du sonst tust.
Dieser kleine Teil deines Gehirns macht dich quasi sofort “kampfunfähig. Getriggerte Emotionen können deine Amygdala kapern und dich “geistig in die Steinzeit befördern”.
So viel von meiner Seite zum Thema Phishing Anruf. Was mich abschließend noch interessiert ist deine Sicht der Dinge:
Wie gehst du mit der Gefahr von / Phishing Anrufen um?
Wie bereitest du dich auf derartige Angriffe vor?
Hast du Erfahrungen mit Phishing Calls gemacht?
Schreib‘ es mir gern in die Kommentare, ich beantworte jeden Einzelnen und bin gespannt!
Die Bedeutung von Phishing:Wie du dein digitales Sicherheitsrisiko um 96% senken kannst
Phishing ist so etwas wie die „Aufklärungseinheit“ der Cyberkriminellen. Ein falscher Klick und deine persönlichen, gesundheitlichen, Firmen- und andere sensible Daten können Ihre Reise um den Globus antreten. Welche Bedeutung Phishing hat und wie diese ganz konkret an den bei Cyberkriminellen beliebtesten Beispielen aussieht, das und mehr in diesem Artikel.
Es gibt in Sachen Cybersicherheit zwei Arten von Menschen. Die erste ist relativ gut informiert und fragt sich und mich:
Welche Bedeutung hat Phishing für mich in meinem digitalen Alltag?
Die zweite Gruppe ist weniger gut informiert und fragt mit Glück eher:
Was zum Kuckucksei ist Phishing? Und muss ich das überhaupt wissen?
Die Antwort auf beide Fragen ist die gleiche:
Phishing ist eine der gefährlichsten Angriffsmöglichkeiten im Internet. JA, du solltest davon wissen und JA, Phishing hat eine große Bedeutung für dich.
Sogar eine verflixt große: Fast jedes Unternehmen hat Phishing-Attacken auf Ihrer „digitalen Bedrohungsliste“ ganz oben stehen. Das ist einer dieser Fälle, in denen 96% der Befragten nicht falsch liegen können.
Glücklicherweise ist auch der weitere Verlauf der Antwort für beide Fragen gleich. Schauen wir uns in diesem Artikel also die Phishing Bedeutung etwas genauer an.
Konkret erfährst du hier:
Welche Auswirkungen Phishing nach sich ziehen kann
Was genau Phishing so hinterlistig und gefährlich macht
Warum es eher schlimmer als besser wird (es sei denn du bildest dich dazu weiter)
Die 2 bei Cyberkriminellen beliebtesten Fälle von Phishing: Amazon und Paypal
Legen wir los.
Die "wahre" Phishing-Bedeutung
Wie Daten deinen Rechner öffnen wie eine Dose
Lass mich die praktische Phishing Bedeutung mit einer Metapher beschreiben:
Phishing ist wie eine Landmine: Leicht zu übersehen, zu ignorieren und falsch zu behandeln. Wenn allerdings damit falsch umgegangen wird, können die folgen verheerend sein.
Warum ist Phishing so gefährlich? Weil die Folgen auf einen Phishing-„Angriff“ nicht absehbar sind. Es ist ein bisschen wie bei der Klimakatastrophe: Während man voll dabei ist, spürt man maximal ein flaues Gefühl im Magen. Doch sobald der tatsächliche Schaden einsetzt, können die Folgen irreparabel sein.
Denn was kann passieren? Wie oben angesprochen kann der Schaden direkt geschehen, also zum Beispiel sofort nach dem Herunterladen eines Mailanhangs einer Phishing-Mail mein System verschlüsselt und damit „digital gekidnappt“ werden.
Das ist kurzfristig nervig, aber nachdem ich den eigenen Computer einmal grundgereinigt und meine Zugangsdaten geändert habe, geht es meist wieder.
Es kann ebenso passieren, dass sich nach dem Klick auf die Phishing-Mail oder der Eingabe von Daten auf einer Phishing-Webseite ein Tracking-Programm bei mir installiert.
Dieses liest von dann an sämtliche Eingaben in meinen Computer aus und schickt diese Eingaben an den Angreifer. Und dieser hat so vollautomatisch meine Passwörter, Zugangsdaten und sensiblen Dokumentinhalte.
Dieses Szenario ist vor allem so gefährlich, weil ich es unter Umständen viel zu spät oder nie herausfinde.
Es geht aber auch noch schlimmer: Nach meinem “Hereinbitten” des Angreifers durch die Phishing-Kommunikation kann sich auch andere Software installieren. Software, welche meinen Rechner zur “Außenstelle”, zum digitalen “Brückenkopf” weiterer Cyberangriffe macht.
Sodass Angreifer, welche andere Opfer attackieren dies über meinen infizierten Rechner tun. Und die Polizei und Opfer dann bei mir klingeln, statt bei dem tatsächlichen Angreifer. Ich werde also gegen meinen Willen zum “Zombie-Komplizen” gemacht.
Das sind nur 3 Beispielszenarien und aus diesen auch nur kleine Ausschnitte. Die Bedeutung von Phishing sollte also nicht auf die zu leichte Schulter genommen werden.
Die Folgen reichen dabei von Identitätsdiebstahl, Erpressung, Betrug, Diebstahl und Datenvernichtung bis hin zur Beihilfe bei und im schlimmsten Fall der Ermöglichung von Verbrechen.
Und dort hört das Problem noch nicht einmal auf, denn Phishing wird auch immer gefährlicher.
Warum?
Warum Phishing immer gefährlicher, aggresiver und nachhaltig schädlicher wird
Phishing „mutiert“ quasi mit dem Wissenszuwachs seiner Anwender. Was in diesem Dreierhopp geschieht:
Angreifer werden immer besser und “geübter”, da sie schlicht nahezu unendlich viele Angriffsziele haben und die Erfolgsraten ähnlich wie mit Marketingtools exakt bestimmen und tracken können. ⬇️
Dieses Wissen verteilt sich skalierbar und international buchstäblich in Lichtgeschwindigkeit und ⬇️
Wie im echten Leben besteht auch im virtuellen Kampf das klassische Verteidiger-Dilemma: Angreifer haben immer das Überraschungsmoment und die Vorbereitungszeit auf Ihrer Seite. Verteidiger hingegen können immer nur reagieren.
Das ist dir alles zu abstrakt? Dann empfehle ich dir einen kurzen Blick ins “Phishing-Radar” der Verbraucherzentrale. Dort hast du tagesaktuell die aktuell größten Phishing-Fälle aufgezeigt.
Das sieht, am Beispiel einer Phishing Mail zu Paypal, zum Beispiel so aus:
Phishing & Paypal: Eine unfreiwillige, innige Beziehung
Phishing + Paypal = eine explosive Mischung. Das sehen sowohl Cyberkriminelle als auch Kunden von Paypal so.
Doch warum ist Paypal so stark im Fokus?
Aus drei Gründen:
Weil Paypal der Direktlink zu Geld ist.
Weil Paypal Phishing ungleich schwerer nachzuvollziehen ist, als bei anderen Banken. Eine Emailadresse lässt sich problemlos fälschen, ein Konto schwerer.
Weil es skalierbar ist. Wie oben bereits ausgeführt kann ich ohne große Hürden Hunderttausende Mails aus einmal losschicken und meinen Angriffsradius damit maximieren. Ohne das es mir technisch große Probleme bereitet.
Aus ähnlichen Gründen ist der Angriff auf Amazon-Konten auch so interessant. Nur das sich Angreifer dabei kein Geld überweisen, sondern Dinge in Ihre Nähe senden lassen und diese dann gefahrlos abholen.
Deshalb, konkret an den beiden Beispielen Amazon und Paypal: Phishing kann dir deinen Kontostand, deine Beziehungen und deinen Arbeitsplatz verhageln. (Und noch viel mehr, wenn ein Angreifer es darauf anlegt)
Sei also wachsam und achtsam bei jeder Mail und jedem Link den du anklickst!
Welche Bedeutung hat Phishing in deinem Leben bis jetzt / bereits eingenommen? Schreib‘ es mir gern in die Kommentare!
Dieser Beitrag ist Teil meiner Reihe zum Thema Cybersicherheit. Alles auf einen Blick zum Thema Cybersecurity findest du hier. Außerdem habe ich Artikel geschrieben zu den Theman: Cyber Security allgemein, Security Awareness, Social Engineering, IT Security Lösungen und IT-Sicherheit allgemein, Informationssicherheit, Internetkriminalität und Cybercrime, Phishing und spezifischen Schutzwerkzeugen wie zum Beispiel VeraCrypt und Keepass. Mehr zum jeweiligen Artikel findest du beim Klick auf das jeweilige Wort. (Alle Schlagworte ohne Link darüber werden noch veröffentlicht und hier aktualisiert verlinkt) Viel Spaß mit diesem Artikel!
Internetrecherche, bzw. Online Recherche in Netzwerken abseits des Internets hat sich im Kontext von Cyberkriminalität – und Cybersecurity zu einem Damoklesschwert entwickelt. Warum? Nun:
Für Menschen die wissen, wo sie die richtigen Informationen herbekommen, ist das Internet ein einziges Schlaraffenland.
Für Menschen, die hingegen weder wissen, welche Informationen man frei zugänglich erhält und welche ungeahnte Langlebigkeit diese entwickeln können, kann das Internet zur tickenden Zeitbombe werden.
Es ist ein wenig wie mit Atommüll: Wenn ich Halbwertszeit und Gefahr nicht einschätzen kann, unterlaufen mir unter Umständen schwere Fehler.
Deshalb geht es in diesem Artikel um das Thema Internetrecherche. Bzw. noch etwas tiefer: die Informationsbeschaffung rund um komplexere, tiefergehende Themen.
Also nicht nur um das Herausfinden von Anleitungen und Hilfestellungen für kleinere Alltagsprobleme.
Sondern das systematische Erstellen von Profilen, Datenclustern und Interpretationsansätzen des Gefundenen.
Um den Schleier des mysteriösen zu lüften, potenzielle Angriffsvektoren zu negieren und deine Informationsbeschaffung im Internet besser zu gestalten, schauen wir uns dazu einige “Werkzeugkategorien” an.
Unter anderem gehen wir hier darauf ein:
Die 7+1 besten, konkreten Tools / Plattformen für eine erfolgreiche und effiziente Online-Recherche
Best Practises bei der Anwendung und Aussagekraft der Ergebnisse (Plus Erklärung der Triangulation)
Wie du in windeseile, kostenlos und anonym die Technologie einer Webseite, deren Besucheranzahl und vieles mehr herausfindest
Warum im Web Zeitmaschinen existieren und wie du diese einsetzen kannst
Wie dir wenige Zeichen und Klicks an den richtigen Stellen mehr über deine Suchziele verraten
Vieles mehr.
Wichtiger Hinweis vorab:
Da diese Informationen potenziell auch von Angreifern eingesetzt werden können, sende ich dir das im Artikel enthaltene Kurz-Webinar mit den entsprechenden Erklärungen erst nach einem kurzen Schnellcheck deines berechtigen Interesses an dich.
Legen wir los:
Internetrecherche – Wenn Zeit durch Wissen zu Macht wird
Ich arbeite seit einigen Jahren im Rahmen verschiedener Cybersecurity-Aufträge unter anderem als “low-level” Profiler. Ich suche also Informationen über bestimmte Zielpersonen- und Firmen zusammen, bereite diese auf, trianguliere diese wo möglich und sende das Ergebnis dann an meine Auftraggeber.
Mit „triangulieren“ meine ich dabei die drei- oder mehrfache Absicherung eines Ergebnisses durch verschiedene Quellen. Wenn mir also eine Quelle zum Beispiel „1.000“ als Ergebnis ausgibt, prüfe ich mit zwei weiteren Quellen diesen Wert. Wenn dabei von Quelle 2 und 3 „800“ und „1.200“ kommt, weiß ich, dass ich mit „1.000“ im Mittel recht nahe an der wahrscheinlichen Wahrheit liege.
(Wichtiger Unterschied zu “klassischen” Profilern: Ich nutze für meine Recherchen ausschließlich legale, kostenlose und anonyme Tools. Also weder große Geheimdienst-Datenbanken noch ähnliches. Deshalb “low-level”. Reicht aber für ein solides Bild meist schon mehr als aus)
Die Gründe für die Beauftragung eines solchen “Profilings” bzw. einer solch gezielten Internetrecherche sind vielfältig, lassen sich aber meist grob in folgende zwei Kategorien unterteilen:
Ist der/die (potenzielle) Geschäftspartner/Firma zuverlässig und vertrauenswürdig? Im Internet stehen viele Sachen und mit ein wenig Ausdauer kann sich jeder eine professionell wirkende Webseite aufbauen und auf dieser alles erzählen, was er möchte. Ich prüfe, ob es bei einer Webaufstellung mit rechten Dingen zugeht.
Finden sich über mich/meine Familie/meine Firma/ein mir wichtiges Thema Informationen, welche mich angreifbar/erpressbar/kompromittierbar etc. machen?
Zu jeder fundierten / erfolgreichen Cyberattacke gehört eine vorangestellte Recherche. Ohne diese kann ein Angreifer weder herausfinden
Ob sich der Angriff wirklich lohnt
Mit welchen Hürden und Gefahren er bei einem Angriff zu rechnen hat
Noch welche Angriffswege sich besonders lohnen und welche nicht.
Ich schaue im Auftrag des Auftraggebers, welche Informationen ich finde und wie diese möglicherweise gegen ihn verwendet werden können.
Wie so etwas aussehen kann, habe ich in einem kleinen Webinar mal exemplarisch aufgenommen:
Abseits dieses konkreten Ablaufs, der Interpretation der dabei entstehenden Daten und dem Aufzeigen möglicher Angriffsvektoren habe ich dabei vor allem 7 Tools / Werkzeug-Kategorien genutzt. Schauen wir uns die verwendeten Werkzeuge an:
Der 80/20 Internetrecherche-Werkzeugkasten
Ich starte bei allgemein hilfreichen Tools und Tipps und gehe dann auf die spezielleren Werkzeuge bzw. Tipps zur Online Recherche ein.
1. Besser im Internet suchen: Der Einsatz von Suchoperatoren
Suchoperatoren ermöglichen es, ähnlich und meist sogar präziser als Hashtags, Internetsuchen “spitzer” zu machen. Das heißt die eigene Suchanfrage mithilfe ergänzender Informationen spezifischer zu formen. Und damit schneller und exakter zum gewünschten Ergebnis zu gelangen.
Wie kann so etwas aussehen? Das einfachste Beispiel ist eine „Suche nach Walt Disney“. Wenn ich einfach so nach der Keyword-Kombination „Walt Disney“ suche, bekomme ich alle Informationen zum Konzern, seinen Angeboten, seinem Gründer usw.
Wenn ich allerdings nur nach dem Gründer suche, kann ich Anführungszeichen um meinen Suchbegriff hinzufügen. Und damit die Suchergebnisse auf den Firmengründer beschränken.
2. Indirekt auf Fragen und Wissen anderer zugreifen: Autocomplete
Die Autocomplete-Funktion von Google ist eine weitere Möglichkeit die eigenen Suchergebnisse anzureichern. In diesem Fall nicht durch Präzision, sondern durch den Zugriff auf indirekte Daten des “Schwarmbewusstseins”.
Es gibt verschiedene Varianten dieser automatischen Vervollständigung, die zwei praktischsten sind diese beiden:
Die obige findest du am unteren Ende jeder Google-Suchergebnis-Seiten.
Die untere findest du, wenn du eine Seite aus der Google-Suche heraus öffnest und dann direkt wieder zurück zur Suche gehst.
In diesem Fall werden dir weitere Suchen vorgeschlagen, welche andere User ausgeführt haben, nachdem sie ebenfalls wieder zurück zur Google-Suche geschickt wurden. Der Ablauf ist dabei meistens:
Eingabe eines Suchbegriffs, zum Beispiel “Cybersecurity”
Klick auf das erste organische Ergebnis.
Unzufriedenheit mit dem Inhalt dieser Ergebnisseite.
Klick zurück zur Google-Suche.
Aufploppen der Autocomplete-Leiste unter dem angeklickten Ergebnis.
Sollte das bis hierhin noch immer zu abstrakt klingen, ich erläutere die Details in meinem Webinar zur Internetrecherche. Du kannst dich für dieses hier kostenfrei anmelden:
Die Vorschläge dieser beiden Autocomplete-Widgets helfen, ein besseres Gefühl für das Thema zu bekommen. Und manchmal bringen Sie sogar bisher völlig unbeachtete Ideen und Verknüpfungen zum Vorschein.
Probier’s zwei- dreimal aus, dann verstehst du, was ich meine 😉
3. Über Bilder zu völlig neuen Verknüpfungen: Reverse Image Search
Reverse Image Search ist eine Informationssuche, nur mit Bildern statt Begriffen.
Heißt: Ich gebe keinen Schlüsselbegriff in den Suchschlitz ein, sondern ein “Schlüssel-Bild”.
Die Reverse Image Search eignet sich prinzipiell für alle Suchen, die auf einem Bild basieren. Im Besonderen allerdings für:
Die Quelle von Infografiken / Statistiken etc. Reverse Image Search findet dabei sogar Quell-PDF’s, aus welchen diese im Original stammen.
Ähnliche Bilder wie das Quellbild. Egal ob in verschiedenen Größen, anderen Farben oder zuweilen auch veränderten Strukturen: Mit Reverse Image Search findest du auf einen Klick den “digitalen Kontext” rund um dein Quellbild.
Artikel, Publikationen und generell den Kontext des Quellbildes. Mit der Rückwärts-Bilder-Suche findest du oftmals binnen weniger Sekunden Artikel und Webseiten, welche dein Quellbild eingebunden haben. Damit kennst du nicht nur die Originalquelle, sondern zeitgleich auch andere Medien, welche das Bild nutzen. Was dir wiederum hilft, deine Internetrecherche zu vertiefen und zu verbessern.
Eine kurze Anleitung der Reverse Image Search zeige ich in meinem Online Recherche Webinar. Du kannst dich hier dafür kostenfrei anmelden:
4. Röntgenblick in den Maschinenraum: Die Technologie-Analyse
Es gibt verschiedene Online-Tools mit denen man die Rahmendaten einer Webseite analysieren kann.
Mit diesen Tools findet man zum Beispiel heraus:
Das Content-Management-System (CMS)
Eingesetzte Plugins / Add-ons
Hoster
Frameworks
Content Delivery Networks (CDN’s)
Spezifische Mobile-Optimierungen
Kartierungsservices
Eingesetzte Zahlungsabwickler
Mediaplayer
Script-Bibliotheken
Werbeservices
Historie der meisten obigen Punkte
… Vieles mehr, je nach Webseite.
Trianguliert mit anderen Tools wie dem Webarchive kann man so sogar die verschiedenen Versionen der Seite anschauen, ohne bei deren Bau beteiligt gewesen zu sein.
Das hat verschiedene gravierende Vorteile:
Sollte ich am Bau einer Webseite beteiligt sein, kann ich so auf einen Blick ein Gefühl für die bisherigen Technologien, Stile etc. bekommen. Ohne mich abstimmen zu müssen. (Das hat manchmal einen leichten Hauch von Magie, wenn man einem Kunden sagen kann, wie seine Seite aufgebaut ist, war und basierend darauf Empfehlungen geben kann. Ohne überhaupt die Zugangsdaten zu haben)
Inspiration für eigene Einsätze von Tools und Plugins. (Wenn ich die Top-Seiten meiner Nische kenne, kann ich mich an deren Plugins orientieren, um stets up to date zu bleiben)
Das Herausfinden potenzieller Sicherheitsschwachstellen um diese schnell zu fixen. (Hilft vor allem bei der Prävention von Social Engineering Attacken. Mehr dazu im Webinar)
5. Reise in die Vergangenheit: Der Einsatz von Web-Archiven
Ich kann nicht nur mit Technologie-Analysen in die Vergangenheit einer Webseite schauen. Webarchiv-Lösungen erlauben mir dies nicht nur “unter der Haube”, sondern buchstäblich.
Die Seite des Spiegels sieht seit vielen Jahren nahezu gleich aus. So zum Beispiel im Jahr 2013. Q: WebArchive
So kann ich zum Beispiel vergangene Design-Entscheidungen auf den Tag genau nachvollziehen, Aktualisierungs-Schemas herausfinden und vieles mehr.
Auch dies hilft vor allem allen Branchen rund um Webdesign- und Entwicklung. Und im Bereich Social Engineering. Wieso letzteres, erläutere ich in meinem Webinar zum Thema.
6. Webauftritte auf einen Blick analysieren: Der Traffic-Scan
Traffic ist die Summenbezeichung aller “Benutzer-Ströme”, die durch verschiedene Quellen auf meiner Webseite landen. Diese Quellen können zum Beispiel Social Media, Suchmaschinen, Newsletter oder andere sein.
Q: Semrush
Ein schneller Scan dieses Traffics und seiner Zusammenstellung hilft, um Aussagen zu prüfen.
Zum Beispiel, wenn ein Kunde / potenzieller Geschäftspartner / Influencer etc. behauptet, er habe
Eine starke Präsenz in seiner Marktnische
Sehr viele Besucher im Monat, wodurch sich eine Werbepartnerschaft lohnt
Eine eigene Marke, welche stark in seiner Nische repräsentiert ist.
… Und so weiter und so ähnlich
Je nach Nische, Größe und einigen weiteren Faktoren kann man hierbei mit wenigen Klicks und einem geübten Auge die Aussagen der anderen Partei entweder validieren oder widerlegen.
Wie ich dabei vorgehe, was mir verschiedene Tools sagen und mehr erfährst du in meinem kostenlosen Webinar.
7. Wer mit wem seit wann wobei: Triangulation von Firmendaten
Web- und Webseitendaten sind hilfreich und wichtig. Gerade bei Geschäftspartnern und potenzieller Zusammenarbeit mit anderen Firmen reichen diese allerdings häufig nicht aus.
Für diese Spezial- und Vertiefungsfälle gibt es Werkzeuge, welche einem einen Einblick hinter die Kulissen geben.
Q: Northdata
Gerade wenn man zum Beispiel das Netzwerk rund um einen Geschäftspartner kennenlernen möchte, helfen verschiedene Firmendaten-Tools schnell weiter.
Diese bringen einem unter anderem Informationen zu den Themen:
Firmenhistorie
Handelsregistereinträge
Involviertes Personal in Spitzenpositionen
Aufgekaufte Firmen
Und vieles weitere.
Auch hier gilt wie immer: Ein Tool allein bringt selten den Erfolg. Doch in Kombination ergibt sich oftmals ein detailliertes und aufschlussreiches Bild.
Mehr zu den konkreten Tools und deren Anwendungsfällen erfährst du in meinem kostenlosen Webinar.
Wie oben bereits angesprochen, kann Social Media ein hervorragender Informationsstrom sein. Und das ist nicht auf Traffic begrenzt.
Mit Social Media-Plattformen findet man oftmals auch sehr detaillierte Informationen über konkrete Personen und Firmen heraus.
Das können zum Beispiel sein:
Gruppen
Gelikte Seiten
Postings und deren Historie
Verwendete & verlinkte Hashtags
Netzwerk
… Und vieles weitere.
Da verschiedene Netzwerke verschiedene Facetten einer Person in den Fokus stellen, bietet sich die Triangulation über alle zur Verfügung stehenden Plattformen an.
Das können zum Beispiel sein:
Die Klassiker wie Facebook, Xing und LinkedIn
Etwas exotischere / spezifischere wie zum Beispiel ResearchGate
In seltenen Fällen verknüpfte wie Pinterest oder Etsy
Besonders die Hashtag-Funktion vieler Social Media Netzwerke ermöglicht es dabei, auch aus einer völlig anderen Dimension heraus fündig zu werden. Und damit weitere relevante Informationen zur Internetrecherche zu gewinnen.
Mehr dazu findest du, du hast es vielleicht kommen sehen, in meinem kostenfreien Webinar zur vertieften Online Recherche und deren Implikationen für Cybersecurity & Co.
Internetrecherche und Online Recherche – Fazit:
Der richtige Umgang im Internet braucht ebenso Werkzeuge wie das klassische Handwerk. Ein Hammer tut andere Dinge als ein Schraubenzieher. Doch wenn ich eines von beiden nicht beim Einsatz dabei habe / nicht damit umzugehen weiß, bringt mir das alles nichts.
Ein Bereich mit vielen hilfreichen Werkzeugen ist die Online- / Internetrecherche. Ein paar Tools- bzw. Toolgruppen habe ich dir hier aufgezeigt und erklärt.
Dieser Beitrag ist Teil meiner Reihe zum Thema Cybersicherheit. Alles auf einen Blick zum Thema Cybersecurity findest du hier. Außerdem habe ich Artikel geschrieben zu den Theman: Security Awareness, Social Engineering, Internetrecherche, IT Security Lösungen und IT-Sicherheit allgemein, Informationssicherheit, Internetkriminalität und Cybercrime, Phishing und spezifischen Schutzwerkzeugen wie zum Beispiel VeraCrypt und Keepass. Mehr zum jeweiligen Artikel findest du beim Klick auf das jeweilige Wort. (Alle Schlagworte ohne Link darüber werden noch veröffentlicht und hier aktualisiert verlinkt) Viel Spaß mit diesem Artikel!
Cyber Security ist für deinen Ausflug in die weiten des Cyberspace ungefähr das, was Kleidung, die eigenen vier Wände und Schlösser in der echten Welt sind:
Cyber Security ist alles, was du brauchst, um den Launen der Natur dieser Dimension nicht schutzlos ausgesetzt zu sein.
Sie ist, richtig eingestellt, im virtuellen Alltag unsichtbar. Und bis etwas schiefgeht, bekommst du so oder so nichts davon mit.
Doch wie so oft gilt: Du merkst erst dann was dir fehlt, wenn es zu spät ist. Und dann umso schmerzhafter.
Nirgendwo sonst gilt das so intensiv wie im Bereich der Cyber Security:
Ungesicherter Cyberspace ist ein Schlaraffenland für Kriminelle und sonstige Angreifer. Schätzungen zufolge sind mehr als 20 % aller Dateien im Netz ungeschützt. (Während zeitgleich der größte Schaden bei Angriffen durch den Verlust sensibler Informationen entsteht)
Cybercrime ist lukrativer als der weltweite Drogenhandel, und zwar um ein Vielfaches. (Was klar ist, denn bei skalierten Unternehmen skaliert sich der Schaden ebenfalls)
Weitere “Horrorstatistiken” wie diese finden sich hier zusammengestellt.
Kurzum: Wer nicht ausreichend auf seine Sicherheit im virtuellen Raum achtet, hat nur eine Alternative: Diesen zu verlassen. (Was, Digitalisierung Ahoj, seit langer Zeit keine Option mehr ist)
Aus diesen und weiteren Gründen schauen wir uns in diesem Artikel die wirkungsvollsten Mechanismen, besten Quellen und die Zukunft der Cyber Security an.
Konkret erfährst du in diesem „Rundum“-Artikel zum Thema Cyber Security:
Was ist Cyber Security?
Wie funktioniert Cyber Security nachhaltig?
Kann man Cyber Security messen?
Welche Voraussetzungen braucht Cyber Security?
Welche Gesetze gelten rund um diese?
Welche konkreten Maßnahmen kann man ergreifen um im Cyberraum sicher zu sein?
Was hat es mit dem NIST-Framework auf sich?
Wo geht die Zukunft der Cyber Security hin?
Vieles mehr…
Angeschnallt, die Fahrt geht los:
Was versteht man unter Cyber Security?
Fangen wir von vorn an: Was ist Cyber Security?
Ausführlicher habe ich diese Frage bereits in meiner Übersichtsseite zum Thema Cybersecurity beantwortet, doch eine einfache Definition zur Orientierung kann sein:
Cyber Security umfasst alle Maßnahmen um sicher in der digitalen Welt agieren zu können. (sicher zum Beispiel vor Datenverlusten oder Angriffen)
Es ist also ein wenig wie ein Picknickkorb, in welchem alle wichtigen Dinge eingepackt sind, damit das Picknick ein voller Erfolg wird.
Grundlagen der Cyber Security sind vor allem Informatik und Psychologie.
Ersteres, weil die digitale Welt aus Daten, Informationen besteht und Informatik daher Ihre “Naturgesetze” bestimmt.
Und zweiteres, weil der Cyberraum letzten Endes von Menschen bevölkert wird und sich daher um den Menschen dreht.
Es gibt natürlich noch viele weitere beteiligte Disziplinen wie Mathematik, Webdesign, künstliche Intelligenz etc. Aber diese beiden sind der Kern des ganzen.
Wie funktioniert Cyber Security?
Will man Cyber Security angemessen erklären, muss man zunächst die Mechanismen und den “Tanz” von Angreifer und Verteidiger erklären.
Dieser funktioniert im Kern genau wie das endlose Wettrüsten von Dieb und Detektiv in der echten Welt: Der Dieb versucht immer neue Methoden, setzt immer neue Techniken und Geräte ein, um den Detektiv zu überlisten. Und der Detektiv rüstet seinerseits immer weiter auf und bildet sich konstant weiter aus.
Im Wesentlichen ist Cybercrime- und Security genau dieser endlose Kreislauf aus Schwert und Schild, Kanone und Mauer.
Mit einem gewichtigen Unterschied: Im virtuellen Raum gibt es keine Identitäten, keine Möglichkeiten Angreifer zu identifizieren, besteht keine Notwendigkeit, tatsächlich den eigenen Computer zu verlassen. Ein Aggressor kann dich hacken und deine digitale Identität zum Pokerspielen auf den Philippinen nutzen, während er selbst in einem Bergcafé in Grönland sitzt.
Cybercrime ist theoretisch das perfekte Verbrechen. Es gibt keine Zeugen, keine Verletzten und keine Spuren. Alles ist verschlüsselt und verschleiert. Zumindest im Schlimmstfall. Oft sind die Angreifer nicht gut genug, um wirklich spurlos zu bleiben. Doch das ändert nichts an der Dimension dieser Gefahr: Gegen Cyberkriminalität helfen keine Türen und keine Schlösser. Du kannst eine Attacke weder spüren noch hören.
Cyberkriminalität ist die “dunkle” Seite der Digitalisierung: von überall aus einsetzbar, ohne große Teams und Organisationen effektiv und mit Skaleneffekten in jede mögliche Richtung.
Digital ist es egal, ob du 10 oder 10.000 Kunden hast. Und für Angreifer ist es egal, ob sie 10 oder 10.000 Datensätze erbeuten.
Deswegen ist Cyber Security von solch enormer Bedeutung. Sie ist wie ein Lichtschalter für deine digitalen Aktivitäten. Egal ob privat oder beruflich. Wenn du gehackt bist, kannst du virtuell prinzipiell ausgeschaltet werden und bist auf die Gnade / Langeweile deines Angreifers angewiesen.
Kein schöner Gedanke, oder?
Welche Herausforderungen tun sich im Zusammenhang mit Cyber Security auf?
Cyber Security ist, wie oben angesprochen, ein wirklich umfangreiches und komplexes Thema. Daraus entsteht bereits die erste Hürde: Zu überblicken, was wichtig ist und wie man es einsetzen kann.
Doch es gibt noch einige weitere Hürden / Herausforderungen:
Die Frage der Angemessenheit: Sollte ich als Privatperson meine Daten mit einem militärischen Verschlüsselungsstandard sichern, oder reicht da auch weniger?
Die Frage des richtigen Starts: Welche der zahlreichen Maßnahmen sollte die erste, zweite und dritte sein, um mich angemessen abzusichern?
Die Frage des Zeitpunktes: Welche Lösungen brauche ich heute und welche morgen? Und welche brauche ich gar nicht mehr, weil sie Schnee von gestern sind?
Die Frage der richtigen Wahl: Welches Programm, welchen Anbieter sollte ich wofür nehmen? Und wann reicht dessen Service nicht mehr aus?
…
Wie gesagt, das sind nur einige der Herausforderungen wirklich wasserdichter Cybersicherheit. Doch diese zeigen gut, warum zumindest ein solides Grundverständnis unersetzlich ist.
Kann man Cyber Security messen?
Eine Frage kommt immer wieder im Bereich der digitalen Sicherheit auf:
Gibt es einen objektiven “cyber security index”? Also eine Möglichkeit die eigene Firmensicherheit ungetrübt zu messen? Und wenn, gibt es diesen auch noch länderübergreifend? Gar weltweit?
Die Kurzantwort: Ja und nein. Ja, es gibt einen “offiziellen” Cyber Security Index der internationalen Telekommunikations-Union (ITU), der Agentur für Informations- und Kommunikationstechnologien der vereinten Nationen. Dieser wurde zuletzt 2018 veröffentlicht und sieht “von oben” betrachtet so aus:
Aber auch zeitgleich nein. Warum? Weil es mindestens so viele “objektive Indizes” gibt, wie es Cyber Security-Firmen auf der Welt gibt. Denn jede Firma möchte natürlich besser als die anderen nachweisen und dem Kunden Vormessen können, dass seine Leistung die beste ist.
Heißt: Es gibt Möglichkeiten, gute wie weniger gute, objektive wie subjektive, Cyber Security zu messen. Doch welche davon besser als andere sind, in welchem Maßstab etc. ist eine andere Frage, welche sich nahezu nicht pauschal beantworten lässt.
Welche Voraussetzungen braucht Cyber Security?
Um Cyber Security richtig einsetzen zu können, braucht man gewisse grundlegende Informationen. Man sollte vor einer Cyber Security-Strategie zum Beispiel
sein System kennen
seine Anforderungen kennen
sein Budget kennen
den Rahmen der Umsetzung grob verstehen und vorgeben können.
Warum ist Cyber Security wichtig?
Nachdem wir die Grundlagen erörtert haben, noch eine kleine Geschichte zur Verdeutlichung der Wichtigkeit von Cybersicherheit in zwei Bildern:
Weitere Angriffsszenarien etc. findest du auf meiner Hub-Seite zum Thema Cybersecurity.
Welche Gesetze gelten für Cyber Security in Deutschland?
Abseits der offensichtlichen Bedrohungslage und permanenter Angriffsflächen ungeschützter Systeme kann auch der gesetzliche Druck bestehen, die eigenen Systeme zu sichern.
Vor allem bei systemkritischen Infrastruktur-Betreibern ist dies der Fall.
Cyber Security ist vor allem auf Team- und Management-Level extrem wichtig. Warum? Weil nur mit einer offenen, vertrauensvollen Struktur und Kultur destruktive Szenarien vermieden werden können. Wie zum Beispiel:
Das Ausspielen des / der Teams gegeneinander (weil diese keine Informationen miteinander teilen, weil sie zerstritten sind oder dergleichen)
Das Ausnutzen von Informationslücken zwischen den Teams (Weil das eine Team das andere nicht informiert über Fortschritte, Planung etc.)
Das Missbrauchen von strengen Hierarchien (indem die nicht hinterfragte Hörigkeit nach “Oben” dazu führt, dass sensible Daten in die Hände von Angreifern gelangen)
Es gibt noch Dutzende, wenn nicht hunderte weitere Angriffsszenarien wie diese. Und alle basieren auf Firmenkultur- bzw. Struktur.
Deswegen sind Team und Management welche diese vorlebt so wichtig.
Angriffsziel Deutschland: Cyber Security für den Mittelstand
Was uns direkt zum nächsten Punkt bringt: Da wir in Deutschland sehr viele Hidden Champions, Weltmarktführer in spezifischen Nischen und technisch exzellente Mittelstandsfirmen haben, bieten sich für Angreifer hier sehr lukrative Ziele.
Da diese Firmen wie gesagt oftmals technisch sehr fit und Angriffe gegen unsichere Mitarbeiter viel einfacher sind, attackieren Aggressoren dementsprechend auch eher den Menschen hinter dem Bildschirm.
Mehr dazu inklusive konkreten Schutz-Strategien findest du auch auf meiner Seite zur Security Awareness.
Cyber Security Maßnahmen
Nachdem wir jetzt die verschiedenen Blickwinkel rund um die Grundlagen der Cybersicherheit kennen, kommen wir zur konkreten Umsetzung.
Welche Cyber Security Maßnahmen bringen den meisten “Bang per Buck”, den größten Effekt pro eingesetzter Ressource?
Im Wesentlichen lassen sich Cyber Security Maßnahmen grob kategorisieren in:
Strategie: Ein individuelles, einsatz- geprüftes Cyber Security Konzept.
Taktik: Permanent verbesserte Cyber Security Awareness, also das Sicherheitsbewusstsein aller beteiligter Personen
Backup: Dem Cyber Security Notfallplan, für den Fall eines Angriffs und
Rahmen: Der Kenntnis des Cyber Security NIST-Frameworks als Grundlage und Ergänzung dieser Pfeiler.
Schauen wir uns die wichtigsten Cyber Security Maßnahmen nachfolgend etwas genauer an:
Cyber Security Awareness: Sicherheitsbewusstsein als beste Waffe gegen jede Attacke
Wie bereits mehrfach angesprochen, ist Security Awareness eine der wichtigsten Verteidigungsstrategien gegen jeden digitalen Angriff. Denn diese ist die direkte Antwort auf das größte Einfallstor von Cyber-Kriminellen.
Deswegen sollte Cyber Security Awareness immer ganz oben auf jeder Maßnahmen-Liste stehen.
Was ist das Cyber Security NIST Framework? – Und warum ist es so wichtig?
Vom Notfallplan zu einem der wichtigsten Dokumente der gesamten Cybersicherheit: Dem Cyber Security NIST Framework.
Was ist das Cyber Security NIST Framework, was tut es und warum ist es so wichtig?
Das “Framework for Improving Critical Infrastructure Cybersecurity” des National Institute of Standards and Technology – oder kurz “NIST Framework” ist so etwas wie die Leitplanke der Cybersicherheit.
Warum? Weil es keine so kompakte, so wohl gewählte Alternative zu diesem gibt.
Es ist insgesamt 48 Seiten lang, wobei die ersten und letzten 4 Seiten Intro und Begriffserklärungen sind.
Wir haben jetzt also die Grundlagen, Dringlichkeit und Maßnahmen rund um das Thema Cyber Security näher beleuchtet.
Bleibt nur noch ein wichtiger Punkt: Die Zukunft dieses komplexen Feldes.
Und die bleibt spannend!
In absehbarer Zeit gibt es drei zentrale Trends, welche sich massiv und grundlegend auf die Cyber Security auswirken werden:
Cyber Security Trend #1: Stärkerer Einsatz künstlicher Intelligenz
“Künstliche Intelligenz (KI) ist die letzte Erfindung, welche die Menschheit machen muss. Ab dann übernimmt den Rest die KI selbst.”
So oder so ähnlich geht die aktuelle Diskussion rund um dieses gigantische Gebiet in Kurzform.
Die Idee dahinter, wieder in kurz, geht ungefähr so: Künstliche Intelligenz kann automatisiert schneller und besser im Digitalraum navigieren, als es ein Mensch je könnte.
Heißt: Alles von Innovation über Testing und Kundenmanagement bis hin zur Auslieferung übernimmt zum Großteil die KI.
Abgesehen davon, dass wir uns aktuell mit Höchstgeschwindigkeit in genau diese Richtung entwickeln, birgt diese “erweiterte Virtualisierung” noch weitere, eklatante Herausforderungen:
Wenn sich alles schneller und besser automatisieren lässt, gilt dies auch für Cyberattacken? Und, hoffentlich auch für Cyber Security?
Die Kurzantwort: Wahrscheinlich. Sehr wahrscheinlich. Viele Cybersecurity-Experten sehen ein großes Automatisierungspotenzial sowohl in den Anwendungen, als auch in Ihren Aufgabenbereichen.
Vielleicht haben wir also bald virtuelle Assistenten, die miteinander sprechen. Und die Sicherheit erledigen diese direkt von selbst in diesem Schritt mit.
Das kann in vielen verschiedenen Teilbereichen geschehen, aber auch “am Stück”.
Cyber Security Trend #3: Immer perfidere und ausgeklügeltere Social Engineering-Strategien
Der letzte große, absehbare Trend in der Cyber Security sind immer komplexere Angriffe gegen die Anwender. Diese Attacken werden immer
Individueller
Präziser
Kontextsensitiver und
Datenunterfütterter
Es wird also immer herausfordernder für User zum Beispiel Spam- und Phishingmails effektiv zu erkennen und zu filtern.
Auch hier werden mehr und mehr technische Hilfen auf den Markt kommen. Doch am sichersten bleibt nach wie vor eines: das Grundverständnis der relevanten Angriffspunkte.
Wie eine solche fortgeschrittene Attacke begonnen werden kann und welche Daten dabei herausgefunden werden können, zeige ich in meiner Mikro-Schulung zum Thema:
Diese Webseite nutzt Cookies um bestmöglichen Service zu garantieren. This website uses cookies to improve your experience. Ich habe verstanden!Mehr Informationen
Datenschutz
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.