Diese Übersicht bietet meiner Meinung nach eine brauchbare Mischung aus Abstraktion und Tiefe um mit einer konkreten Vorstellung weiterzumachen. Basierend darauf kann man aus Sicht der Medizin vielleicht folgendes ableiten:
“Bei Künstlicher Intelligenz handelt es sich um die künstliche, maschinelle Generierung von datenbasiertem Wissen.”
Da man mobile Speicher nicht behandeln und klassisch analysieren kann, ergibt der Fokus auf die maschinelle statt menschliche, daten- statt gedankengestützte Betrachtung meiner Meinung nach absolut Sinn. Und diese kleine Facette rundet unser bisheriges Spektrum zeitgleich sinnvoll ab.
Künstliche Intelligenz Definition aus der Psychologie
“(= K. I.) [engl. artificial intelligence], [KOG], K.I. stellt in den Vordergrund, Intelligenz in technischen Systemen zu erzeugen … K. I. versteht unter I. die Fähigkeit, durch effiziente Informationsverarbeitung herausragende Problemlösungen bzw. Anpassungen an die Umwelt zu ermöglichen.”
Im Kontext der medizinischen Betrachtung finde ich die psychologische besonders spannend. Ist ihr Schwerpunkt doch zeitgleich abstrakt und doch konkret. Und vor allem werfen die Schlüsselwörter „effiziente Informationsverarbeitung“ auch nochmal ein klein wenig anderes Licht auf unsere bisherigen Ansätze von Problemlösung bis Gehirnimitation.
Historische Definitionen von künstlicher Intelligenz
„KI-Technologien sind als Methoden und Verfahren zu verstehen, die es technischen Systemen ermöglichen, ihre Umwelt wahrzunehmen, das Wahrgenommene zu verarbeiten und selbständig Probleme zu lösen, Entscheidungen zu treffen, zu handeln und aus den Konsequenzen dieser Entscheidungen und Handlungen zu lernen.“
Diese Definition ist von besonderer Bedeutung, entspringt sie doch den Köpfen der Autoren des populärsten Grundlagenwerkes der Welt in der Akademie rund um künstliche Intelligenz. Interessanterweise geht es hier auch primär um die „Methoden und Verfahren“ mit denen alles weite passiert, als um Informationsverarbeitung, Problemlösung etc. Es mag nach Haarspalterei klingen aber ich finde so langsam verdichten sich die Startpunkte.
#42: John McCarthy im Rahmen des Dartmouth Workshops, der “Grundsteinlegung” für künstliche Intelligenz
“thinking machines”
Dieser, allen anderen durch seine enorme Kürze herausragende, ist der möglicherweise wichtigste Ansatz von allem. Warum? Weil er im Rahmen der Grundsteinlegung der künstlichen Intelligenz gelegt wurde. Denn im Sommer 1956 wurde das Feld der KI erst offiziell begründet. Mit diesen beiden Worten als Definitionsansatz.
Ist das nicht faszinierend?
Und entsprechend interessant ist auch sein Ansatz. Denken + Maschine = künstliche Intelligenz.
Was uns zu einem anderen Pionier der künstlichen Intelligenz führt:
#43: Eine künstliche Intelligenz Definition die nicht fehlen darf: Der Turing Test
Eine künstliche Intelligenz Definition schreiben zu wollen, ohne Alan Turing zumindest zu erwähnen, halte ich für schwierig. Daher, auch wenn keine Definition explizit auf ihn eingeht, hier ein kurzer Absatz zum Turing-Test. Zum Auffrischen, was war der Turing Test nochmal?
In kurz: Eine Jury kommuniziert indirekt, also zum Beispiel durch einen Computer mit einer KI auf der einen und einem Menschen auf der anderen Seite. Dabei versucht der Juror durch gezielte Fragen herauszufinden, wer der Mensch und wer der Algorithmus ist. Wenn die KI es schafft den Juror von seiner „Menschlichkeit“ zu überzeugen, haben wir die erste „starke“ KI.
Abgeleitet daraus könnte man also sagen:
Eine künstliche Intelligenz ist jeder intelligente Algorithmus / Programm, welches / welcher den Turing Test besteht.
Den Turing Test gibt es mittlerweile in Dutzenden, wenn nicht Hunderten verschiedenen Varianten. Und täglich bestehen künstliche Intelligenzen mehr und mehr dieser Varianten. Egal ob sie besser Bilder interpretieren können, Kunstwerke zeichnen und Musikstücke komponieren oder feinere Klänge und Frequenzen wahrnehmen. Jeden Tag wird eine künstliche Intelligenz besser in einem kleinen Spezialgebiet, welcher bisher vom Menschen „dominiert“ wurde.
Auch eine Art langsamer technologischer Singularität, oder?
KI Definitionen von Praktikern und Experten
“Oberbegriff für alle Technologie, die sich mit der Intelligenz, wie sie bisher nur dem Menschen vorbehalten war, beschäftigt.”
…Und wieder eine neue Facette im KI-Bingo! Diese ist interessant, denn hier liegt der Schwerpunkt auf Technologie im allgemeinen, nicht auf Computern, Programmen oder sonstigen Systemen. Sondern hier geht es um materialisierte, intelligente Lösungen jeder Art.
“Künstliche Intelligenz ist die Simulation menschlicher Intelligenzprozesse durch Maschinen, insbesondere durch Computersysteme.”
Hier geht es um Simulation, anders als Imitation wie vormals. Dennoch ist die Vorlage auch hier wieder der Mensch. Nachvollziehbar aber so langsam auch etwas eintönig, oder wie geht’s dir?
“Künstliche Intelligenz (KI) bedeutet, dass ein Computer Aufgaben löst, die sonst nur durch einen Menschen bewältigt werden können.”
Bei LwM geht es mehr um die Aufgaben, welche die Maschine löst, als den Menschen oder die Intelligenz oder die Lösung des Problems selbst. Kann man machen, führt aber schnell zu der Frage: Ist etwas intelligent, nur weil es intelligent wirkt? Ab hier verweise ich nach oben zur Philosophie, denn genau diese stellt sich diese Frage. (Stichwort chinesisches Zimmer)
“…maschinelles Lernen und die Fähigkeit von Computern, eigenständig Probleme zu bearbeiten.”
Bei diesem Ansatz kommt nicht viel Neues hinzu, außer das explizit auf maschinelles Lernen hingewiesen wird. Hier lernt nichts Abstraktes, nichts einfach nur „künstliches“, hier lernt explizit die Maschine. Warum ist das relevant? Weil maschinelles Lernen mittlerweile sogar eine eigene Sparte im Forschungsfeld künstlicher Intelligenz ist.
“machines that respond to stimulation consistent with traditional responses from humans, given the human capacity for contemplation, judgment, and intention.”
In diesem künstliche Intelligenz Definitions-Ansatz steht die Art der Reaktion auf Input im Vordergrund. Erfrischend, aber alles andere als neu an diesem Punkt.
„Artificial intelligence is the application of rapid data processing, machine learning, predictive analysis, and automation to simulate intelligent behavior and problem solving capabilities with machines and software.“
Bei diesem Ansatz steht die Art der Anwendung verschiedener Werkzeuge um ein intelligentes Ergebnis zu erzielen im Fokus.
Quasi Zucker + Mehl + Wasser = Kuchen.
Interessant ist hierbei auch, dass zwischen Maschinen und Software unterschieden wird. Kurz vorm Schluss kommt immer noch etwas neues hinzu. Schön, oder?
„Artificial intelligence (AI) applies advanced analysis and logic-based techniques, including machine learning, to interpret events, support and automate decisions, and take actions.“
Auch diese künstliche Intelligenz Definition geht nach dem Ablauf „Anwendung von Hacke und Schaufel“ „mit dem Ziel x“ vor. Praktisch und ergebnisorientiert zugleich.
Mit am besten gefällt mir persönlich ja die mehr kontextuell gemeinte Definition von DeepMind-Gründer Demis Hassabis:
“No matter what the question is, AI is the answer.“
Künstliche Intelligenz ist wahrscheinlich die letzte Erfindung, die der Mensch noch selbst kreieren muss. Sobald sie, in „starker“ Form zumindest, existiert, übernimmt sie die Innovation dann. Schneller und effizienter als jeder Mensch es jemals könnte.
Von daher ist dieser Ansatz lösungs-zentriert aus der Vogelperspektive. Und erfrischend „exotisch“ wie ich finde.
„AI is automation on steroids.“
Andrew Ng hat Google und Baidu, also respektive die USA und China ins KI-Zeitalter geführt. Und damit die gesamte Welt gleich mit. Daher halte ich seine Sichtweise bzw. seinen Definitionsansatz für besonders interessant. Die Automatisierung hat uns in ein Zeitalter des Material-Überflusses katapultiert. Wird künstliche Intelligenz jetzt das Zeitalter des Lösungs- bzw. Wissensüberflusses einleiten?
Künstliche Intelligenz Definitionen aus der Community
Damit haben wir einen für den Anfang erschöpfenden Überblick denke ich. Doch Entwickler und Erschaffer sind nur ein Teil der involvierten Gruppe bei künstlicher Intelligenz. KI geht jeden an. Daher folgerichtig die Frage:
Was sagen Hobbyinteressierte, Bastler und Coder, Ethiker und Ingenieure zum Thema?
Ich habe mich in einigen der größten Gruppen, die ich dazu finden konnte umgehört. Das sind die besten Antworten:
Wikipedia als Schnittstelle zwischen Disziplinen und Community sagt dazu:
“Teilgebiet der Informatik, welches sich mit der Automatisierung intelligenten Verhaltens und dem maschinellen Lernen befasst.”
Teil der Informatik, Automatisierung und maschinelles Lernen. Alles schon mehrfach gehört, klingt nach einer vertretbaren künstliche Intelligenz Definition.
Eine Künstliche Intelligenz Definition mit Humor & eine emergente
“If it looks like a duck and quacks like a duck but it needs batteries, you probably have the wrong abstraction”
Dieses kleine Bonmot nimmt den „Humanozentrismus“ einiger KI-Forschung bzw. deren Orientierung auf die Schippe. Nur weil es bisher niemand außer dem Menschen zu Intelligenz geschafft hat heißt das nicht, dass wir KI automatisch an ihr orientieren müssen.
„Künstliche Intelligenz ist das emergente Verhalten hinreichend komplexer Systeme„
Diesen Ansatz finde ich sehr spannend. Denn er ist anders als alle bisherigen und geht doch in eine ähnliche Richtung.
Emergenz habe ich eingangs ja schon erläutert. Aber die drastische Veränderung des Verhaltens von Einzelteilen wenn genügend von Ihnen zusammenkommen ist im Kontext von künstlicher Intelligenz außerordentlich spannend.
Denn während es oftmals heißt „Genug Speicher, genug Rechenleistung, bessere Algorithmen und mehr neuronale Netze und wir knacken AGI früher oder später“, geht dieser Ansatz noch ein wenig anders vor. Und zwar a la genügend „schwache“ künstliche Intelligenzen vereint erzeugen eine „starke“ künstliche Intelligenz.
Mit menschlicher Intelligenz geht dies ja schon.
Unanimous geht zum Beispiel in eine solche Richtung, wenn auch ganz anders umgesetzt, als du es dir jetzt wahrscheinlich vorgestellt hast.
In anderen Worten: künstliche Intelligenz ist das, was passiert, wenn ein System genügend Komponenten hat. Weshalb einige Physiker es für möglich halten, dass das Internet irgendwann ein Bewusstsein entwickelt. Was ja auch eine künstliche Intelligenz wäre, wenn auch anders, als gedacht.
Künstliche Intelligenz definiert: Fazit
Das soll es fürs Erste mit Ansätzen für eine künstliche Intelligenz Definition gewesen sein. Wahrscheinlich raucht dir jetzt auch schon ein wenig der Kopf. (Meiner tut es nach diesen vielen Zeilen und Ansätzen jedenfalls)
Oder, wie es dieser Artikel zusammenfasst, welcher ebenfalls einige gebräuchliche Ansätze miteinander vergleicht:
„All the definitions above are correct, but what it really boils down to is “how close or how well a computer can imitate or go beyond, when compared to human being”“
Zum Abschluss nochmal die gängigsten Vektoren auf einen Blick:
Die perfekte künstliche Intelligenz Definition enthält wahrscheinlich die Wörter:
- „Methoden und Verfahren“
- Menschen / Tiere / Kreaturen
- Turing Test
- Computer
- Imitation / Simulation
- Denken
- Intelligenz
- Problem(e)
- Lösung(en) / Ziele / Erfolg
- Information(en)
- Verarbeitung
- Autonomie
- Akteure / Agenten
- Technologie / System(e)
- Aufgaben
- (Maschinelles) Lernen
- Algorithmus
- Automatisiert / Automatisch
- Emergenz
- Werkzeug(e)
- Vergleich(bar)
- Reaktion / Adaption
- Software / Informatik
- Input / Output
Wenn du das Ganze handlich zum Bingo-Spielen mit deinen Freunden nutzen willst, findest du hier die deutsche und hier die englische Version meines „künstliche Intelligenz Definitions-Bingos. Viel Freude!
Welche ist nun aber die eine? Ich schätze die einzig richtige künstliche Intelligenz Definition ist die, welche eine starke künstliche Intelligenz am Ende tatsächlich auf die Welt bringt.
Wie siehst du das? Wie definierst du KI? Und gibt es Definitionsansätze, die ich vielleicht übersehen habe?
Schreib‘ mir deine Gedanken gern in die Kommentare, ich bin gespannt!


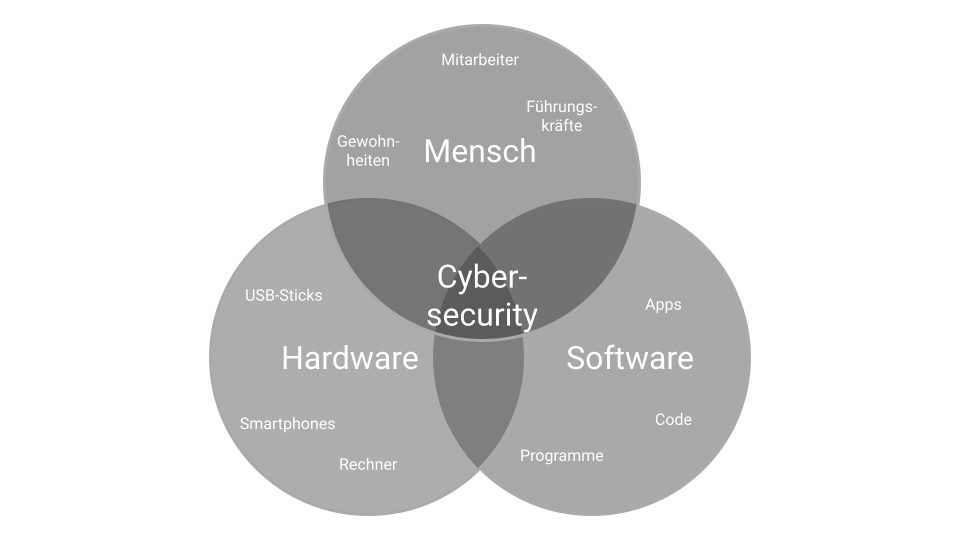

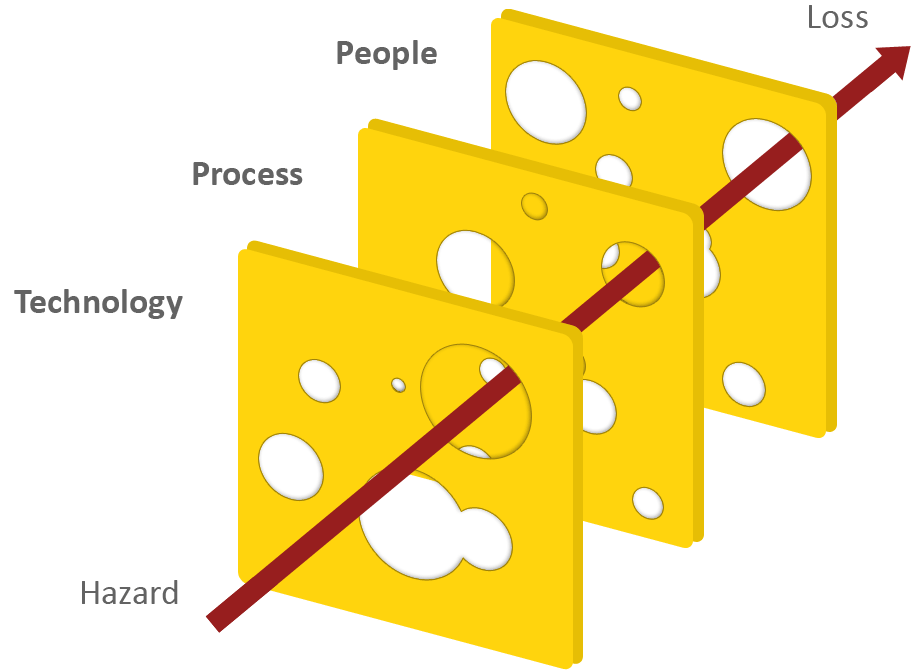
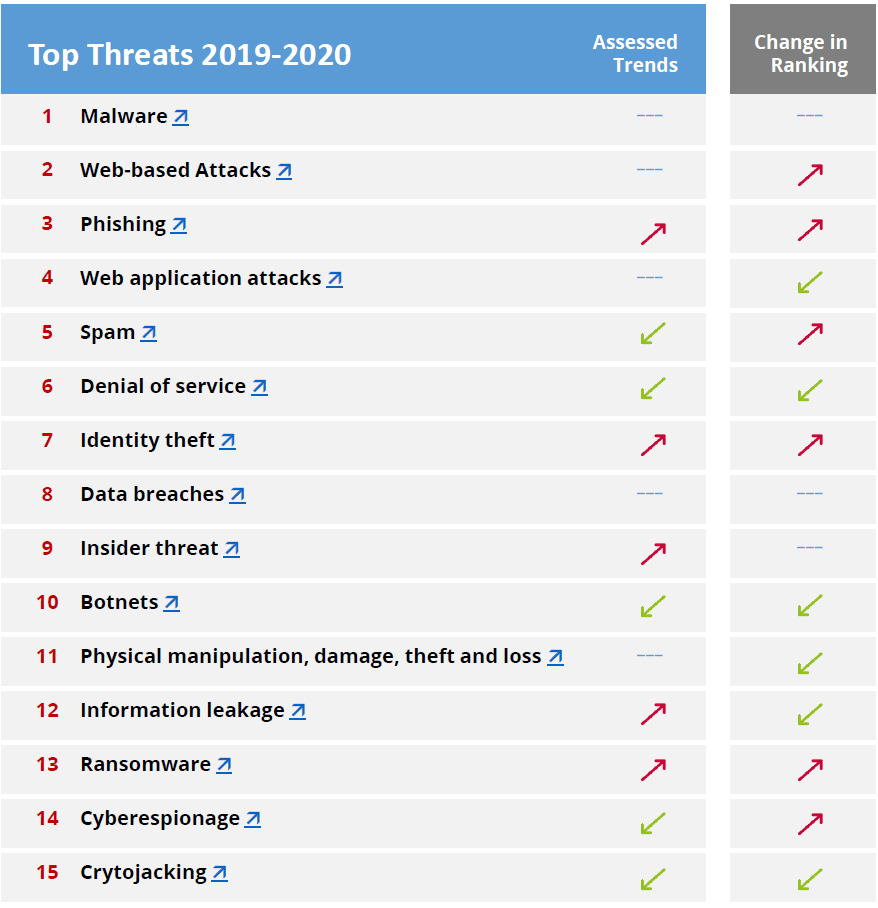



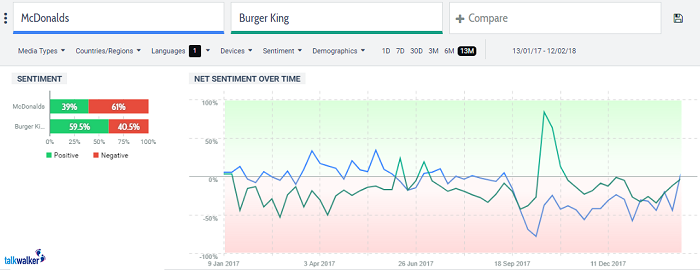
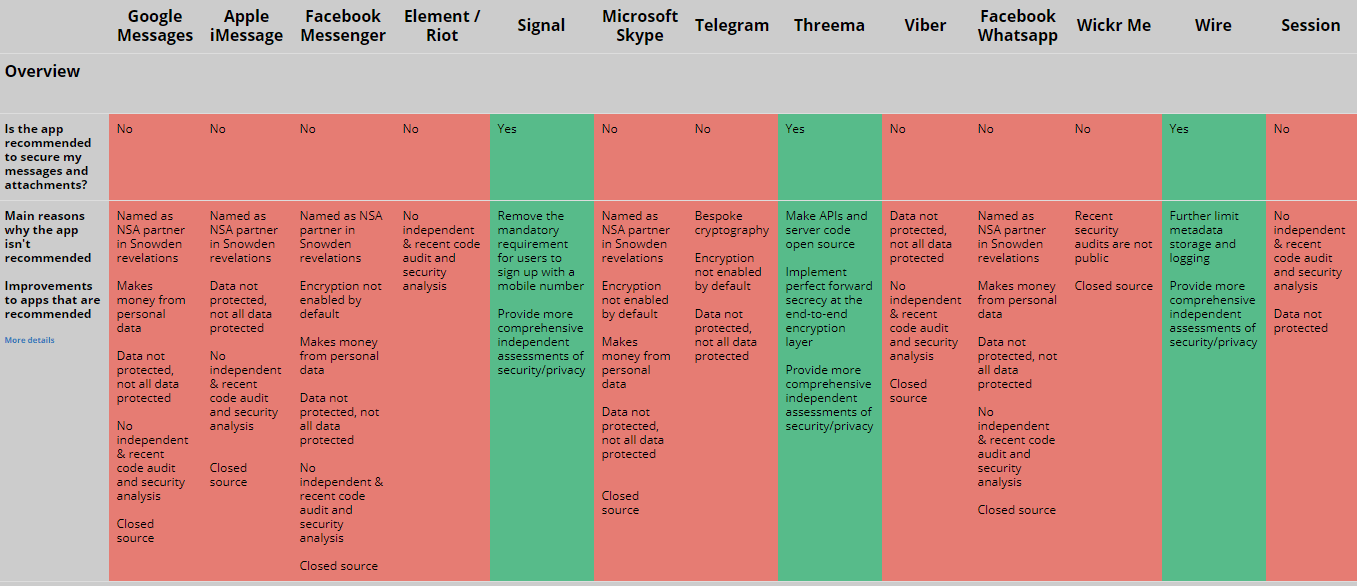
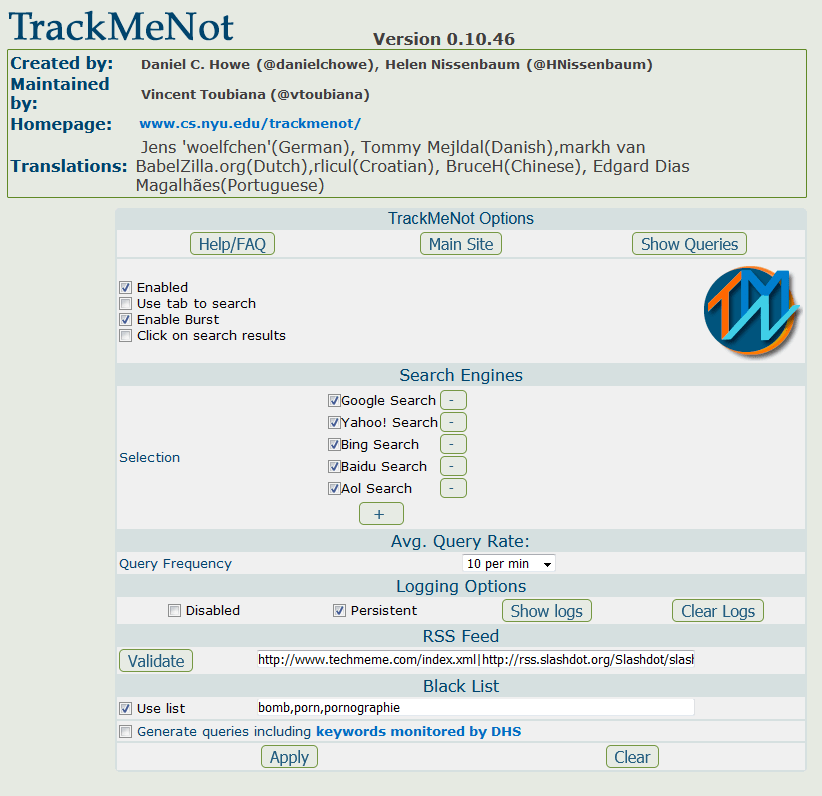
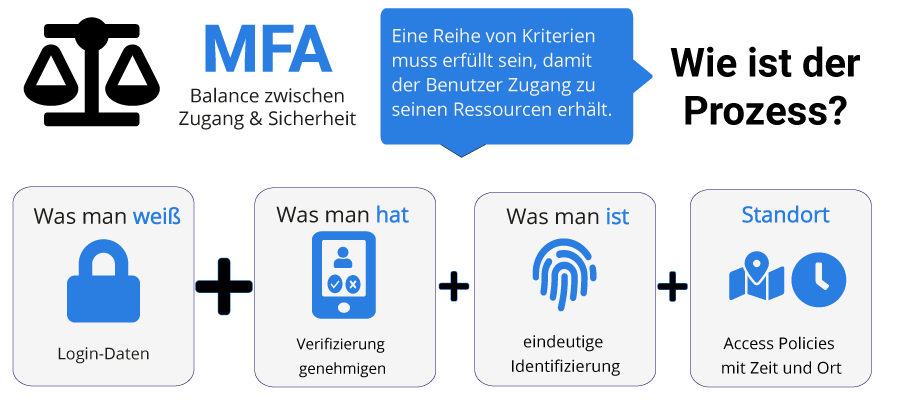









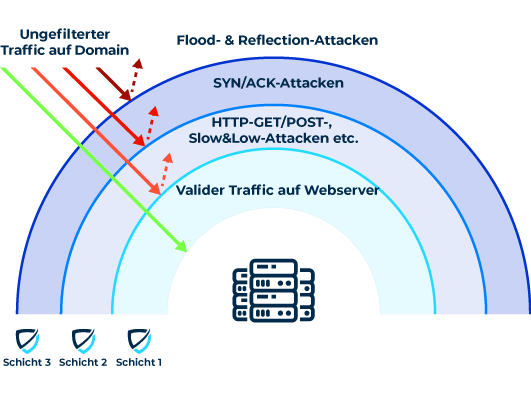

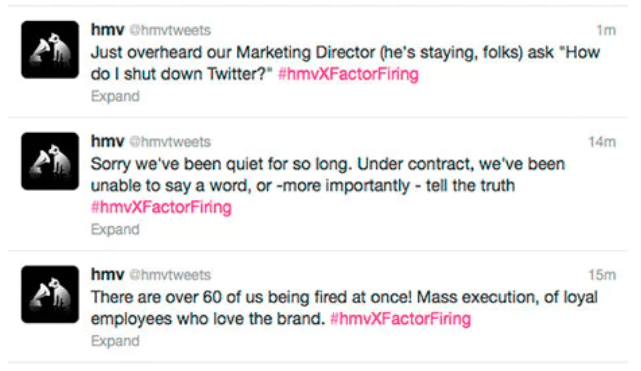
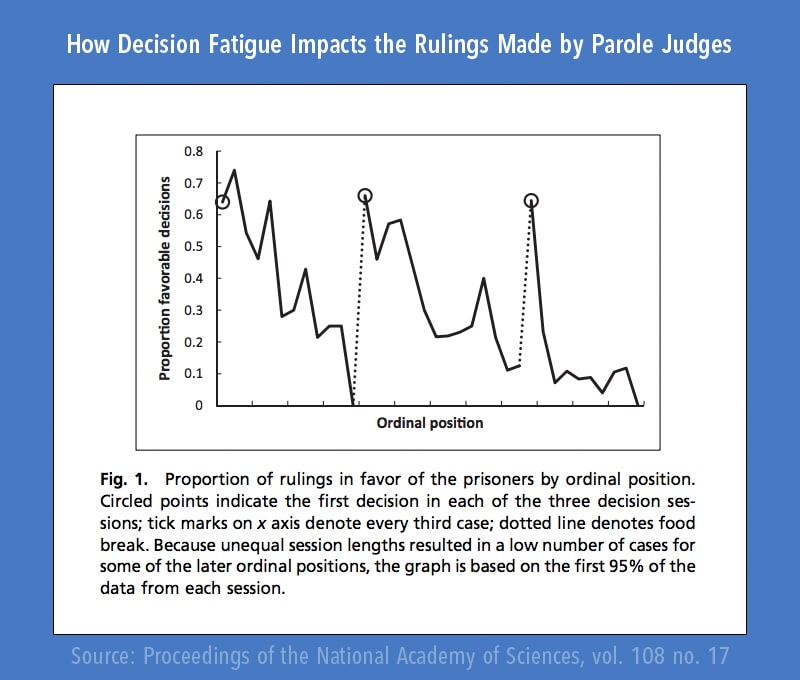

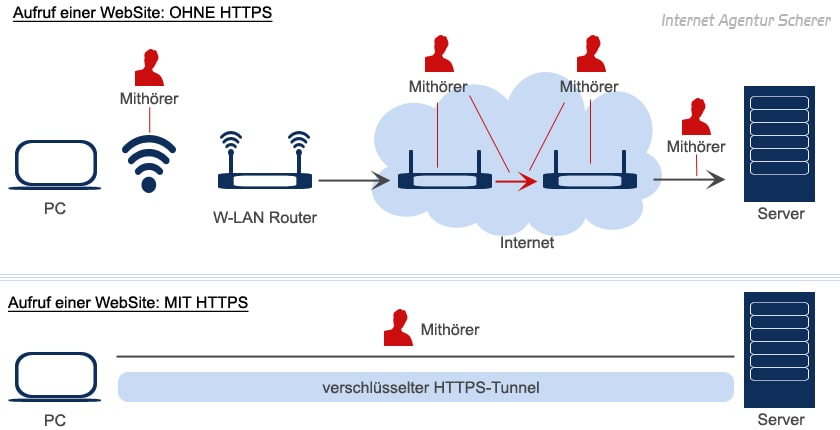




















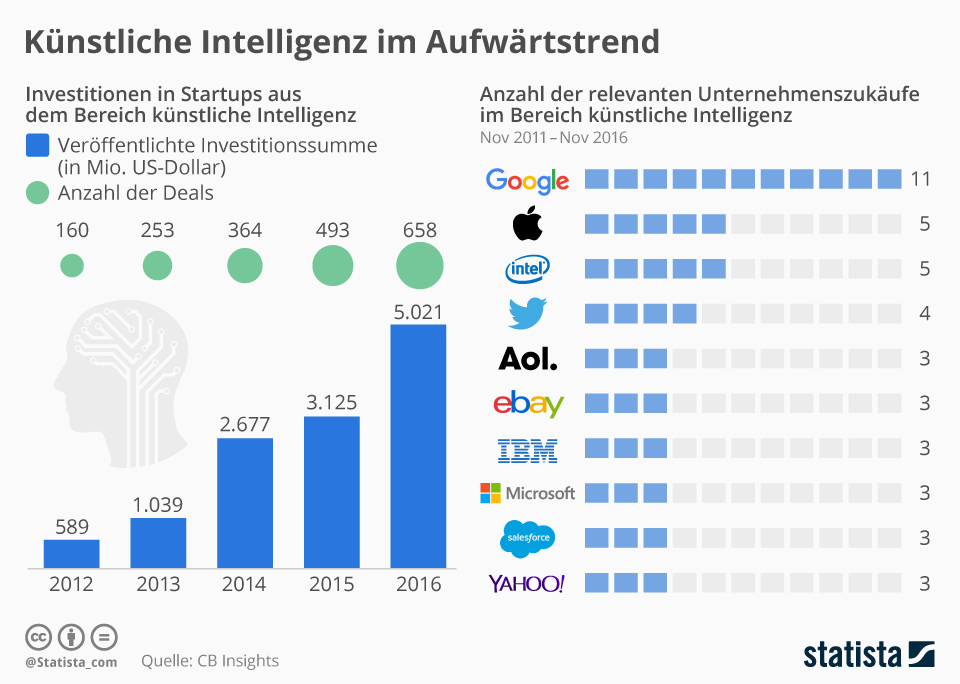
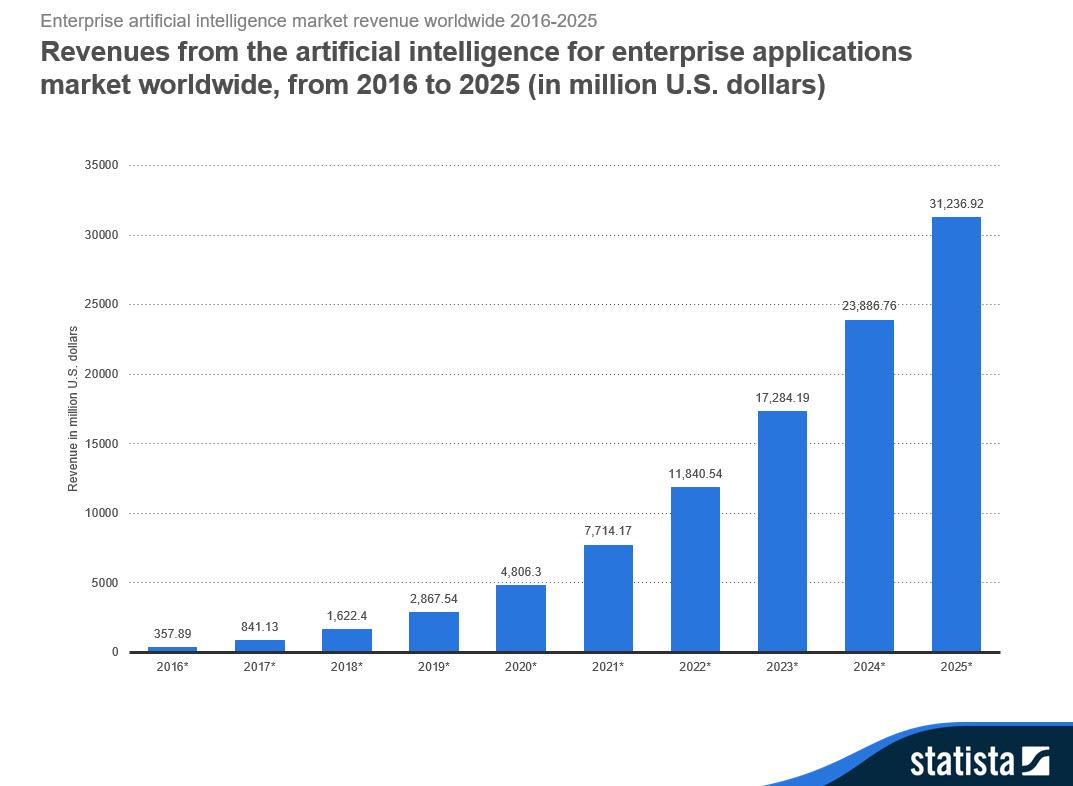
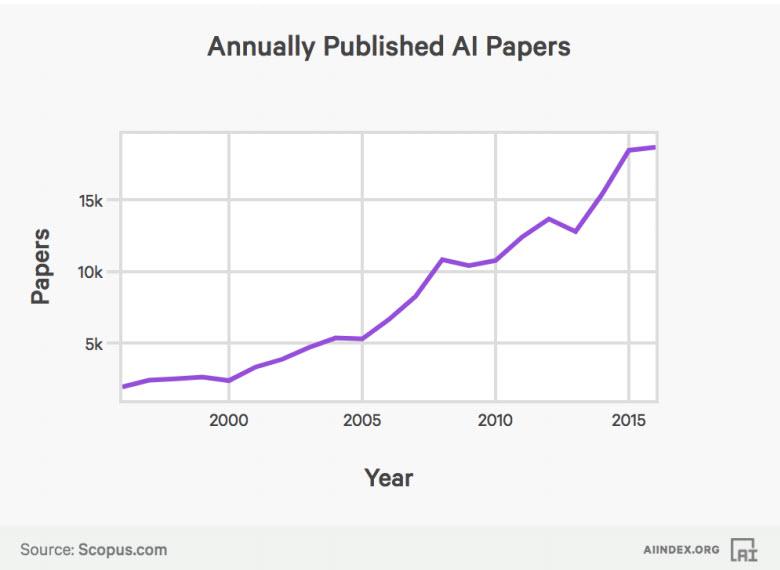
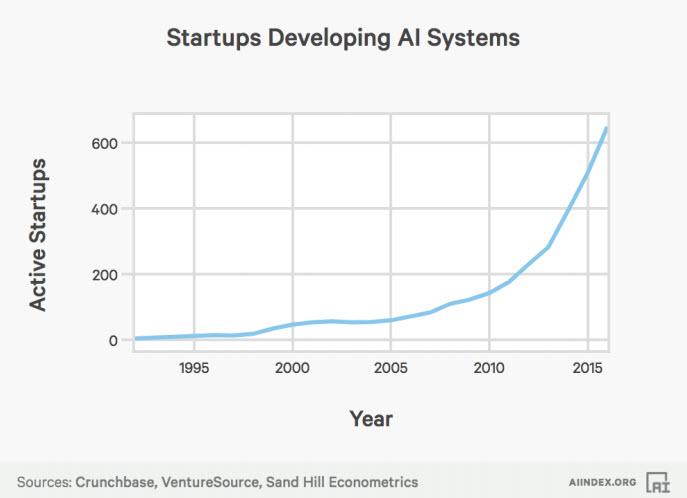
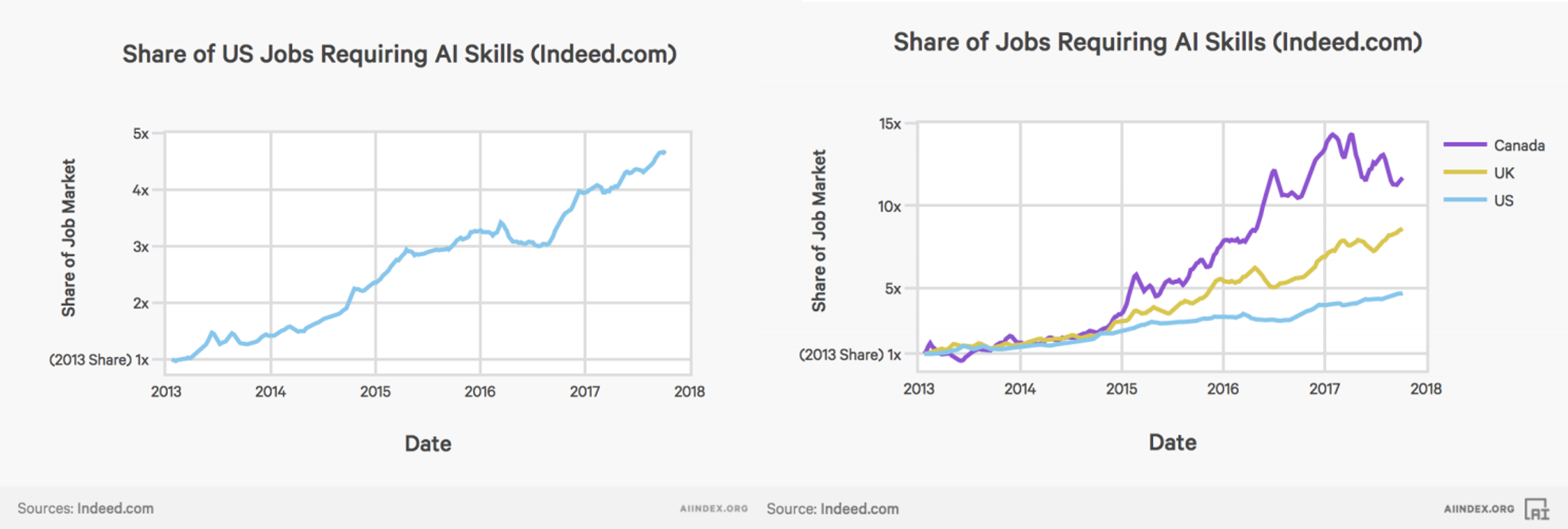


 also? Weiß jeder der damit zu tun bekommt also nach einem kurzen Post-It auf seinem Schreibtisch
also? Weiß jeder der damit zu tun bekommt also nach einem kurzen Post-It auf seinem Schreibtisch